







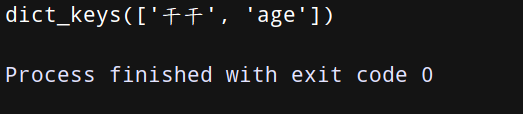
 (3)values 取出所有的值——用法:字典名.values()
(3)values 取出所有的值——用法:字典名.values()
上代码:
a = {‘干干’: 11, ‘age’: 11}
print(a.values())
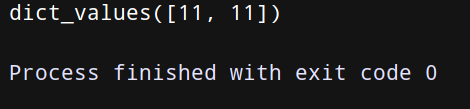
(4) items 取出所有的键值对——用法:字典名.items()
上代码:
a = {‘干干’: 11, ‘age’: 11}
print(a.items())
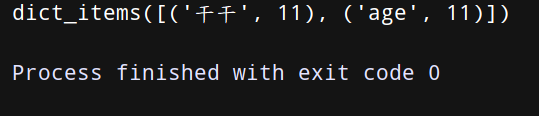
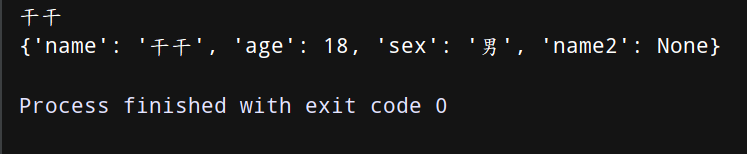
(5)setdefault(key) 有此键则查,无则增!
上代码:
di2 = {‘name’:‘干干’,‘age’:18,‘sex’:‘男’}
print(di2.setdefault(‘name’))
di2.setdefault(‘name2’)
print(di2)
同学们是不是发现——此字典(python程序中的字典)确实非彼字典(《新华字典》),不过确实有那么些共同之处呢!比如:我们查字典的时候,就是查某个字,然后会查出来这个字对应的含义及例词一系列信息;而我们现在用的这个字典,如果我们想要查某个键的值,也是通过查键的方式来显示对应的值呢!大家好好深入思考思考哦!
拓展:如果我们要查某一个键对应的值,而这个键值对在字典中不存在会怎么样呢!
答案显而易见——肯定在执行后会报错,但是我们就是要来看看这会报的什么类型的错!就是倔!!!
dict = {‘线代’: “99”, “数据分析”: “99”, “概率论”: “98”} # 创建字典
print(“dict[‘语文成绩’]:”,dict[‘语文成绩’])

知识补给站:
在python程序中——键是唯一的,但是值可以重复!
①字典中添加数据:
(1)基操勿6!
同学们需要了解的是——在Python程序中,字典是一种动态结构,可以随时在其中添加“键值”对。
具体的在字典中添加数据的操作是:
首先指定字典名,然后用中括号将键括起来,最后写明这个键的值。
我们使用此方法给我们的小红同学的数学和英语成绩也添加上去:
dict = {‘线代’: “99”, “数据分析”: “99”, “概率论”: “98”} # 创建字典
dict[‘数学’] = 100 # 添加字典1
dict[‘英语’] = 99 # 添加字典2
print(dict) # 输出字典dict中的值
print(‘小红同学的数学成绩是:’,dict[‘数学’]) # 显示数学成绩

注意注意注意:
“键值”对的排列顺序与添加顺序不同。因为python不关心键值对的添加顺序,而只关心键和值之间的关联关系!!!
②修改字典:
(1)基操勿6!
**首先指定字典名,然后使用中括号把要修改的键和新值对应起来。**眼睛亮的同学是不是发现这和字典中添加数据好像一样呢!其实可以很肯定的告诉大家,确实是完全一模一样的,所以可以总结出一句顺口溜:有这个键则修改,无则添加!
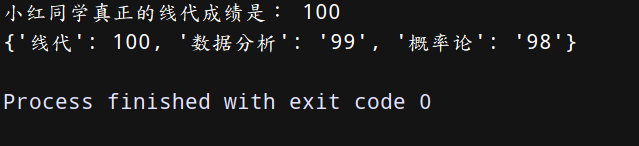
老师突然发现——我在给小红同学批改线代试卷的时候有个地方批改错了,她应该是100分的,所以我们现在要来修改字典中小红的线代成绩为100分。上代码:
dict = {‘线代’: “99”, “数据分析”: “99”, “概率论”: “98”} # 创建字典
dict[‘线代’] = 100
print(‘小红同学真正的线代成绩是:’,dict[‘线代’])
print(dict)
(2)项目常用!
** update 更新字典、将原字典和新字典整合,key重复的话则新的覆盖老的!**
上代码:
dict = {‘name’:‘干干’,‘age’:18,‘sex’:‘男’}
dict.update({‘height’: 195, ‘age’: 20})
print(dict)

③删除字典中的数据:
(1)基操勿6!
在Python程序中,对于字典中不再需要的信息,可以使用del语句将相应的“键值”对信息彻底删除。
具体操作:
在使用del语句删除字典中数据时,必须指定字典名和要删除的键。
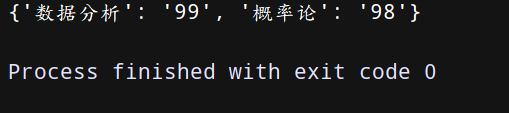
现在我们不需要统计小红同学的线代成绩了,看看我如何将这个键值对删除。上代码:
dict = {‘线代’: “99”, “数据分析”: “99”, “概率论”: “98”} # 创建字典
del dict[‘线代’] # 删除键 ‘线代’
print(dict) # 显示字典dict中的元素
(2)项目常用!
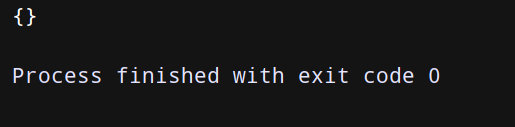
(1)clear 清空字典——用法:字典名.clear()
上代码:
dict = {‘name’:‘干干’,‘age’:18,‘sex’:‘男’}
dict.clear()
print(dict)
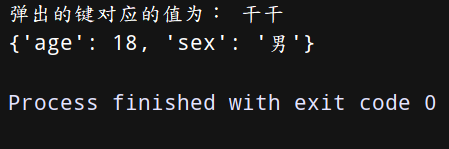
(2) pop 弹出指定key的键值对——用法:字典名.pop(key)
上代码:
dict = {‘name’:‘干干’,‘age’:18,‘sex’:‘男’}
a = dict.pop(‘name’)
print(‘弹出的键对应的值为:’, a)
print(dict)
 (3) popitem 返回并删除字典中的最后一对键和值——用法:字典名.popitem()
(3) popitem 返回并删除字典中的最后一对键和值——用法:字典名.popitem()
上代码:
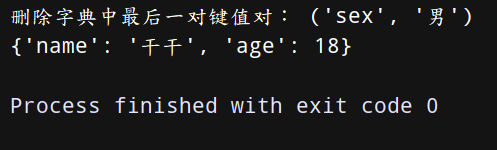
dict = {‘name’:‘干干’,‘age’:18,‘sex’:‘男’}
a = dict.popitem() # #相当于栈出,不过每次出的是一个键值对
print(‘删除字典中最后一对键值对:’,a)
print(dict)
====================================================================================
①一键多值字典
在Python程序中,可以创建将某个键映射到多个值的字典,即一键多值字典[multidict]。
具体操作:
为了能方便地创建映射多个值的字典,可以使用内置模块collections中的defaultdict()函数来实现。(这个函数一个主要特点是当所访问的键不存在的时候,可以实例化一个值作为默认值,也就是说我们在使用这个函数创建字典时就只需要关注添加元素即可。)
比如如下字典d和e就是两种典型的一键多值字典,那么,如何使用defaultdict()函数来实现呢?
d = {
‘a’: [1, 2, 3],
}
e = {
‘a’: {1, 2, 3},
}
上代码:
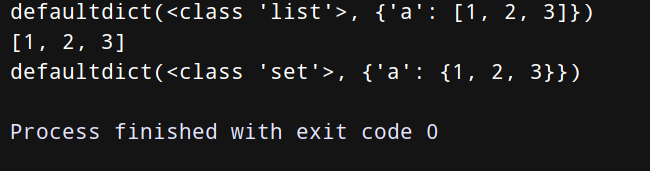
from collections import defaultdict
d = defaultdict(list)
d[‘a’].append(1)
d[‘a’].append(2)
d[‘a’].append(3)
print(d)
print(d[‘a’]) # 字典中的查操作依旧同我们第一小节课讲的那样。
d = defaultdict(set)
d[‘a’].add(1)
d[‘a’].add(2)
d[‘a’].add(3)
print(d)
 但是,我们使用函数defaultdict()会自动创建字典表项以待后面使用。如果不想要这个功能的话,老师现在再教你们一种新的方法:
但是,我们使用函数defaultdict()会自动创建字典表项以待后面使用。如果不想要这个功能的话,老师现在再教你们一种新的方法:
我们可以在普通的字典上调用函数setdefault()来取代此处用的defaultdict()函数。
上代码:
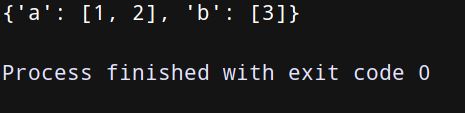
d = {}
d.setdefault(‘a’, []).append(1)
d.setdefault(‘a’, []).append(2)
d.setdefault(‘b’, []).append(3)
print(d)
知识补给站:
dict =defaultdict( factory_function) # defaultdict接受一个工厂函数作为参数
这个factory_function可以是list,str,set,int,作用是当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值(工厂函数的默认值),而这个默认值分别为:list对应[ ],str对应的是空字符串,set对应set( ),int对应0,
from collections import defaultdict
dict1 = defaultdict(int)
dict2 = defaultdict(set)
dict3 = defaultdict(str)
dict4 = defaultdict(list)
dict1[2] = ‘nice’ #无则增!
这样会正常显示dict1字典里key为2对应的value。
print(dict1[2])
我们访问的是通过defaultdict()函数创建的四个字典的key为1对应的值,
但是这个key在这四个字典中都并不存在哦,所以返回相应的默认值!
print(dict1[1])
print(dict2[1])
print(dict3[1])
print(dict4[1])
输出:
nice
0
set()
[]
知识补给站升级:
该函数除了接受类型名称作为初始化函数的参数之外,还可以使用任何不带参数的可调用函数,到时该函数的返回值则作为默认值,这样使得默认值的取值更加灵活。下面用一个例子来说明,如何用自定义的不带参数的函数zero()作为初始化函数的参数:
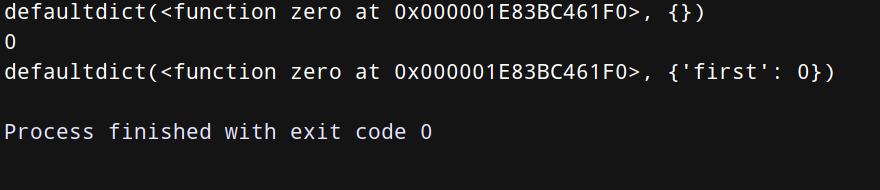
from collections import defaultdict
def zero():
return 0
dict = defaultdict(zero)
print(dict)
print(dict[‘first’])
print(dict)
②获取字典中的最大值和最小值
在Python程序中,我们可以对字典中的数据执行各种数学运算,比如:求最大值,最小值和排序等。为了能对字典中的内容实现有用的计算操作,通过会利用内置函数zip()将字典的键和值反转过来。而对字典中的数据进行排序操作——可以利用函数zip()和sorted()实现。
知识补给站:
函数zip()可以将可迭代对象作为参数,将对象中对应的元素打包成一个元组,然后返回
由这些元组组成的列表。如果各个迭代器的元素个数不一致,则返回的列表长度与最短对
象的相同。利用星号“*”操作符,可以将元组解压为列表
函数zip()语法格式:
zip([iterable,…]
参数:
iterable表示一个或多个迭代器。
项目实战演示如何分别获取字典中最大值和最小值——上代码:
price = {
‘小米’: 899,
‘华为’: 1999,
‘三星’: 3999,
‘谷歌’: 4999,
‘酷派’: 599,
‘iPhone’: 5000,
}
min_price = min(zip(price.values(), price.keys())) # 获取字典中手机价格最小的手机
print(min_price)
max_price = max(zip(price.values(), price.keys())) # 获取字典中手机价格最大的手机
print(max_price)
price_sorted = sorted(zip(price.values(), price.keys())) # 将字典中手机按价格从低到高排序
print(price_sorted)

需要注意的是:
我们使用zip()函数创建的是一个迭代器,所以其产生的数据只能被消耗一次,如果二次使用就会报错!如下:
price = {
‘小米’: 899,
‘华为’: 1999,
‘三星’: 3999,
‘谷歌’: 4999,
‘酷派’: 599,
‘iPhone’: 5000,
}
price_and_names = zip(price.values(), price.keys())
print((min(price_and_names)))
print (max(price_and_names)) # 报错error zip()创建了迭代器,内容只能被消费一次

如果有时候我们的需求是单独获取字典中最大值/最小值的键和值,那么我们又该怎么做呢?
price = {
‘小米’: 899,
‘华为’: 1999,
‘三星’: 3999,
‘谷歌’: 4999,
‘酷派’: 599,
‘iPhone’: 5000,
}
这种直接使用min()和max()函数明显不对哦!这就是按key排序了!
print(min(price))
print(max(price))
print(min(price.values()))
print(max(price.values()))
print(min(price, key=lambda k: price[k]))
print(max(price, key=lambda k: price[k]))

③使用字典推导式
字典推导式和列表推导式的用法类似,只是将列表中的中括号修改为字典中的大括号而已。
项目实战一:使用字典推导式实现合并大小写key!
上代码:
mcase = {‘a’: 10, ‘b’: 34, ‘A’: 7, ‘Z’: 3}
mcase_frequency = {
k.lower(): mcase.get(k.lower(), 0) + mcase.get(k.upper(), 0)
for k in mcase.keys()
if k.lower() in [‘a’,‘b’]
}
print (mcase_frequency)
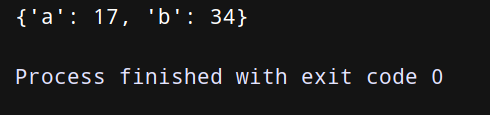
项目实战二:使用字典推导式快速更换字典中key和value的值!
上代码:
dict = {‘a’: 10, ‘b’: 34}
dict_end = {v: k for k, v in dict.items()}
print(dict_end)
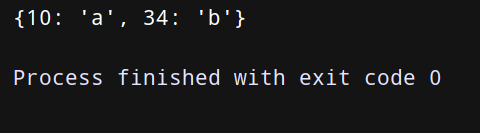
项目实战三:使用字典推导式从字典中提取子集!
上代码:
prices = {‘ASP.NET’: 49.9, ‘Python’: 69.9, ‘Java’: 59.9, ‘C语言’: 45.9, ‘PHP’: 79.9}
p1 = {key: value for key, value in prices.items() if value > 50} # 提取字典prices的子集(value大于50)
print(p1)
tech_names = {‘Python’, ‘Java’, ‘C语言’}
p2 = {key: value for key, value in prices.items() if key in tech_names} # 提取字典prices的子集(key存在在集合tech_names里的)
print(p2)
**需要注意的是:
虽然在python程序中,大部分可以用字典推导式解决的问题也可以通过创建元组序列,然后将它们传给dict()函数来完成,但是使用字典推导式的方案更加清晰,而且实际运行速度也快很多(速度快也是项目选用此方案的原因!),以下面代码为例测试——同学们可以想办法如何显示二者运行速度!**
prices = {‘ASP.NET’: 49.9, ‘Python’: 69.9, ‘Java’: 59.9, ‘C语言’: 45.9, ‘PHP’: 79.9}
tech_names = {‘Python’, ‘Java’, ‘C语言’}
p3 = dict((key, value) for key, value in prices.items() if value > 50) # 慢
print(p3)
p4 = {key: prices[key] for key, value in prices.items() if value > 50} # 慢
print(p4)
④获取两个字典中相同的键值对
如何寻找并获取两个字典中相同的键值对——通过keys()或items()函数执行基本的集合操作即可实现!
知识补给站:
函数keys()
在python字典中,函数keys()返回keys-view对象,其中显示所有的键。字典中的键可以支持常见的集合操作,
例如求并集,交集和差集。所以,如果需要对字典中的键进行常见的集合操作,可以直接使用keys-view对象来实现,而
无须先将它们转换为集合。
函数items()
在Python字典中,函数items()返回由键值对组成的items-view对象。这个对象支持类似的集合操作,可以用于
找出两个字典中有哪些键值对有相同之处。
项目实战——获取两个字典中相同键值对——上代码:
a = {
‘x’: 1,
‘y’: 2,
‘z’: 3
}
b = {
‘x’: 11,
‘y’: 2,
‘w’: 10
}
print(a.keys() & b.keys())
print(a.keys() - b.keys())
print(a.items() & b.items())
c = {key: a[key] for key in a.keys() - {‘z’, ‘w’}} # 使用字典推导式实现,能够修改或过滤掉字典中的内容。
print©

⑤使用函数itemgetter()对字典进行排序
项目需求:如果存在一个字典列表,如何根据一个或多个字典中的值来对列表进行排序?
操作:
使用operator模块中的内置函数itemgetter()。功能:获取对象中指定域的值;参数:一些序号(即需要获取的数据在对象中的序号)
上代码理解:
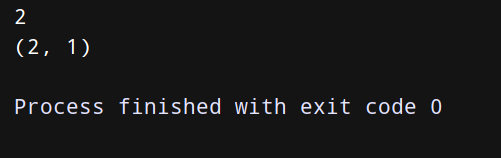
from operator import itemgetter
a = [1,2,3]
b=itemgetter(1) # 获取对象的第1个域的值
print(b(a))
b=itemgetter(1,0) # 获取对象的第1个域和第0个的值
print(b(a))
需要注意的是函数itemgetter()获取的不是值,而是定义一个函数,通过把该函数作用到对象上才能获取值哦!
项目实战——使用函数itemgetter()排序字典中的值!
上代码:
from operator import itemgetter
rows = [
{‘fname’: ‘AAA’, ‘lname’: ‘ZHANG’, ‘uid’: 1001},
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









