







为了做好运维面试路上的助攻手,特整理了上百道 【运维技术栈面试题集锦】 ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。

本份面试集锦涵盖了
- 174 道运维工程师面试题
- 128道k8s面试题
- 108道shell脚本面试题
- 200道Linux面试题
- 51道docker面试题
- 35道Jenkis面试题
- 78道MongoDB面试题
- 17道ansible面试题
- 60道dubbo面试题
- 53道kafka面试
- 18道mysql面试题
- 40道nginx面试题
- 77道redis面试题
- 28道zookeeper
总计 1000+ 道面试题, 内容 又全含金量又高
- 174道运维工程师面试题
1、什么是运维?
2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
3、现在给你三百台服务器,你怎么对他们进行管理?
4、简述raid0 raid1raid5二种工作模式的工作原理及特点
5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
`为什么是3057?`
因为用户态虚拟内存地址空间是3G,3057大概就是3G。
可见malloc时是在虚拟地址空间申请的,由于代码里并没有对申请的地址进行访问,所以实际上是不会分配物理内存的,直到对地址进行访问,由于缺页中断才开始处理页表映射,然后分配物理内存。
`那如果有对地址进行访问,能够分到多少内存呢?`
这就取决于Linux的内核参数和目前剩余的内存了!!!!
---
#### `请描述一下mmap函数的使用`
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
int munmap(void *addr, size_t length);
* `addr:`用于指定映射到进程地址空间的起始地址,为了应用程序的可以执行,一般都设置为NULL,让内核来选择一个合适的地址。
* `length:`表示映射到进程地址空间的大小
* `prot:`用于设置内存映射区域的读写属性等
* `flags:`用于设置内存映射的属性,例如共享映射、私有映射等
* `fd:`表示这是一个文件映射
* `offset:`在文件映射时,表示文件的偏移量
---
#### `私有映射和共享映射有什么区别?`
**答:** 如果是共享映射,那么在内存中对文件进行修改,磁盘中对应的文件也会被修改,相反,磁盘中的文件有了修改,内存中的文件也被修改。如果是私有映射,那么内存中的文件是独立的,二者进行修改都不会对对方造成影响。通过这样的内存共享映射就相当于是进程直接对磁盘中的文件进行读写操作一样,那么如果有两个进程来mmap同一个文件,就实现了进程间的通信。
---
#### `在一个播放系统中同时打开几十个不同的高清视频文件,发现播放有些卡顿,打开视频文件是用mmap函数,请简单分析原因`
**答:** 使用mmap来创建文件映射时,由于只建立了进程地址空间VMA,并没有马上分配page cache和建立映射关系。因此当播放器真正读取文件时,产生了缺页中断才去读取文件内容到page cache中。这样每次播放器真正读取文件时,会频繁地发生缺页中断,然后从文件中读取磁盘内容到page cache中,导致磁盘读性能比较差,从而造成播放视频的卡顿。对于这个问题,能够有效提高流,媒体服务I/O性能的方法是**增大内核的默认预读窗口**, 可以通过“blockdev --setra”命令来修改。
---
#### `9、Linux是如何避免内存碎片的?`
**答:** 使用`伙伴系统算法`来避免外部碎片,用`slab算法`来避免内部碎片
* **内部碎片**:内部碎片就是已经被分配出去的,能明确指出属于哪个进程,缺不能被利用的内存空间(`这个内存块被某一个进程占有,但是这个进程却不用它,然后别的进程也用不了它,这个内存块就被称为内部碎片`)
* **外部碎片**:外部碎片是指还没被分配出去,但是由于内存块太小了,无法分配给申请内存的进程。
---
#### `10、伙伴系统算法是怎么实现的?它和slab算法有什么区别?`
**答:** 伙伴系统中包含了多条内存链表,每条链表中的包含了多个内存大小相等的内存块(比如4KB链表,代表这台链表中所有的内存块大小都是4KB),比如我们想要分配一个8KB大小的内存,但是发现对应大小的链表上已经没有空闲内存块, 那么伙伴系统就会从16KB的链表中找到一个空闲内存块,然后分成两个8KB的大小,把其中一个返回给申请者使用,另一块放到8KB对应的链表中进行管理。到这里可能有童靴会有疑问:`如果我只需要1KB甚至更小的内存,而伙伴系统链表中只有32KB的链表有空闲块了,那岂不是要切很久?`
对于进程描述符这些对象大小比较小的,如果直接采用伙伴系统进行分配和释放,不仅会造成大量的内存碎片,并且在处理速度上也会比较慢,`slab机制`的工作就是针对一些 **`经常分配并释放的对象`**,它是基于对象进行管理的,**`相同类型的对象归为一类`** , 每次要申请这样一个对象,slab分配器就从一个slab列表中分配一个这样的大小出去,而当要释放时,将其重新保存到该列表中,**`而不是直接返回给伙伴系统`** 。**注意:slab分配器最终还是由伙伴系统来分配物理页面的**
---
#### `Linux内核使用伙伴系统管理内存,那么在伙伴系统工作前,如何管理内存?`
**答:** `memblock`,`memblock`在系统启动阶段进行简单的内存管理,记录物理内存的使用情况
---
#### `在系统启动的时候,Linux内核如何知道内存多大?`
**答:** 在对应的平台DTS文件中都会配置memory的节点,描述内存信息,在系统启动的时候,会去解析DTS中配置的memory节点,从而获得内存信息。
memory {
device_type = “memory”;
reg = <0 0x40000000 0 0x20000000>;
};
---
#### `物理内存是如何添加到伙伴系统中的?`
**答:**
---
#### `内核空间的页表存放在什么地方?`
---
#### `页表是如何映射的?`
---
#### `zone`
1、系统在启动过程中,解析DTS中的memory节点,获取物理内存信息,并添加到memblock子系统中
2、对页表进行初始化
3、页表初始化完成后,Linux内核就可以开始对物理内存进行管理
4、Linux内核是通过zone来对物理内存进行管理,在Linux内核中,将物理内存分成几个zone来进行管理
---
#### `11、什么是缺页中断?发生缺页中断后的处理流程是怎么样的?`
我们知道用户空间存在虚拟内存,而用户进程访问虚拟内存的时候,正常情况下,虚拟内存和物理内存需要建立映射关系,用户才可以进一步去访问对应的物理内存,**而当进程去访问那些还没有建立映射关系的虚拟内存时,CPU就会触发一个`缺页中断异常`**。
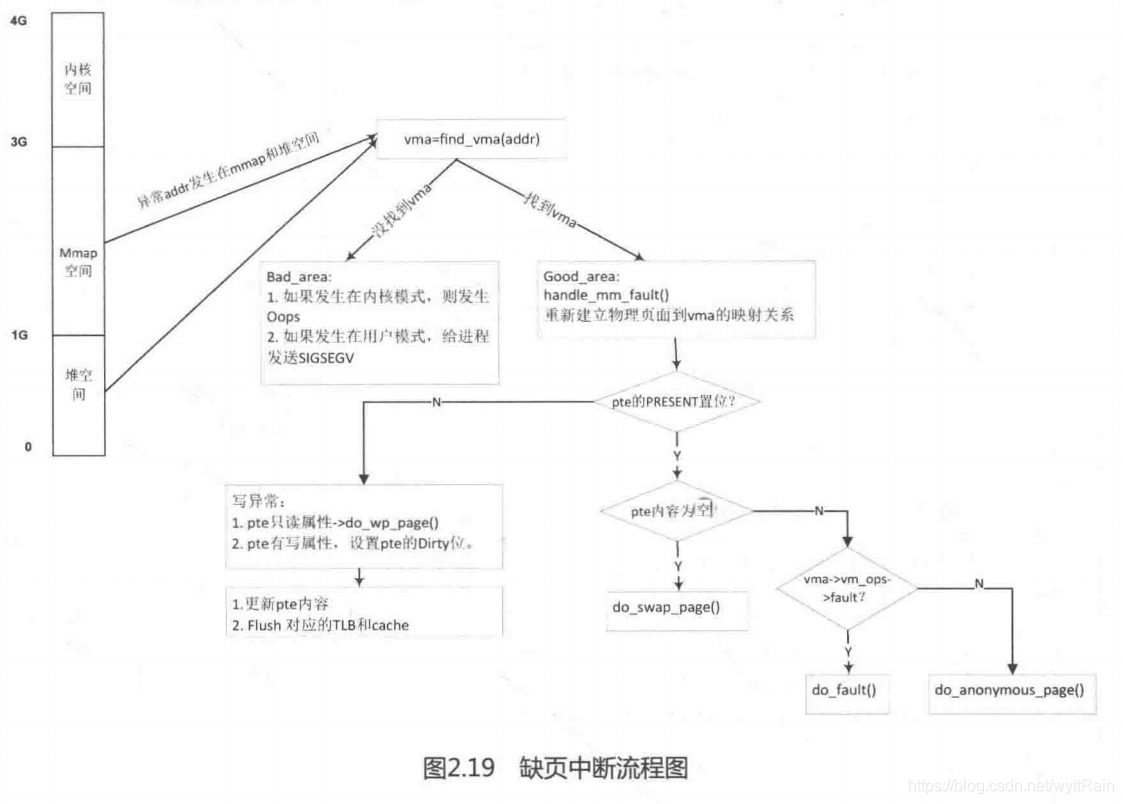
---
#### `缺页中断有哪几种类型?`
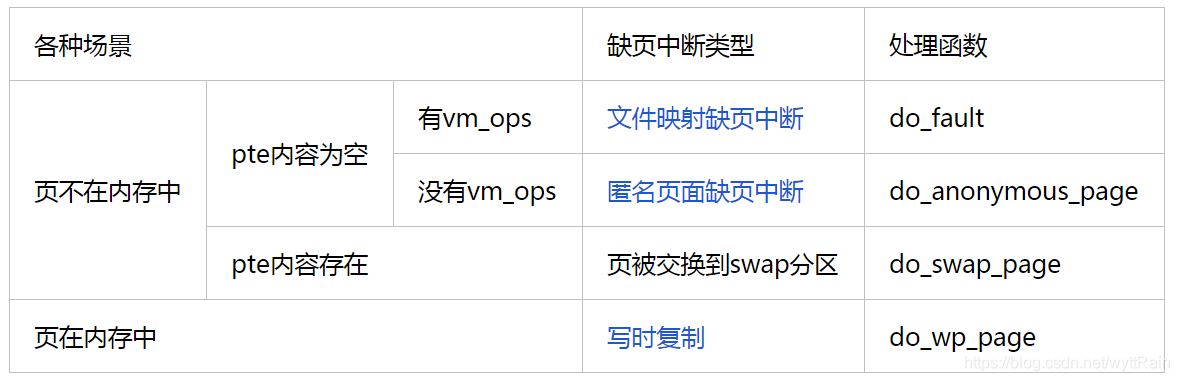
---
#### `12、如果在中断处理函数中出现了缺页中断,会发生什么?`
---
#### `13、Linux内存管理中的分配掩码有什么作用?有哪几个类型?`
`分配掩码(gfp_mask)`是一个决定内存分配动作的参数,主要分成下面五类:
* `内存管理区修饰符`:主要决定需要从哪个内存管理区中分配内存,存管理区修饰符使用gfp\_mask的最低4个比特位来表示
* `移动修饰符`:用来指示分配出来的页面具有的移动属性
* `水位修饰符`:用来控制是否可以使用系统紧急预留的内存

* `页面回收描述符`
* `行动修饰符`
**关于`gfp_mask`更加详细的介绍可以看这个[链接](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
### 三、Linux中断机制
**想进一步整体了解学习Linux中断机制的朋友可以看这个[`链接`](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
ARM处理器中,检测外部硬件中断的任务是由ARM中的中断控制器来检测的。而如果要进一步细分,中断控制器一般分为两个部分,一个是仲裁单元,另一个是CPU Interface模块,所以第一句话可以进一步完善:ARM处理器中,检测外部硬件中断的任务是由ARM中的中断控制器中的仲裁单元来检测的,由中断控制器中的CPU Interface模块来将中断分配给某一个CPU。
#### `1、当发生一个外设中断时,ARM处理器的处理步骤是怎么样的(不涉及下半部的操作)?`
当发生一个外设中断后
* **`a:`** 一个中断M产生,发生了电平变化,被中断控制器中的仲裁单元检测到了(`仲裁单元检测中断信号`)
* **`b:`** 然后仲裁单元会把这个中断M的状态设置为pending(等待状态)(`仲裁单元将中断信号设置为pending状态`)
* **`c:`** 然后过了一段时间后,中断控制器中的CPU Interface模块会把nFIQCPU[n]信号拉低,目的是向CPU报告中断请求,然后将中断M的硬件中断号存放到GICC\_IAR寄存器中(`CPU Interface向CPU报告中断请求`)
* **`d:`** 如果这个时候有一个更高优先级的中断N来了,由于中断控制器支持优先级抢占功能,所以这个时候N会变成当前CPU所有pending状态下优先级最高的中断(意味着它会被优先分配)。(`发生中断抢占`)
* **`e:`** 然后跟步骤c一样,过了一段时间后,CPU Interface模块会再次去把nFIQCPU[n]信号拉低,由于这个时候nFIQCPU[n]已经是低电平了,所以只需要更新GICC\_IAR寄存器的值为中断N的硬件中断号(`设置新的优先级较高的中断信号`)
* **`f:`** 然后CPU就会去读取GICC\_IAR寄存器,把寄存器中的硬件中断号读出来,也就相当于是响应中断了。这个时候仲裁单元就会把中断N的状态从pending变成了activce and pending。(`响应中断信号`)
* **`g:`** 然后后面就是Linux内核处理中断N的中断服务程序了(`处理中断`)
* **`h:`** 在Linux中断处理中断N的过程中,CPU Interface模块会重新拉高nFIQCPU[n]信号,当中断N处理完成后,会将N的硬件中断号写入到GICC\_EOIR寄存器中,表示完成中断N的全部处理过程。
* **`i:`** 然后中断控制器的仲裁单元,会重新选择该CPU下pending状态的中断中优先级最高的一个,发送该中断请求给CPU Interface模块,继续前面的流程。
#### `2、中断发生后的硬件处理和软件处理`
**硬件处理: CPU核心在感知到中断发生后,硬件会自动做如下一些事情**
* 保存中断发生时CPSR寄存器的内容到SPSR\_irq寄存器中
* 修改CPSR寄存器,让CPU进入处理器模式中的IRQ模式
* 硬件自动关闭中断
* 保存返回地址到LR\_irq中
* 硬件自动跳转到中断向量表的IRQ向量中
**软件处理:软件需要做的事情从中断向量表开始**
#### `3、何为中断上下文?为什么中断上下文中不能调用含有睡眠的函数?`
**当CPU响应一个中断并正在执行中断服务程序,那么内核处于中断上下文中。**
当ARM处理器响应中断时,ARM处理器会自动保存终端店的CPSR寄存器和LR寄存器内容,并关闭本地中断,进入IRQ模式。
但在Linux内核中,ARM IRQ模式很短暂(中断上半部执行非常快),很快就退出IRQ模式进入SVC模式,并且把IRQ模式的栈内容负责到SVC模式的栈中,保存中断现场,**也就是说中断上下文运行在SVC模式下。** `既然中断上下文运行在SVC模式下,并且中断现场已经保存在中断打断的进程的内核栈中,为什么中断上下文不能睡眠呢?`
假使现在CPU正在执行一个进程A,这个时候发生了中断,那么中断处理函数会用进程A的内核栈来保存中断上下文。睡眠是什么概念呢?也就是需要调用schedule()函数让当前的进程让出CPU,选择另一个进程继续执行。如果这个时候再发生睡眠或者中断,那么会将中断上下文覆盖了原本进程A的内核栈,当后面这个中断返回的时候,找不到最开始的那个中断的上下文,就再也回不去上一次的中断处理函数中了。
#### `4、硬件中断号和Linux内核的IRQ号是如何映射的?`
#### `5、发生硬件中断后,Linux内核是如何响应并处理中断的?`
#### `6、介绍一下Linux内核中的中断注册函数`
在Linux内核中,注册中断的函数有:`request_irq`和`request_threaded_irq`,这两个函数调用的其实都是`request_threaded_irq`,只是`request_irq`函数的第三个参数传的是NULL(request\_threaded\_irq(irq, handler, NULL, flags, name, dev))
`为什么有了request_irq,还要一个request_threaded_irq?` 我们都知道,当一个中断发生后,需要等待中断处理完成后才会返回到起初的状态继续执行,这样会造成那些对于实时性要求比较高的任务得不到及时的处理,所以引入了`中断线程化`,目的就是将一些工作任务比较繁重的中断处理函数设置成线程看看待,让实时进程能够得到及时的处理。
#### `7、简述一下你对中断上下半部的理解?`
**答:** 我们用一个例子来更好理解中断和中断上下部这两个概念。
`什么是中断?` 比如你现在肚子饿了,然后叫了个外卖,叫完外卖后你肯定不会傻傻坐在那里等电话响,而是会去干其他事情,比如看电视、看书等等,然后等外卖小哥打电话来,你再接听了电话后才会停止看电视或者看书,进而去拿外卖,这就是一个中断过程。你就相当于CPU,而外卖小哥的电话就相当于一个硬件中断。
`什么是中断上下部?` 继续参考上面的例子,比如你现在叫的是两份外卖,一份披萨一份奶茶,由两个不同的外卖小哥配送,当第一个送披萨的外卖小哥打电话来的时候(硬件中断来了),你接起电话,跟他聊起了恋爱心得,越聊越欢,但是在你跟披萨小哥煲电话粥的时候,奶茶外卖小哥打电话来了,发现怎么打也打不进来,干脆就把你的奶茶喝了,这样你就痛失了一杯奶茶,这个就叫做`中断缺失`。所以我们必须保证**中断是快速执行快速结束的**。 那有什么办法可以保护好你的奶茶呢?当你接到披萨小哥的电话后,你跟他说,我知道外卖来了,等我下楼的时候我们面对面吹水,电话先挂了,不然奶茶小哥打不进来,这个就叫做 **`中断上半部处理`**,然后等你下楼见到披萨小哥后,面对面吹水聊天,这个就叫做 **`中断下半部处理`**,这样在你和披萨小哥聊天的过程中,手机也不占线,奶茶小哥打电话过来你就可以接到了。**`所以我们一般在中断上半部处理比较紧急的时间(接披萨小哥的外卖),然后在中断下半部处理执行时间比较长的时间(和披萨小哥聊天),把中断分成上下半部,也可以保证后面的中断过来不会发生中断缺失`**
上半部通常是完成整个中断处理任务中的一小部分,比如硬件中断处理完成时发送EOI信号给中断控制器等,就是在上半部完成的,其他计算时间比较长的数据处理等,这些任务可以放到中断下半部来执行。**Linux内核并没有严格的规则约束究竟什么样的任务应该放到下半部来执行,这是要驱动开发者来决定的。中断任务的划分对系统性能会有比较大的影响。**
`那下半部具体在什么时候执行呢?` 这个没有确定的时间点,一般是从硬件中断返回后的某一个时间点内会被执行。**下半部执行的关键点是允许响应所有的中断,是一个开中断的环境。**
#### `8、什么是软中断?什么是tasklet?什么是工作队列`
`软中断`是预留给系统中对时间要求最为严格和最重要的下半部使用的,而且目前驱动中只有块设备和网络子系统使用了软中断。 软中断指的,其实就是我们上面所描述的中断的下半部的处理程序。一般是以`内核线程`的方式运行。系统静态定义了若干种软中断的类型。**并且Linux内核开发者不希望用户再扩充新的软中断类型,如果需要,建议使用tasklet**
`tasklet`是基于软中断机制的另一种变种,运行在软中断上下文中。
`workqueue`是以内核线程的方式来处理中断下半部事务,是`基于进程上下文`的,而软中断和tasklet是基于中断上下文的,优先级要比进程上下文高,所以当软中断或者tasklet的处理时间太长的话,如果在对于实时性要求较高的进程中发生了中断,那么对于系统性能影响会很大。
### 四、Linux同步机制
#### `1、Linux内核中包含了哪些同步机制?`
**答:** `原子操作`、`自旋锁`、`信号量`、`互斥锁`、`读写锁`、`RCU`和`Per-CPU变量`。
**各个同步机制进一步的介绍可以看这个[链接](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
### 五、Linux进程管理
#### `进程和线程的区别?`
**进程是资源分配的最小单位,线程是程序执行的最小单位**,线程是进程的一个执行单元,是一个比进程要小的独立运行的基本单位,一个程序至少要有一个进程,一个进程至少要有一个线程。更加细致的区别如下:
* `根本区别`:进程是资源分配的最小单位,线程是程序执行的最小单元;
* `地址空间`:进程拥有自己的独立空间,每创建一个进程,系统都会为其分配地址空间;线程没有独立的地址空间,同一个进程内的所有线程共享本进程的地址空间;
* 由于程序执行过程中是执行具体的线程,所以`线程是处理器调度的基本单位`,而进程不是
#### `1、描述进程/线程的结构体`
**`我认为,想要了解和熟悉进程线程,包括它们之间的调度,首先必须要先了解描述它们的结构体`**
#### `Linux内核中有没有进程?`
在Linux内核中,其实是没有进程、线程之分的,它们都是通过task\_struct来描述和调度的
#### `1、Linux中的调度类`
进程调度依赖于调度策略,Linux内核把相同的调度策略抽象成了`调度类`。目前Linux内核中默认实现了五个调度类:`stop`、`deadline`、`realtime`、`CFS`和`idle`。
用户控件可以使用调度策略API函数来设定用户进程的调度策略(比如sched\_setscheduler),其中,SCHED\_NORMAL、SCHED\_BATCH以及SCHED\_IDLE使用完全公平调度器(CFS),SCHED\_FIFO和SCHED\_RR使用realtime调度器,SCHED\_DEADLINE使用deadline调度器。
#### `1、在Linux内核中,使用什么来描述一个进程的所有信息?如何获得当前描述该进程的结构体?`
**答:** 在Linux内核里面采用名为`task_struct`的数据结构来描述一个进程,并且利用链表`task_list`来存放所有的进程描述符。在内核中,有一个常用的变量`current`用来获取当前进程的`task_struct结构`,利用了内核栈的特性。
在Linux 4.0的内核中,内核栈(`内核栈的大小通常和架构相关,ARM32架构的内核栈为8KB,ARM64架构的为16KB`)里存放了`thread_union`数据结构,内核栈的底部存放了`thread_info`数据结构。current()宏首先通过ARM的SP寄存器来获取当前内核栈的地址,对其后可以获取thread\_info数据结构的指针,最后通过`thread_info->task`成员来获取task\_struct数据结构。
在Linux 5.4内核中,**获取当前进程的内核栈的方式已经发生了巨大的变化。** 系统新增了一个配置选项`CONFIG_THREAD_INFO_IN_TASK`,目的是允许把`thread_info`的数据结构直接存放到`task_struct`中。(在ARM64中这个宏是默认打开的)。在ARM64架构中。利用`sp_el0寄存器`来存放`task_struct`数据结构,**`current宏`** 通过`sp_el0`寄存器来获取`task_struct`数据结构。
#### `2、进程可以分成哪几种类型?`
**答:** 进程可以大致分成两种:`I/O消耗型`和`CPU消耗型`
* `I/O消耗型:` 这类进程很少会完全占用时间片。
* `CPU消耗型:`这类进程会完全占用时间片。
#### `3、进程有那几个状态?`
* `创建态`:创建了新进程
* `就绪态`:进程获得了可以运行的所有资源和准备条件
* `运行态`:进程正在CPU中执行
* `阻塞态`:进程因为等待某项资源而被暂时移出CPU
* `终止态`:进程消亡
#### `4、说一下创建进程的函数fork()、vfork()和clone()还有exec()的区别`
**答:** **在Linux内核中,fork()、vfork()、clone()、exec()以及创建内核线程的函数接口都是通过调用\_do\_fork()函数来完成的,只是调用的参数不一样。**
* **`fork():`**如果使用fork()函数来创建子进程,子进程和父进程将 **`拥有各自独立的进程地址空间,但是共享物理内存资源`** 。fork()函数会**返回两次**,一次是在父进程,一次是在子进程。如果返回值是0,说明这是子进程,如果返回值为正数,说明是父进程,父进程会返回子进程的ID,如果返回-1表示创建失败。
* **`vfork():`** 上面介绍的fork()函数尽管使用了写时复制技术,但还是需要复制父进程的页表, 在某些场景下会比较慢,所以就有了后面的`vfork()`和`clone()`。`vfork()`的父进程会一直阻塞,直到子进程调用`exit()`或`execve()`为止。`vfork()`比`fork()`多了两个标志位,`CLONE_VFORK`和`CLONE_VM`,`CLONE_VFORK`表示进程会被挂起,直到子进程释放虚拟内存资源;`CLONE_VM`表示父子进程运行在相同的进程地址空间中。**`vfork()`** 的另一个优势是连父进程的页表项复制动作也被省了。
* **`clone():`** 该函数通常用来创建用户线程。**Linux内核中没有专门的线程,而是把线程当成普通的进程来看待,在内核中还是以task\_struct数据结构来描述。** 该函数的功能强大,可以传递众多参数,可以有选择地继承父进程的资源。
* **`exec():`** 一个进程一旦调用exec类函数,它本身就“死亡”了,系统把代码段替换成新的程序的代码,废弃原有的数据段和堆栈段,并为新程序分配新的数据段与堆栈段,唯一留下的,就是进程号,也就是说,对系统而言,还是同一个进程,不过已经是另一个程序了。
**内核线程其实就是运行在内核地址空间中的进程,它和普通用户进程的区别在与内核线程没有独立的进程地址空间,也就是`task_struct数据结构中的mm指针被设置为NULL。`**
**想进一步了解fork()函数使用的童鞋可以看看这个[链接](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
#### `5、说一下进程创建函数fork()和exec()的区别`
**答:**
**`对于fork():`**
* a、子进程复制父进程的所有进程内存到其内存地址空间中。父、子进程的 “数据段”,“堆栈段”和“代码段”完全相同,即子进程中的每一个字节都和父进程一样。
* b、子进程的当前工作目录、umask掩码值和父进程相同,`fork()`之前父进程 打开的文件描述符,在子进程中同样打开,并且都指向相同的文件表项。
* c、子进程拥有自己的进程ID。
**`对于exec():`**
* a、进程调用`exec()`后,将在同一块进程内存里用一个新程序来代替调用`exec()`的那个进程,新程序代替当前进程映像,当前进程的“数据段”, “堆栈段”和“代码段”背新程序改写。
* b、新程序会保持调用`exec()`进程的ID不变。
* c、调用`exec()`之前打开打开的描述字继续打开
#### `6、请简述一下Linux内核中的写时复制技术`
**答:** 在传统的UNIX操作系统中,创建新进程的时候会复制父进程拥有的所有资源,这样进程的创建就变得很低效。每次创建子进程时都要把父进程的进程地址空间的内容复制到子进程,但是子进程又不一定需要用到这些资源,出现没必要的复制动作,浪费了资源。
现代操作系统都采用 **`写时复制技术(COW)`** 。该技术就是在**父进程创建子进程的时候不需要复制进程地址空间的内容给子进程,`只需要负责父进程的进程地址空间的页表给子进程`**, 这样父子进程就可以共享相同的物理内存了。当父子进程的其中一方需要修改到物理内存时,就会触发 **`写保护的缺页异常`**, 才会把共享页面的内容复制出来,从而让父子进程拥有各自的副本。
#### `7、请简述你对进程调度器的理解?并说明几种经典的Linux内核进程调度器( 包括O(N)和O(1) )的工作原理`
进程调度决定了将哪个进程进行执行,以及执行的时间。操作系统进行合理的进程调度,使得资源得到最大化的利用。而进程调度器,就是来干这样的事的东西,每个不同的进程调度器会使用不同的调度算法,使系统呈现出不同的性能。
* **`多级反馈队列算法`** :
多级反馈队列算法是最早期的一个进程调度算法。它将系统中的进程划分为不同的队列进行管理,相同优先级的进程在同一个队列中,该算法有以下几个原则:
**a**、如果进程A的优先级大于B,则优先选择A;
**b**、如果进程A和进程B同属一个优先级链表(优先级相同),这个时候需要通过轮转调度算法来选择;
**c**、当一个新进程进入调度器,把它放进优先级最高的队列中;
**d**、当一个进程是一个CPU消耗型,需要将优先级降低一级;
**e**、当一个进程是一个I/O消耗型,优先级保持不变(`会产生饥饿和欺骗CPU行为`);
**f**、每隔时间周期S之后,把系统中所有进程的优先级都提到最高级别(`可以解决e原则产生的饥饿问题`);
**g**、当一个进程使用完时间片后,不管它是否在时间片的末尾发生I/O请求,都把它的优先级降一级。
* **`O(n)调度算法`**:
该算法是从就绪队列中比较所有进程的优先级,然后选择一个最高优先级的进程作为下一个的调度对象,每一个进程都有一个固定的时间片,当时间片走完的时候,才会去选择下一个调度进程,这个调度器在选择下一个进程的时候会遍历队列中所有的进程,因此消耗的时间为O(n)。**当就绪队列中的进程很多时,选择下一个就绪进程就会变得很慢,导致系统整体性能下降。**
* **`O(1)调度算法`**:
该算法是基于`多级反馈队列算法`来实现的,所以也是将相同优先级的进程放到同一个队列中进行管理,每个CPU维护一个自己的就绪队列,就绪队列由两个优先级数组组成,分别是活跃优先级数组和过期优先级数组。这里使用位图来定义给定优先级队列中是否有可运行的进程,如果有,则将位图中对应的位置1。**O(1)调度算法在处理某些交互式进程时依然存在问题,对NUMA支持也不完善。**
* **`CFS调度算法`**:
`CFS调度算法采用进程权重值的比重来量化和计算实际运行时间。` CFS调度算法引入了`虚拟时间(vruntime)`和`真实时间(real time)`的概念,CFS调度算法总是优先选择vruntime最小的进程,
#### `8、请简述进程优先级、nice和权重之间的关系`
**答:** nice值小的进程优先级高,权重大;nice值大的进程优先级低,权重小。**内核规定nice值为0的权重值为1024**,其他nice值对应的权重值可以通过查表的方式来获取,内核预先计算好了一个表`sched_prio_to_weight[40]`,表的下表对应nice值[-20~19]。
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
[外链图片转存中…(img-ZV55T1yh-1715324182407)]
[外链图片转存中…(img-gl42PQ44-1715324182408)]
[外链图片转存中…(img-SRSEbRyw-1715324182409)]
[外链图片转存中…(img-DIx9AOFa-1715324182409)]
[外链图片转存中…(img-QeiTnbII-1715324182410)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









