






一、门控循环单元(GRU)的理论介绍
在RNN(循环神经网络)中梯度爆炸是一个常见的问题,它严重影响了RNN模型训练的效果和稳定性。梯度爆炸是指误差信号在反向传播过程中,梯度可能会因为某些原因而急剧增大,导致模型权重更新不稳定,甚至发散。这通常发生在模型初始化不当、学习率设置过高等情况下。为了解决梯度消失于梯度爆炸问题,GRU对普通RNN的设计进行了改进,通过门控单元来调整
![]() 的关系,我们不妨将输入
的关系,我们不妨将输入![]() 理解为外部输入的信息,
理解为外部输入的信息,![]() 理解为网络记住的信息,它从时刻1的
理解为网络记住的信息,它从时刻1的![]() 开始向后传递。然而,由于模型本身复杂度的限制,模型并不需要也无法将所有信息时刻都保存下来。因此,在由前一时刻的信息都保留下来。因此,在由前一时刻的信息
开始向后传递。然而,由于模型本身复杂度的限制,模型并不需要也无法将所有信息时刻都保存下来。因此,在由前一时刻的信息都保留下来。因此,在由前一时刻的信息![]() 必须有选择地进行遗忘。同时,在时刻t有新的信息
必须有选择地进行遗忘。同时,在时刻t有新的信息![]() 输入进网络,我们需要在过去的信息
输入进网络,我们需要在过去的信息![]() 之间做到平衡。
之间做到平衡。
GRU设置的门控单元共有两个,分别为更新门和重置门。每个门控单元输出一个数值或向量,由前一时刻的信息![]() 和当前时刻的输入
和当前时刻的输入![]() 组合计算得到
组合计算得到

虽然这两个单元的计算方式完全相同,但是接下来它们会发挥不同的作用。利用重置单元![]() 我们对过去的信息
我们对过去的信息![]() 进行选择性遗忘:
进行选择性遗忘:


这里得到的![]() 混合了当前的
混合了当前的![]() 与部分过去的信息
与部分过去的信息![]() ,并由tanh函数映射到(-1,1)范围内。观察上式与普通RNN的更新方式
,并由tanh函数映射到(-1,1)范围内。观察上式与普通RNN的更新方式![]() ,可以看出,普通的RNN相当于令重置单元
,可以看出,普通的RNN相当于令重置单元![]() 的所有维度都为1,从而保留了所有过去的信息,而
的所有维度都为1,从而保留了所有过去的信息,而![]() 会消除所有过去的信息,使得RNN退化为与过去无关的单个MLP。
会消除所有过去的信息,使得RNN退化为与过去无关的单个MLP。

在上式中,我们更新单元![]() 更新l,我们将保留更多的旧信息
更新l,我们将保留更多的旧信息![]() ,将忽略
,将忽略![]() 的影响;反之,如果
的影响;反之,如果![]() 接近0,我们将要旧信息与新信息混合,保留
接近0,我们将要旧信息与新信息混合,保留![]() 。注意,重置单元和更新单元的作用并不相同,两者不能合并为一个单元。简单来说,重置单元控制旧信息保留的比例,而更新单元同时控制旧信息和新输入的比例。虽然理论上我们可以写出类似
。注意,重置单元和更新单元的作用并不相同,两者不能合并为一个单元。简单来说,重置单元控制旧信息保留的比例,而更新单元同时控制旧信息和新输入的比例。虽然理论上我们可以写出类似![]() 这样的式子,仅用一个更新单元来计算
这样的式子,仅用一个更新单元来计算![]() ,但是其灵活性将大打折扣。
,但是其灵活性将大打折扣。
虽然门控单元的值也是由网络训练得到的,但是门控单元的引入使得GRU可以自我调节梯度。所以GRU几乎不会发生普通RNN的梯度爆炸或梯度消失的现象。
二、门控循环单元(GRU)的实现
先生成一条经过处理的一定的正弦曲线作为数据集,存储在sindata_1000.csv中。该曲线包含1000个数据点,其中前800个点作为训练集,后200个点作为测试集。实现时间序列预测任务,将图像绘制出来。
生成一条正弦曲线的Python代码如下:
import numpy as np
# 设置随机种子保证可重复性
np.random.seed(42)
# 生成1000个数据点
num_points = 1000
# 生成正弦波基础数据
x = np.linspace(0, 10 * np.pi, num_points) # 10个完整周期
y = np.sin(x) # 基础正弦波
# 添加高斯噪声
noise = np.random.normal(0, 0.1, num_points) # 均值为0,标准差0.1的噪声
noisy_y = y + noise
# 保存为CSV文件
np.savetxt('sindata_1000.csv', noisy_y, delimiter=',', fmt='%.6f')
# 可选:绘制生成数据的图像
import matplotlib.pyplot as plt
plt.plot(noisy_y)
plt.title('Generated Sinusoidal Data with Noise')
plt.xlabel('Time Step')
plt.ylabel('Value')
plt.show()
程序运行结果如下:
实现门控循环单元(GRU)的Python代码如下:
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import torch
import torch.nn as nn
# 导入数据集
data = np.loadtxt('sindata_1000.csv', delimiter=',')
num_data = len(data)
split = int(0.8 * num_data)
print(f'数据集大小:{num_data}')
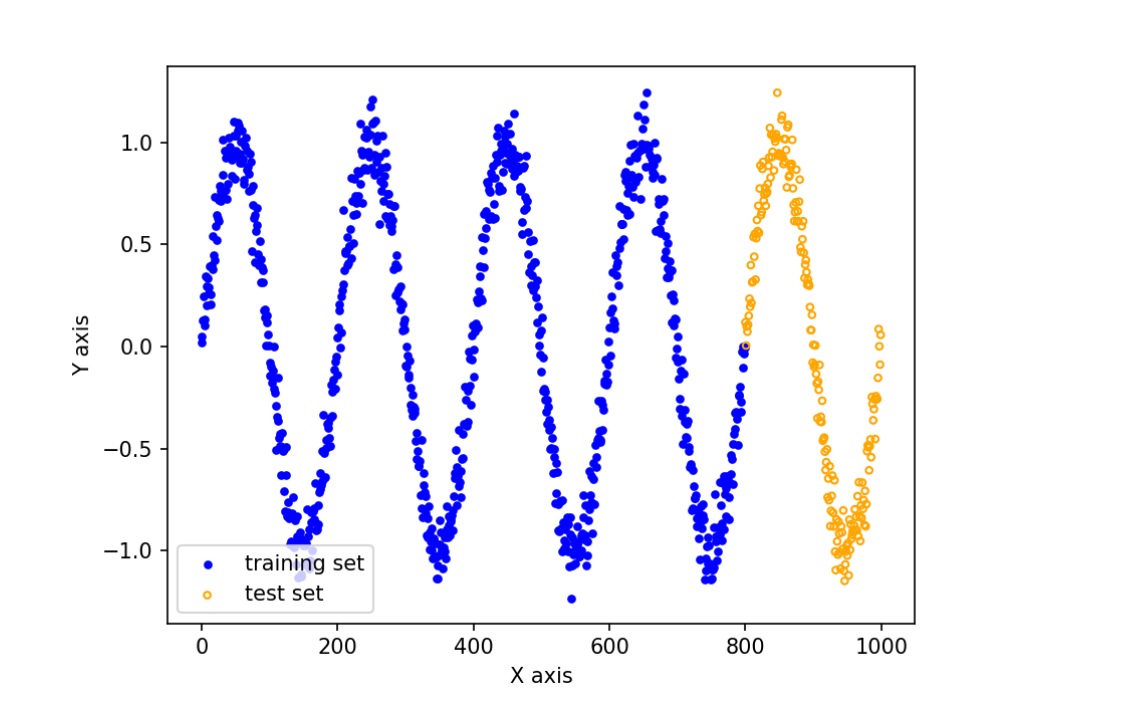
# 数据集可视化
plt.figure()
plt.scatter(np.arange(split), data[:split],
color='blue', s=10, label='training set')
plt.scatter(np.arange(split, num_data), data[split:],
color='none', edgecolor='orange', s=10, label='test set')
plt.xlabel('X axis')
plt.ylabel('Y axis')
plt.legend()
plt.show()
# 分割数据集
train_data = np.array(data[:split])
test_data = np.array(data[split:])
# 输入序列长度
seq_len = 20
# 处理训练数据,把切分序列后多余的部分去掉
train_num = len(train_data) // (seq_len + 1) * (seq_len + 1)
train_data = np.array(train_data[:train_num]).reshape(-1, seq_len + 1, 1)
np.random.seed(0)
torch.manual_seed(0)
x_train = train_data[:, :seq_len] # 形状为(num_data, seq_len, input_size)
y_train = train_data[:, 1: seq_len + 1]
print(f'训练序列数:{len(x_train)}')
# 转为PyTorch向量
x_train = torch.from_numpy(x_train).to(torch.float32)
y_train = torch.from_numpy(y_train).to(torch.float32)
x_test = torch.tensor(test_data[:-1], dtype=torch.float32)
y_test = torch.tensor(test_data[1:], dtype=torch.float32)
class GRU(nn.Module):
# 包含PyTorch的GRU和拼接的MLP
def __init__(self, input_size, output_size, hidden_size):
super().__init__()
# GRU模块
self.gru = nn.GRU(input_size=input_size, hidden_size=hidden_size)
# 将中间变量映射到预测输出的MLP
self.linear = nn.Linear(hidden_size, output_size)
self.hidden_size = hidden_size
def forward(self, x, hidden):
# 前向传播
# x的维度为(batch_size, seq_len, input_size)
# GRU模块的接受的输入为(seq_len, batch_size, input_size)
# 因此需要对x进行变换
# transpose函数可以变换x的坐标轴
# out的维度是(seq_len, batch_size, hidden_size)
out, hidden = self.gru(torch.transpose(x, 0, 1), hidden)
# 取序列最后的中间变量输入给全连接层
out = self.linear(out.view(-1, self.hidden_size))
return out, hidden
# 超参数
input_size = 1 # 输入维度
output_size = 1 # 输出维度
hidden_size = 16 # 中间变量维度
learning_rate = 5e-4
# 初始化网络
gru = GRU(input_size, output_size, hidden_size)
gru_optim = torch.optim.Adam(gru.parameters(), lr=learning_rate)
# GRU测试函数,x和hidden分别是初始的输入和中间变量
def test_gru(gru, x, hidden, pred_steps):
pred = []
inp = x.view(-1, input_size)
for i in range(pred_steps):
gru_pred, hidden = gru(inp, hidden)
pred.append(gru_pred.detach())
inp = gru_pred
return torch.concat(pred).reshape(-1)
# MLP的超参数
hidden_1 = 32
hidden_2 = 16
mlp = nn.Sequential(
nn.Linear(input_size, hidden_1),
nn.ReLU(),
nn.Linear(hidden_1, hidden_2),
nn.ReLU(),
nn.Linear(hidden_2, output_size)
)
mlp_optim = torch.optim.Adam(mlp.parameters(), lr=learning_rate)
# MLP测试函数,相比于GRU少了中间变量
def test_mlp(mlp, x, pred_steps):
pred = []
inp = x.view(-1, input_size)
for i in range(pred_steps):
mlp_pred = mlp(inp)
pred.append(mlp_pred.detach())
inp = mlp_pred
return torch.concat(pred).reshape(-1)
max_epoch = 150
criterion = nn.functional.mse_loss
hidden = None # GRU的中间变量
# 训练损失
gru_losses = []
mlp_losses = []
gru_test_losses = []
mlp_test_losses = []
# 开始训练
with tqdm(range(max_epoch)) as pbar:
for epoch in pbar:
st = 0
gru_loss = 0.0
mlp_loss = 0.0
# 随机梯度下降
for X, y in zip(x_train, y_train):
# 更新GRU模型
# 我们不需要通过梯度回传更新中间变量
# 因此将其从有梯度的部分分离出来
if hidden is not None:
hidden.detach_()
gru_pred, hidden = gru(X[None, ...], hidden)
gru_train_loss = criterion(gru_pred.view(y.shape), y)
gru_optim.zero_grad()
gru_train_loss.backward()
gru_optim.step()
gru_loss += gru_train_loss.item()
# 更新MLP模型
# 需要对输入的维度进行调整,变成(seq_len, input_size)的形式
mlp_pred = mlp(X.view(-1, input_size))
mlp_train_loss = criterion(mlp_pred.view(y.shape), y)
mlp_optim.zero_grad()
mlp_train_loss.backward()
mlp_optim.step()
mlp_loss += mlp_train_loss.item()
gru_loss /= len(x_train)
mlp_loss /= len(x_train)
gru_losses.append(gru_loss)
mlp_losses.append(mlp_loss)
# 训练和测试时的中间变量序列长度不同,训练时为seq_len,测试时为1
gru_pred = test_gru(gru, x_test[0], hidden[:, -1], len(y_test))
mlp_pred = test_mlp(mlp, x_test[0], len(y_test))
gru_test_loss = criterion(gru_pred, y_test).item()
mlp_test_loss = criterion(mlp_pred, y_test).item()
gru_test_losses.append(gru_test_loss)
mlp_test_losses.append(mlp_test_loss)
pbar.set_postfix({
'Epoch': epoch,
'GRU loss': f'{gru_loss:.4f}',
'MLP loss': f'{mlp_loss:.4f}',
'GRU test loss': f'{gru_test_loss:.4f}',
'MLP test loss': f'{mlp_test_loss:.4f}'
})
# 最终测试结果
gru_preds = test_gru(gru, x_test[0], hidden[:, -1], len(y_test)).numpy()
mlp_preds = test_mlp(mlp, x_test[0], len(y_test)).numpy()
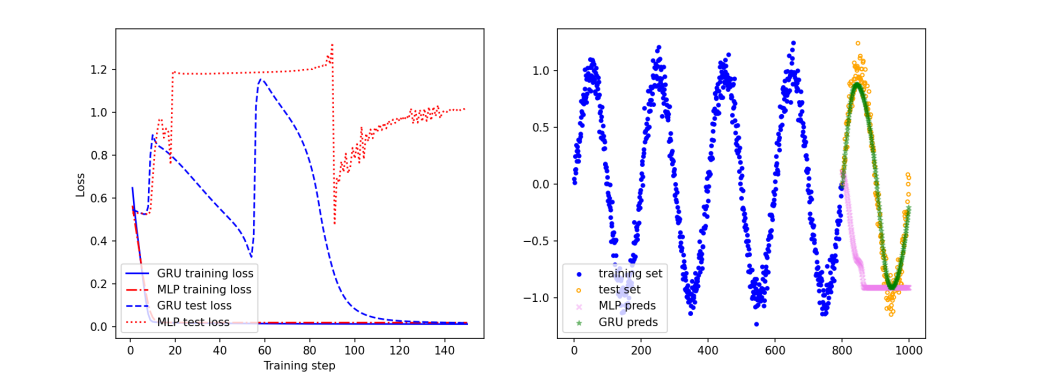
plt.figure(figsize=(13, 5))
# 绘制训练曲线
plt.subplot(121)
x_plot = np.arange(len(gru_losses)) + 1
plt.plot(x_plot, gru_losses, color='blue', label='GRU training loss')
plt.plot(x_plot, mlp_losses, color='red', ls='-.', label='MLP training loss')
plt.plot(x_plot, gru_test_losses, color='blue', ls='--', label='GRU test loss')
plt.plot(x_plot, mlp_test_losses, color='red', ls=':', label='MLP test loss')
plt.xlabel('Training step')
plt.ylabel('Loss')
plt.legend(loc='lower left')
# 绘制真实数据与模型预测值的图像
plt.subplot(122)
plt.scatter(np.arange(split), data[:split], color='blue', s=10, label='training set')
plt.scatter(np.arange(split, num_data), data[split:],
color='none', edgecolor='orange', s=10, label='test set')
plt.scatter(np.arange(split, num_data - 1), mlp_preds,
color='violet', marker='x', alpha=0.4, s=20, label='MLP preds')
plt.scatter(np.arange(split, num_data - 1), gru_preds,
color='green', marker='*', alpha=0.4, s=20, label='GRU preds')
plt.legend(loc='lower left')
plt.show()程序运行结果如下:
数据集大小:1000
训练序列数:38
100%|██████████| 150/150 [00:19<00:00, 7.65it/s, Epoch=149, GRU loss=0.0116, MLP loss=0.0184, GRU test loss=0.0171, MLP test loss=1.0187]
三、总结
通过引入门控机制,能够更有效地缓解梯度爆炸问题,适用于需要捕捉长距离依赖关系的复杂任务。GRU在多个领域(如自然语言处理、时间序列预测等)中都取得了显著的效果。

















 3694
3694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









