







b)给 HotelDoc 类添加 suggestion 字段
一、自动补全
1.1、效果说明
当用户在搜索框中输入字符时,我们应该提示出与该字符有关的搜索项.
例如百度中,输入关键词 “byby”,他的效果如下:

1.2、安装拼音分词器
要实现根据字母补全,就需要对文档按照拼英分词. 在GitHub 上有一个 es 的拼英分词插件.
这里的安装方式和 IK 分词器一样,分四步:
- 安装解压.

- 上传到云服务器中,es 的 plugin 目录.
- 重启 es.

- 测试.

这里可以看到,拼音分词器不光对每个字用拼音进行分词,还对每个字的首字母进行分词.
1.3、自定义分词器
1.3.1、为什么要自定义分词器
根据上述测试,可以看出.
-
拼音分词器是将一句话中的每一个字都分成了拼音,这没什么实际的用处.
-
这里并没有分出汉字,只有拼英. 实际的使用中,用户更多的是使用汉字去搜,有拼音只是锦上添花,但是也不能只用拼音分词器,把汉字丢了.
因此这里我们需要对拼音分词器进行一些自定义的配置.
1.3.2、分词器的构成
想要自定义分词器,首先要先了解 es 中分词器的构成.
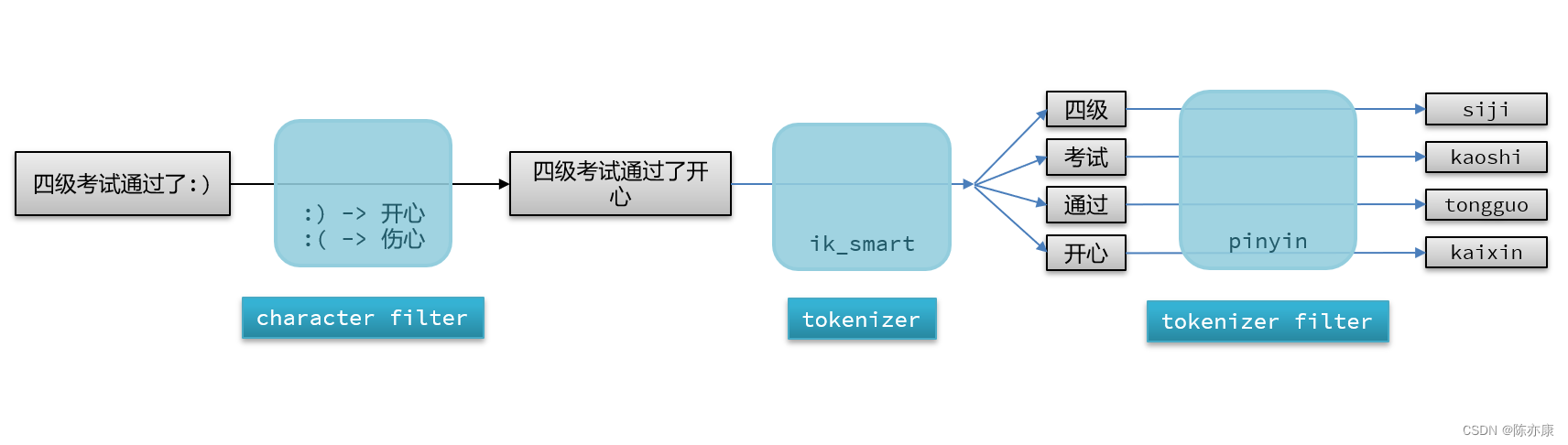
分词器主要由以下三个部分组成:
- character filters:在 tokenizer 之前,对文本的特殊字符进行处理. 比如他会把文本中出现的一些特殊字符转化成汉字,例如 😃 => 开心.
- tokenizer:将文本按照一定的规则切割成词条(term). 例如 “我很开心” 会切割成 “我”、“很”、“开心”.
- tokenizer filter:对 tokenizer 进一步处理. 例如将汉字转化成拼音.
1.3.3、自定义分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": { //自定义分词器
"my_analyzer": { //自定义分词器名称
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}
}
- “type”: “pinyin”:指定使用拼音过滤器进行拼音转换。
- “keep_full_pinyin”: false:表示不保留完整的拼音。如果设置为true,则会将完整的拼音保留下来。
- “keep_joined_full_pinyin”: true:表示保留连接的完整拼音。当设置为true时,如果某个词的拼音有多个音节,那么它们将被连接在一起作为一个完整的拼音。
- “keep_original”: true:表示保留原始词汇。当设置为true时,原始的中文词汇也会保留在分词结果中。
- “limit_first_letter_length”: 16:限制拼音首字母的长度。默认为16,即只保留拼音首字母的前16个字符。
- “remove_duplicated_term”: true:表示移除重复的拼音词汇。如果设置为true,则会移除拼音结果中的重复词汇。
- “none_chinese_pinyin_tokenize”: false:表示是否对非中文文本进行拼音分词处理。当设置为false时,非中文文本将保留原样,不进行拼音分词处理
例如,创建一个 test 索引库,来测试自定义分词器.
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
使用此索引库的分词器进行测试

从上图中可以看出:
1.不光有拼音,还有中文分词.
2.还有中文分词后的英文全拼,以及分词首字母.
1.3.4、面临的问题和解决办法
问题
上面实现的拼音分词器还不能应用到实际的生产环境中~
可以想象这样一个场景:
如果词库中有这两个词:“狮子” 和 “虱子”,那么也就意味着,创建倒排索引时,通过上述自定义的 拼音分词器 ,就会把这两个词归为一个文档,因为他们在分词的时候,会分出共同的拼音 “shizi” 和 “sz”,这就导致他两的文档编号对应同一个词条,导致将来用户在搜索框里输入 “狮子” ,点击搜索之后,会同时搜索出 “狮子” 和 “虱子” ,这并不是我们想看到的.

解决方案
因此字段在创建倒排索引时因该使用 my_analyzer 分词器,但是字段在搜索时应该使用 ik_smart 分词器.
也就是说,用户输入中文的时候,就按中文去搜,用户输入拼音的时候,才按拼音去搜,即使出现上述情况,同时搜出这两个词,那你是按拼音搜,两个都是符合的,不存在歧义.
如下:
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer" //创建倒排索引使用 my_analyzer 分词器.
"search_analyzer": "ik_smart" //搜索时使用 ik_smart 分词器.
}
}
}
}
1.4、completion suggester 查询
1.4.1、基本概念和语法
es 中提供了 completion suggester 查询来实现自动补全功能. 这个查询会匹配用户输入内容开头的词条并返回.
为了提高补全查询的效率,对于文档中的字段类型有一些约束,如下:
- 参与补全查询的字段必须是 completion 类型.
- 参与 自动补全字段 的内容一般是多个词条形成的数组.
POST /test2/_search
{
"suggest": {
"title_suggest": { //自定义补全名
"text": "s", //用户在搜索框中输入的关键字
"completion": { // completion 是自动补全中的一种类型(最常用的)
"field": "补全时需要查询的字段名", //这里的字段名指向的是一个数组(字段必须是 completion 类型),就是要根据数组中的字段进行查询,然后自动补全
"skip_duplicates": true, //如果查询时有重复的词条,是否自动跳过(true 为跳过)
"size": 10 // 获取前 10 条结果.
}
}
}
}
1.4.2、示例一
这里我用一个示例来演示 completion suggester 的用法.
首先创建索引库(参与自动补全的字段类型必须是 completion).
PUT /test2
{
"mappings": {
"properties": {
"title": {
"type": "completion"
}
}
}
}
插入示例数据(字段内容一般是用来补全的多个词条形成的数组.)
POST test2/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test2/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test2/_doc
{
"title": ["Nintendo", "switch"]
}
这里我们设置关键字为 “s”,来自动补全查询,如下:
POST /test2/_search
{
"suggest": {
"title_suggest": {
"text": "s",
"completion": {
"field": "title",
"skip_duplicates": true,
"size": 10
}
}
}
}


1.4.3、示例二
首先创建索引库,如下参与自动补全的字段为 suggestion(通过 copy title 得到).
PUT /test
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_smart",
"copy_to": "suggestion"
},
"suggestion": {
"type": "completion"
}
}
}
}
插入示例数据
POST test/_doc/1
{
"title": "今天天气真好"
}
POST test/_doc/2
{
"title": "我想出去玩"
}
POST test/_doc/3
{
"title": "我要去找小伙伴"
}
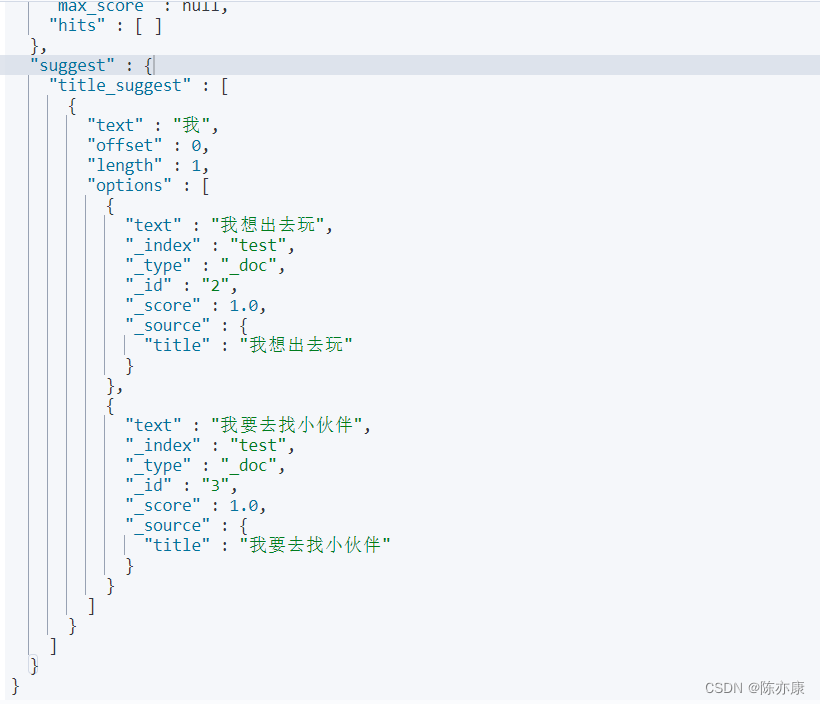
设置关键字为 “我”
POST /test/_search
{
"suggest": {
"title_suggest": {
"text": "我",
"completion": {
"field": "suggestion",
"skip_duplicates": true,
"size": 10
}
}
}
}
自动补全效果如下
1.4.4、示例(黑马旅游)
这里我们基于之前实现的黑马旅游案例来做栗子,实现步骤如下:
a)修改 hotel 索引库结构,设置自定义拼音分词器.
1.设置自定义分词器.
-
修改索引库的 name、all 字段(建立倒排索引使用 拼音分词器,搜索时使用 ik 分词器).
-
给索引库添加一个新字段 suggestion,类型为 completion 类型,使用自定义分词器.
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
[外链图片转存中...(img-md9cLQ6q-1714699432932)]
[外链图片转存中...(img-fWSPeVR9-1714699432932)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 2073
2073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









