







 本文探讨了Python高性能编程的关键要素,如dowser和dis模块的使用,单元测试的注意事项,数据结构对性能的影响,矩阵和矢量计算的优化,编译器的选择,以及密集型任务的处理策略。作者强调了系统化学习和实践经验的重要性,鼓励读者在IT领域共同学习成长。
本文探讨了Python高性能编程的关键要素,如dowser和dis模块的使用,单元测试的注意事项,数据结构对性能的影响,矩阵和矢量计算的优化,编译器的选择,以及密集型任务的处理策略。作者强调了系统化学习和实践经验的重要性,鼓励读者在IT领域共同学习成长。
(6)dowser 工具,通过Web浏览器界面审查一个持续运行的进程中的实时对象。
(7)dis 模块,查看 CPython 的字节码,了解基于栈的 Python 虚拟机如何运行。
(8)单元测试,在性能分析时要避免由优化手段带来的破坏性后果。
作者强调了性能分析的重要性,同时也对如何确保性能分析的成功提了醒,例如,将测试代码与主体代码分离、避免硬件条件的干扰(如在BIOS上禁用了TurboBoost、禁用了操作系统改写SpeedStep、只使用主电源等)、运行实验时禁用后台工具如备份和Dropbox、多次实验、重启并重跑实验来二次验证结果,等等。
性能分析对于高性能编程的作用,就好比复杂度分析对于算法的作用,它本身不是高性能编程的一部分,但却是最终有效的一种评判标准。
2、数据结构的影响
高性能编程最重要的事情是了解数据结构所能提供的性能保证。
高性能编程的很大一部分是了解你查询数据的方式,并选择一个能够迅速响应这个查询的数据结构。
书中主要分析了 4 种数据结构:列表和元组就类似于其它编程语言的数组,主要用于存储具有内在次序的数据;而字典和集合就类似其它编程语言的哈希表/散列集,主要用于存储无序的数据。
本书在介绍相关内容的时候很克制,所介绍的都是些影响“速度更快、开销更低”的内容,例如:内置的 Tim 排序算法、列表的 resize 操作带来的超额分配的开销、元组的内存滞留(intern机制)带来的资源优化、散列函数与嗅探函数的工作原理、散列碰撞带来的麻烦与应对、Python 命名空间的管理,等等。
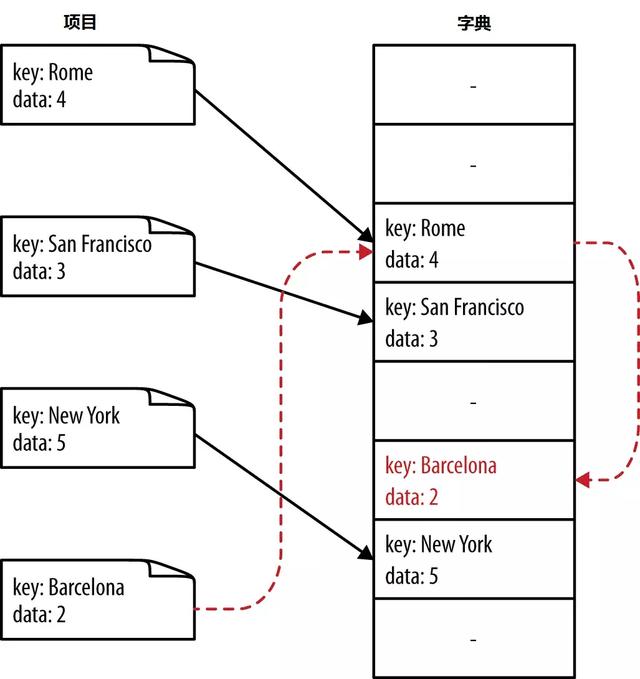
散列碰撞的结果
理解了这些内容,就能更加了解在什么情况下使用什么数据结构,以及如何优化这些数据结构的性能。
另外,关于这 4 种数据结构,书中还得出了一些有趣的结论:对于一个拥有100 000 000个元素的大列表,实际分配的可能是112 500 007个元素;初始化一个列表比初始化一个元组慢5.1 倍;字典或集合默认的最小长度是8(也就是说,即使你只保存3个值,Python仍然会分配 8 个元素)、对于有限大小的字典不存在一个最佳的散列函数。
3、矩阵和矢量计算
矢量计算是计算机工作原理不可或缺的部分,也是在芯片层次上对程序进行加速所必须了解的部分。
然而,原生 Python 并不支持矢量操作,因为 Python 列表存储的不是实际的数据,而是对实际数据的引用。在矢量和矩阵操作时,这种存储结构会造成极大的性能下降。比如,grid5 中的两个数字其实是索引值,程序需要根据索引值进行两次查找,才能获得实际的数据。
同时,因为数据被分片存储,我们只能分别对每一片进行传输,而不是一次性传输整个块,因此,内存传输的开销也很大。
减少瓶颈最好的方法是让代码知道如何分配我们的内存以及如何使用我们的数据进行计算。
Numpy 能够将数据连续存储在内存中并支持数据的矢量操作,在数据处理方面,它是高性能编程的最佳解决方案之一。
Numpy 带来性能提升的关键在于,它使用了高度优化且特殊构建的对象,取代通用的列表结构来处理数组,由此减少了内存碎片;此外,自动矢量化的数学操作使得矩阵计算非常高效。
Numpy 在矢量操作上的缺陷是一次只能处理一个操作。例如,当我们做 A * B + C 这样的矢量操作时,先要等待 A * B 操作完成,并保存数据在一个临时矢量中,然后再将这个新的矢量和 C 相加。
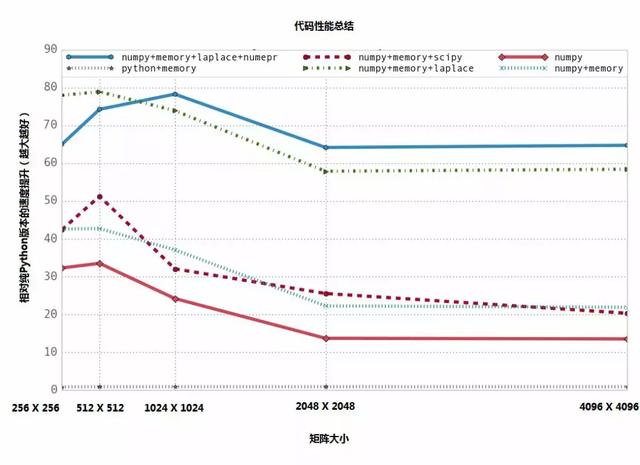
Numexpr 模块可以将矢量表达式编译成非常高效的代码,可以将缓存失效以及临时变量的数量最小化。另外,它还能利用多核 CPU 以及 Intel 芯片专用的指令集来将速度最大化。
书中尝试了多种优化方法的组合,通过详细的分析,展示了高性能编程所能带来的提升效果。
4、编译器
书中提出一个观点:让你的代码运行更快的最简单的办法就是让它做更少的工作。
编译器把代码编译成机器码,是提高性能的关键组成部分。
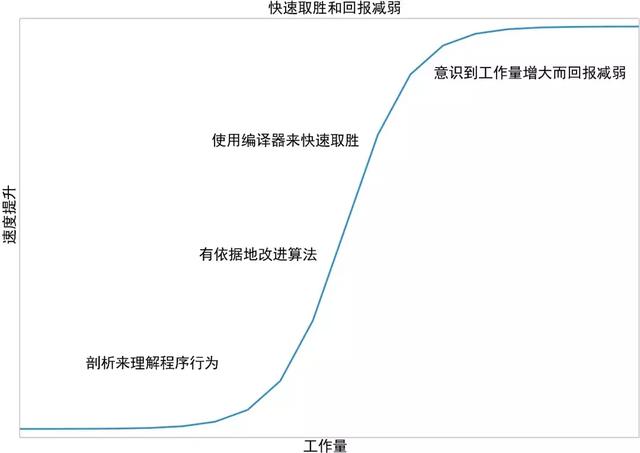
不同的编译器有什么优势呢,它们对于性能提升会带来多少好处呢?书中主要介绍了如下编译工具:
- Cython ——这是编译成C最通用的工具,覆盖了Numpy和普通的Python代码(需要一些C语言的知识)。
- Shed Skin —— 一个用于非Numpy代码的,自动把Python转换成C的转换器。
- Numba —— 一个专用于Numpy的新编译器。
- Pythran —— 一个用于Numpy和非numpy代码的新编译器。
- PyPy —— 一个用于非Numpy代码的,取代常规Python可执行程序的稳定的即时编译器。
书中分析了这几种编译器的工作原理、优化范围、以及适用场景等,是不错的入门介绍。此外,作者还提到了其它的编译工具,如Theano、Parakeet、PyViennaCL、ViennaCL、Nuitka 与 Pyston 等,它们各有取舍,在不同领域提供了支撑之力。
5、密集型任务
高性能编程的一个改进方向是提高密集型任务的处理效率,而这样的任务无非两大类:I/O 密集型与 CPU 密集型。
I/O 密集型任务主要是磁盘读写与网络通信任务,占用较多 I/O 时间,而对 CPU 要求较少;CPU 密集型任务恰恰相反,它们要消耗较多的 CPU 时间,进行大量的复杂的计算,例如计算圆周率与解析视频等。
改善 I/O 密集型任务的技术是异步编程 ,它使得程序在 I/O 阻塞时,并发执行其它任务,并通过“事件循环”机制来管理各项任务的运行时机,从而提升程序的执行效率。
书中介绍了三种异步编程的库:Gevent、Tornado 和 Asyncio,对三种模块的区别做了较多分析。
改善 CPU 密集型任务的主要方法是利用多核 CPU 进行多进程的运算。
Multiprocessing 模块基于进程和基于线程的并行处理,在队列上共享任务,以及在进程间共享数据,是处理CPU密集型任务的重要技术。
书中没有隐瞒它的局限性:Amdahl 定律揭示的优化限度、适应于单机多核而多机则有其它选择、全局解释锁 GIL 的束缚、以及进程间通信(同步数据和检查共享数据)的开销。针对进程间通信问题,书中还分析了多种解决方案,例如 Less Naïve Pool、Manager、Redis、RawValue、MMap 等。
6、集群与现场教训
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 3184
3184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









