







# 设置移动天数
ma_day = [10, 20, 50]
for ma in ma_day:
for company in company_list:
column_name = f"MA for {ma} days"
company[column_name] = company['close'].rolling(ma).mean()
现在继续绘制所有额外的移动平均线。
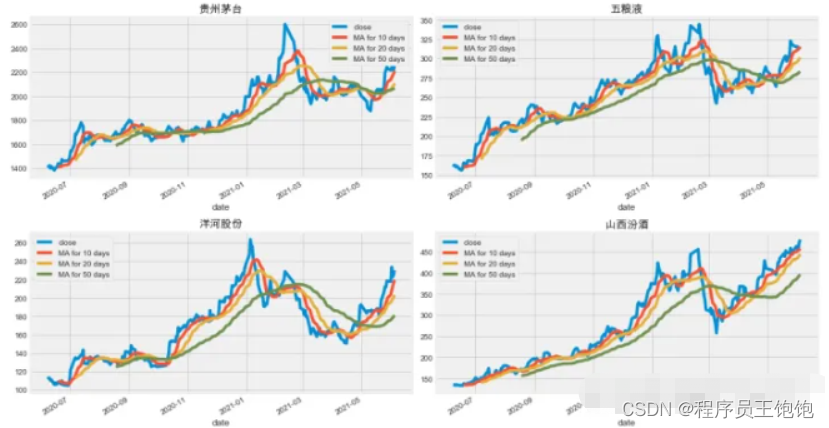
fig, axes = plt.subplots(nrows=2, ncols=2)
fig.set_figheight(8)
fig.set_figwidth(15)
maotai[['close', 'MA for 10 days', 'MA for 20 days', 'MA for 50 days']].plot(ax=axes[0,0])
axes[0,0].set_title('贵州茅台')
wuliangye[['close', 'MA for 10 days',
'MA for 20 days', 'MA for 50 days']
].plot(ax=axes[0,1])
axes[0,1].set_title('五粮液')
yanghe[['close', 'MA for 10 days',
'MA for 20 days', 'MA for 50 days']
].plot(ax=axes[1,0])
axes[1,0].set_title('洋河股份')
fenjiu[['close', 'MA for 10 days',
'MA for 20 days', 'MA for 50 days']
].plot(ax=axes[1,1])
axes[1,1].set_title('山西汾酒')
fig.tight_layout()
股票的平均日回报率是多少?
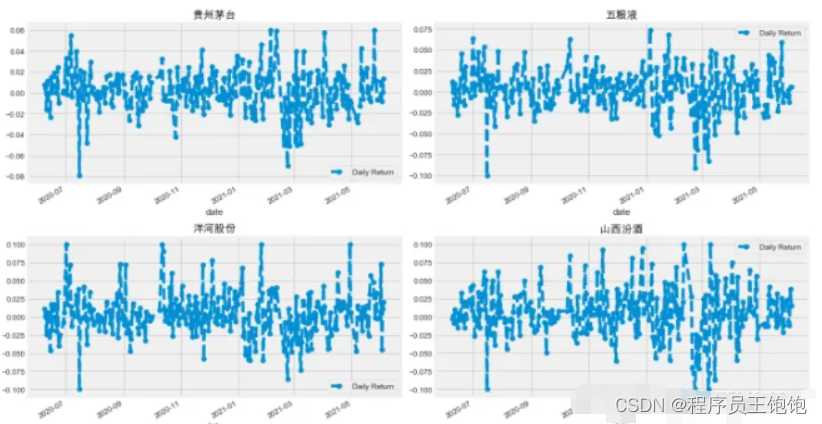
现在我们已经完成了一些基本分析,现在进一步深入研究。现在我们来分析一下股票的风险。这里需要仔细观察股票的每日变化趋势。使用pct_change来查找每天的百分比变化。
for company in company_list:
company['Daily Return'] = company['close'].pct_change()
# 画出日收益率
fig, axes = plt.subplots(nrows=2, ncols=2)
fig.set_figheight(8)
fig.set_figwidth(15)
maotai['Daily Return'].plot(ax=axes[0,0], legend=True,
linestyle='--', marker='o')
axes[0,0].set_title('贵州茅台')
wuliangye['Daily Return'].plot(ax=axes[0,1], legend=True,
linestyle='--', marker='o')
axes[0,1].set_title('五粮液')
yanghe['Daily Return'].plot(ax=axes[1,0], legend=True,
linestyle='--', marker='o')
axes[1,0].set_title('洋河股份')
fenjiu['Daily Return'].plot(ax=axes[1,1], legend=True,
linestyle='--', marker='o')
axes[1,1].set_title('山西汾酒')
fig.tight_layout()
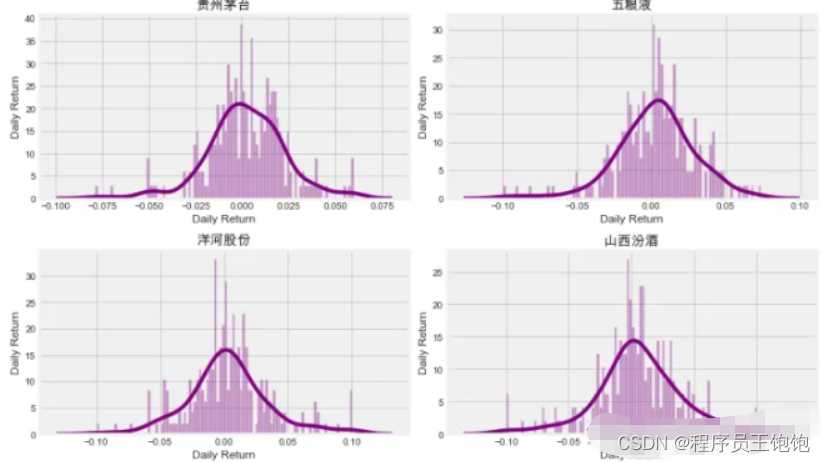
现在用直方图来全面看看平均日收益。我们将使用seaborn在同一图上创建直方图和kde图。
# 注意这里使用了dropna(),否则seaborn无法读取NaN值
plt.figure(figsize=(12, 7))
company_name_c = ['贵州茅台','五粮液','洋河股份','山西汾酒']
for i, company in enumerate(company_list, 1):
plt.subplot(2, 2, i)
sns.distplot(company['Daily Return'].dropna(), bins=100, color='purple')
plt.ylabel('Daily Return')
plt.title(f'{company_name_c[i - 1]}')
# 也可以这样绘制
# maotai['Daily Return'].hist()
plt.tight_layout();
股票收盘价之间的相关性
如果想分析中所有股票的回报呢?
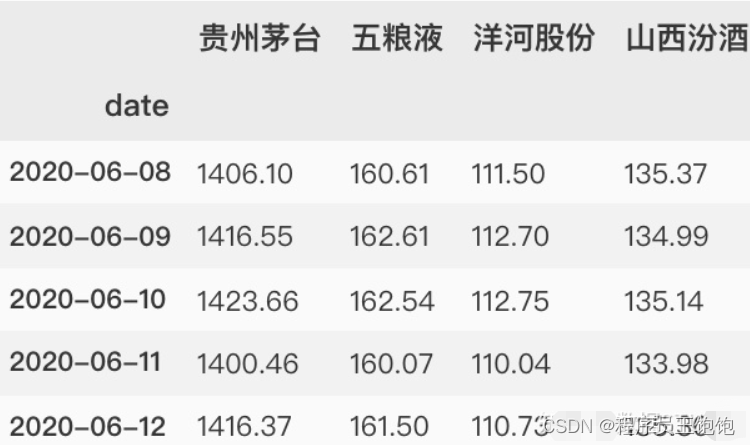
可以将每个股票数据框构建一个包含所有['Close']列的DataFrame。将所有的收盘价为白酒股列表到一个DataFrame
index = maotai.index
closing_df = pd.DataFrame()
for company, company_n in zip(company_list,company_name_c):
temp_df = pd.DataFrame(index=company.index,
data = company['close'].values ,
columns=[company_n])
closing_df = pd.concat([closing_df,temp_df],axis=1)
# 看看数据
closing_df.head()
现在我们有了所有的收盘价,让我们继续获取所有股票的日回报,就像我们对茅台股票做的那样。
liquor_rets = closing_df.pct_change()
liquor_rets.head()
现在可以比较两支股票的日收益率来检验相关性。
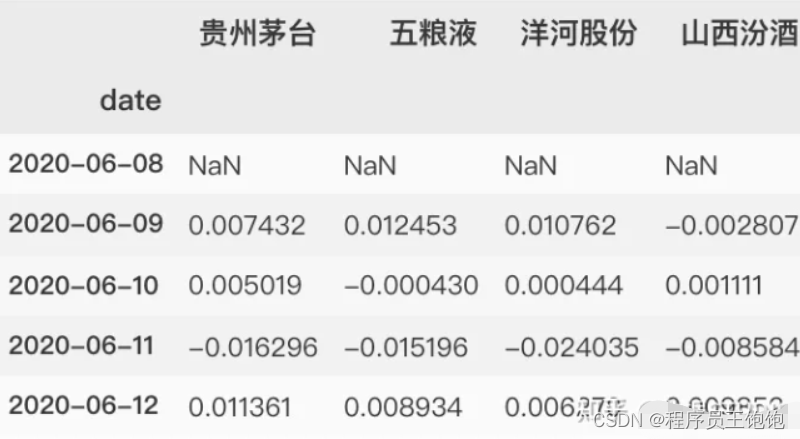
首先让我们看一只股票和它本身的比较。将贵州茅台股票与自身进行比较,应该会显示出一个完美的线性关系
sns.jointplot('maotai', 'maotai',
tech_rets, kind='scatter',
color='seagreen')
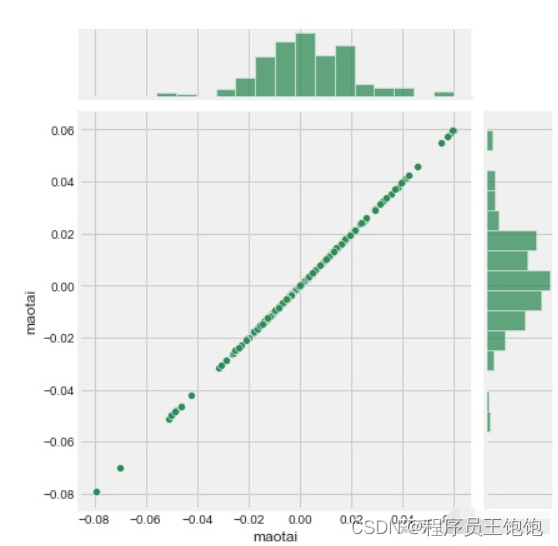
我们将使用joinplot来比较贵州茅台和五粮液的日收益。
sns.jointplot('贵州茅台', '五粮液',
liquor_rets, kind='scatter')
因此,现在可以看到,如果两个股票是完全(和正的)相互相关,它的日回报值之间的线性关系应该发生。
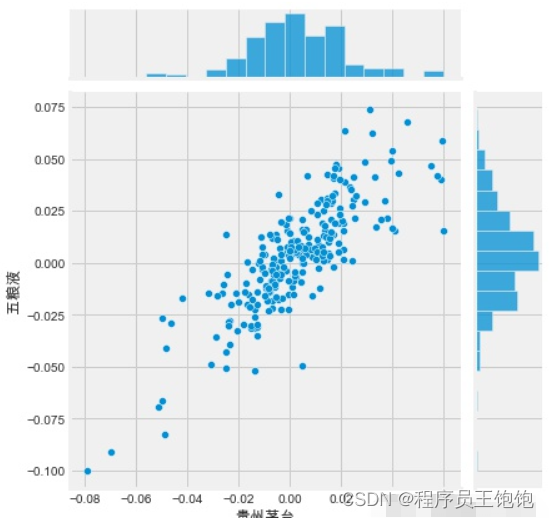
Seaborn和使得我们很容易对我们的技术股票行情列表中的每一个可能的股票组合重复这种比较分析。我们可以使用sns.pairplot() 自动创建这个绘图。
可以简单地调用上的pairplot来对所有比较进行自动可视化分析
sns.pairplot(liquor_rets, kind='reg')
上面我们可以看到所有股票之间的日回报关系。快速浏览一下贵州茅台和五粮液日收益之间的有趣关联。研究这种个体比较可能会很有趣。
虽然仅仅调用sns.pairplot()非常简单,但也可以使用sns.pairgrid()来完全控制图形,包括对角线上的哪种图、上三角形和下三角形。下面是一个充分利用[seaborn]的力量来实现这一结果的例子。
# 通过命名为returns_fig来设置我们的图形,
# 在DataFrame上调用PairPLot
return_fig = sns.PairGrid(liquor_rets.dropna())
# 使用map_upper,我们可以指定上面的三角形是什么样的。
return_fig.map_upper(plt.scatter, color='purple')
# 我们还可以定义图中较低的三角形,
# 包括绘图类型(kde)或颜色映射(blueppurple)
return_fig.map_lower(sns.kdeplot, cmap='cool_d')
# 最后,我们将把对角线定义为每日收益的一系列直方图
return_fig.map_diag(plt.hist, bins=30)
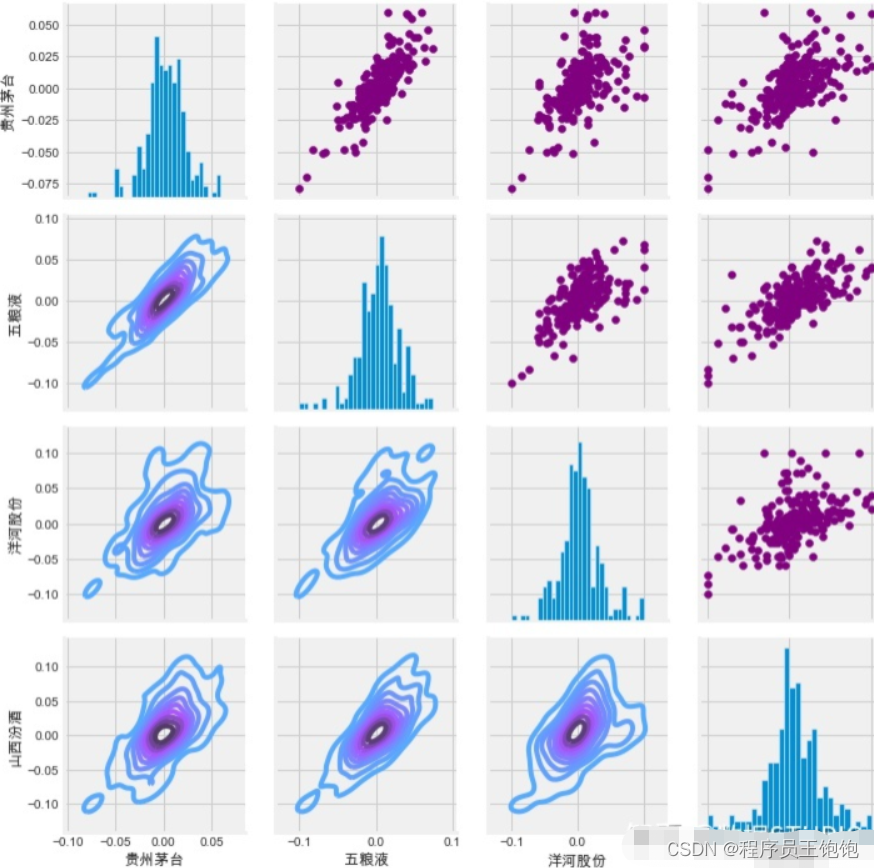
使用同样的方法,绘制四支股票的收盘价相关图。
returns_fig = sns.PairGrid(closing_df)
returns_fig.map_upper(plt.scatter,color='purple')
returns_fig.map_lower(sns.kdeplot,cmap='cool_d')
returns_fig.map_diag(plt.hist,bins=30)
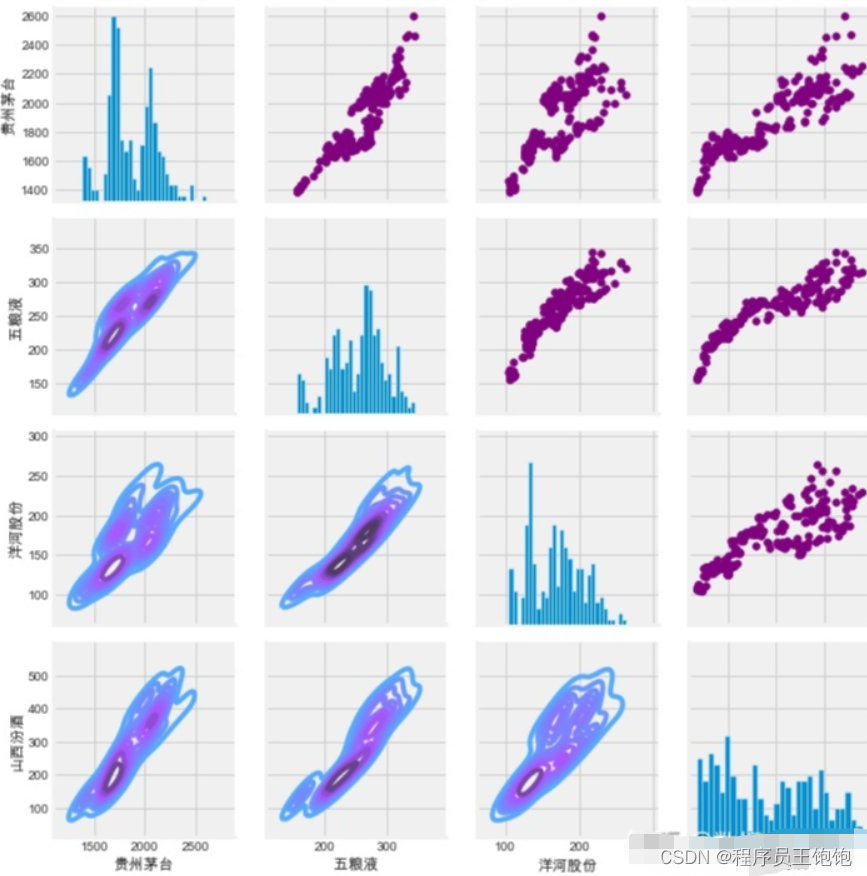
最后,我们还可以做一个相关图,以得到股票日收益值之间的相关性的实际数值。通过比较收盘价格,我们发现了微软和苹果之间有趣的关系。
# 让我们用sebron来做一个每日收益的快速相关图
sns.heatmap(liquor_rets.corr(),
annot=True, cmap='summer')
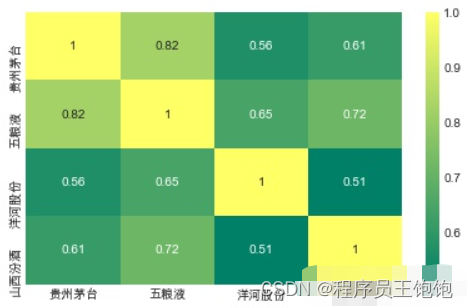
sns.heatmap(closing_df.corr(),
annot=True, cmap='summer')
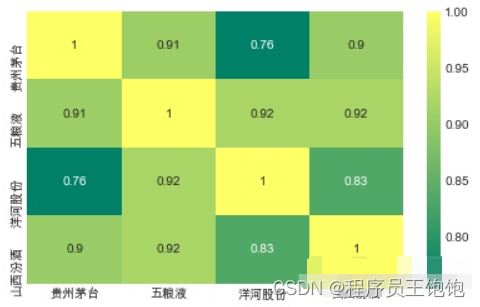
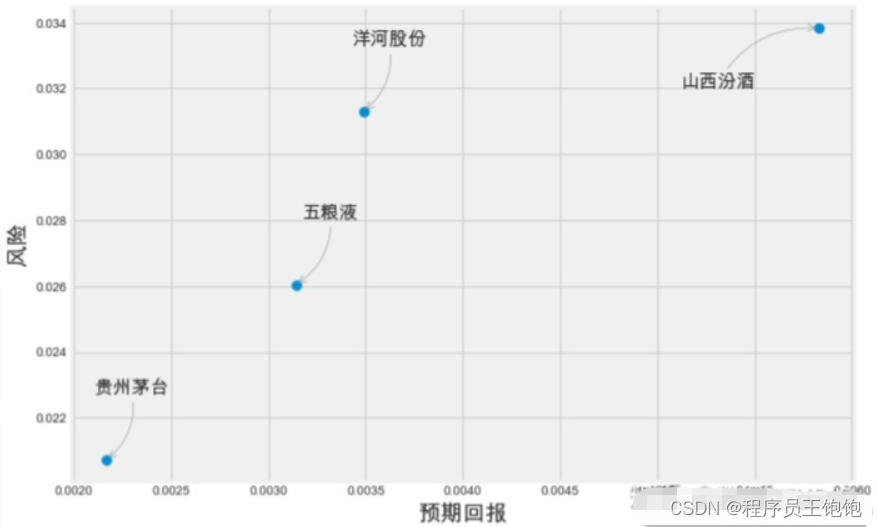
这验证了前面的分析结果,从数字和视觉上看到五粮液和其他几个白酒股票收益率有最强的相关性。有趣的是,所有的白酒都是正相关的。
股票投资的风险
金融风险往往来源于未来的不确定性。我们通常假设股票价格服从[对数正态分布],因而股票回报率服从正态分布。基于此假设,股票回报率的标准房差常用来度量金融风险,也称为波动率。
我们有很多方法来量化风险,其中一个最基本的方法是利用我们收集的关于日收益率百分比的信息将预期收益率与日收益率的标准差进行比较。
# 让我们首先将一个新的DataFrame定义为原始liquor_rets的 DataFrame的压缩版本
rets = liquor_rets.dropna()
area = np.pi * 20
plt.figure(figsize=(10, 7))
plt.scatter(rets.mean(), rets.std(), s=area)
plt.xlabel('预期回报',fontsize=18)
plt.ylabel('风险',fontsize=18)
for label, x, y in zip(rets.columns, rets.mean(), rets.std()):
if label == '山西汾酒':
xytext=(-50,-50)
else:
xytext=(50,50)
plt.annotate(label, xy=(x, y), xytext=xytext,
textcoords='offset points',
ha='right', va='bottom', fontsize=15,
arrowprops=dict(arrowstyle='->',
color='gray',
connectionstyle='arc3,rad=-0.3'))
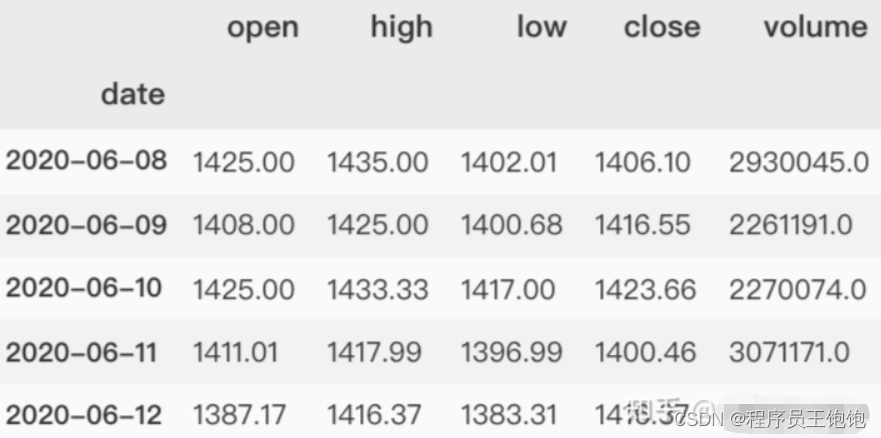
贵州茅台收盘价预测
# 获取股票报价
df = maotai.loc[:,['open','high','low','close','volume']]
df.head()
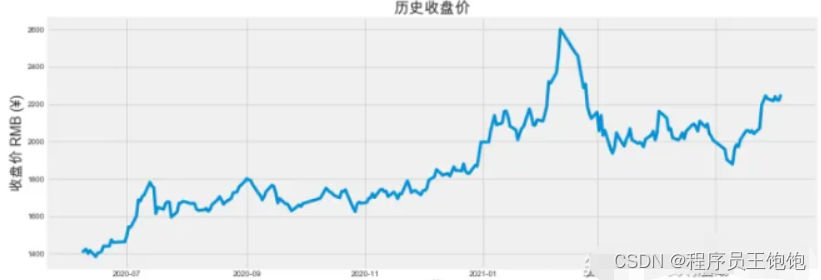
可视化收盘价
plt.figure(figsize=(16,6))
plt.title('历史收盘价',fontsize=20)
plt.plot(df['close'])
plt.xlabel('日期', fontsize=18)
plt.ylabel('收盘价 RMB (¥)', fontsize=18)
plt.show()
# 创建一个只有收盘价的新数据帧
data = df.filter(['close'])
# 将数据帧转换为numpy数组
dataset = data.values
# 获取要对模型进行训练的行数
training_data_len = int(np.ceil( len(dataset) * .95 ))
# 数据标准化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0,1))
scaled_data = scaler.fit_transform(dataset)
# 创建训练集,训练标准化训练集
train_data = scaled_data[0:int(training_data_len), :]
# 将数据拆分为x_train和y_train数据集
x_train = []
y_train = []
for i in range(60, len(train_data)):
x_train.append(train_data[i-60:i, 0])
y_train.append(train_data[i, 0])
if i<= 61:
print(x_train)
print(y_train)
# 将x_train和y_train转换为numpy数组
x_train, y_train = np.array(x_train), np.array(y_train)
# Reshape数据
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
使用LSTM模型预测股价
# pip install keras
from keras.models import Sequential
from keras.layers import Dense, LSTM
# 建立LSTM模型
model = Sequential()
model.add(LSTM(128, return_sequences=True, input_shape= (x_train.shape[1], 1)))
model.add(LSTM(64, return_sequences=False))
model.add(Dense(25))
model.add(Dense(1))
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
model.fit(x_train, y_train, batch_size=1, epochs=1)
170/170 [==============] - 7s 25ms/step - loss: 0.0253
# 创建测试数据集
# 创建一个新的数组,包含从索引的缩放值
test_data = scaled_data[training_data_len - 60: , :]
# 创建数据集x_test和y_test
x_test = []
y_test = dataset[training_data_len:, :]
for i in range(60, len(test_data)):
x_test.append(test_data[i-60:i, 0])
# 将数据转换为numpy数组
x_test = np.array(x_test)
# 重塑的数据
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1 ))
# 得到模型的预测值
predictions = model.predict(x_test)
predictions = scaler.inverse_transform(predictions)
# 得到均方根误差(RMSE)
rmse = np.sqrt(np.mean(((predictions - y_test) ** 2)))
将训练数据、实际数据集预测数据可视化。
train = data[:training_data_len]
valid = data[training_data_len:]
valid['Predictions'] = predictions
plt.figure(figsize=(16,6))
plt.title('模型')
**一、Python所有方向的学习路线**
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


**二、Python必备开发工具**
工具都帮大家整理好了,安装就可直接上手!
**三、最新Python学习笔记**
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

**四、Python视频合集**
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

**五、实战案例**
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
**六、面试宝典**


###### **简历模板**
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里无偿获取](https://bbs.csdn.net/topics/618317507)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**














 1909
1909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









