







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新HarmonyOS鸿蒙全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

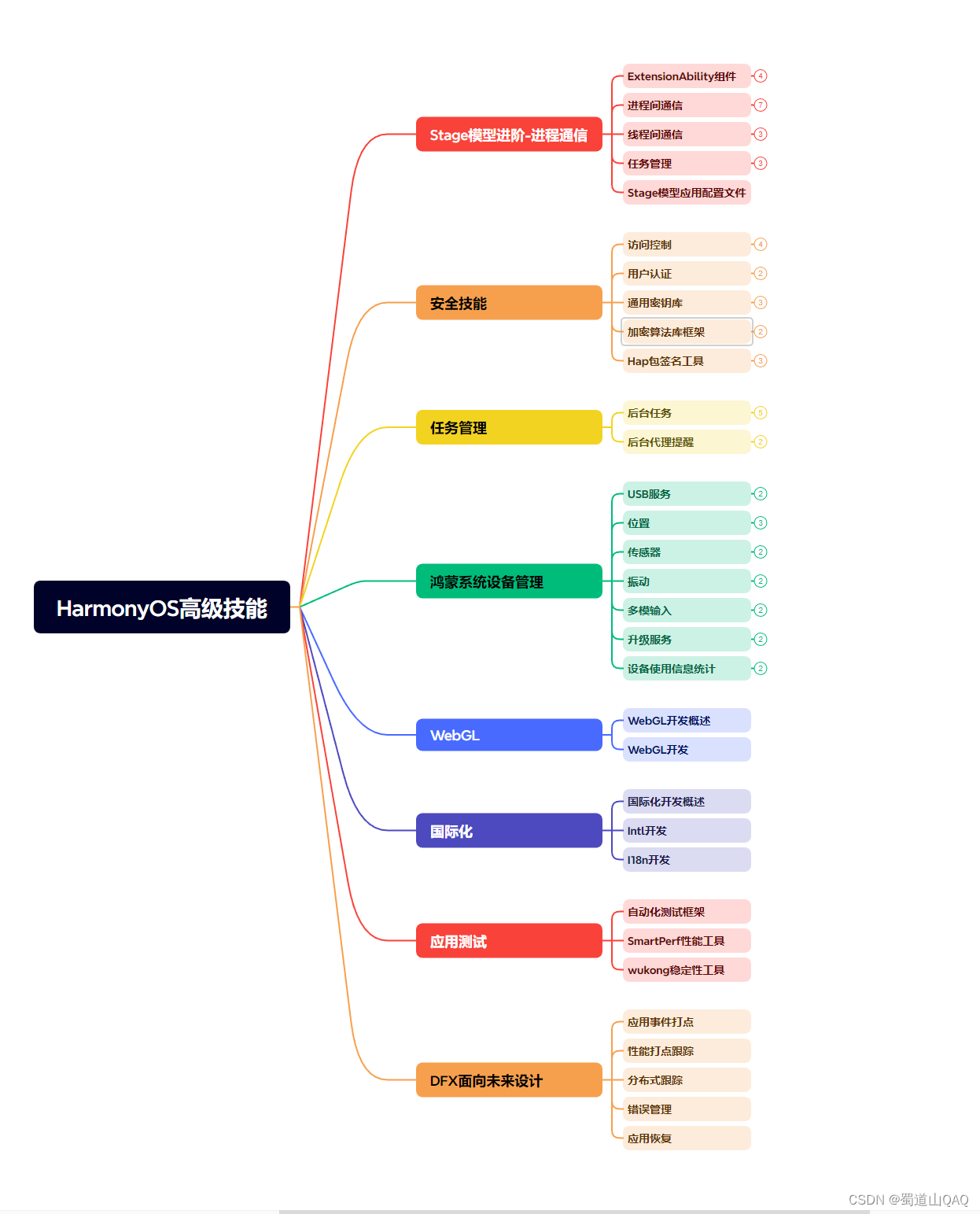
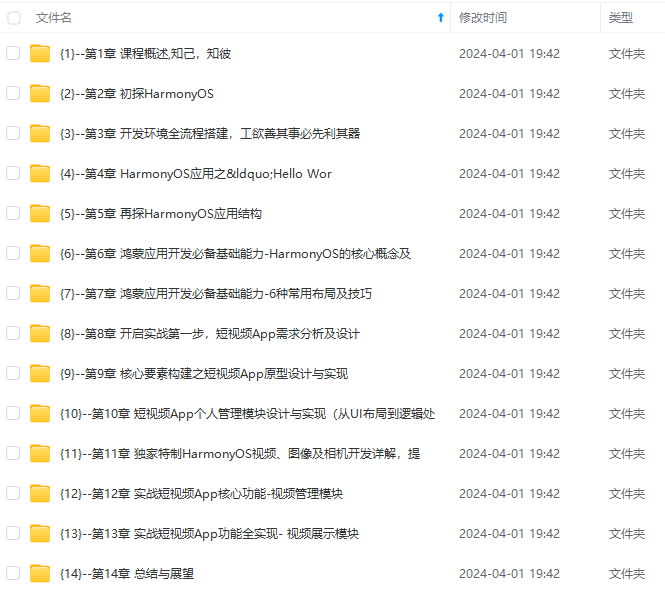


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注鸿蒙)

正文
HBase 是 Google Bigtable 的开源实现,类似 Google Bigtable 利用 GFS 作为其文件存储系统,HBase 利用 Hadoop HDFS 作为其文件存储系统;Google 运行 MapReduce 来处理 Bigtable 中的海量数据,HBase 同样利用 Hadoop MapReduce 来处理 HBase 中的海量数据;Google Bigtable 利用 Chubby 作为协同服务,HBase 利用 Zookeeper 作为对应。
HBase 是一种“NoSQL”数据库。“NoSQL”是一个通用词表示数据库不是RDBMS ,后者支持 SQL 作为主要访问手段。有许多种 NoSQL 数据库,比如,BerkeleyDB 是本地 NoSQL 数据库例子,而 HBase 是大型分布式数据库。从技术上来说, HBase 更像是“Data Store(数据存储)”多于“Data Base(数据库)”,因为 HBase 缺少很多 RDBMS 的特性,如列类型、第二索引、触发器、高级查询语言等。
然而,HBase 有许多特征同时支持线性化和模块化扩充。HBase 集群通过增加 RegionServer 进行扩展,而且只需要将它可以放到普通的服务器中即可。例如,如果集群从10个扩充到20个 RegionServer,存储空间和处理容量都同时翻倍。RDBMS 也能进行扩充,但仅针对某个点——特别是对一个单独数据库服务器的大小——同时,为了更好的性能,需要依赖特殊的硬件和存储设备,而 HBase 并不需要这些。
HBase 具有如下特性:
- 强一致性读写:HBase 不是“eventually consistent(最终一致性)”数据存储。这让它很适合高速计数聚合类任务;
- 自动分片(Automatic sharding): HBase 表通过 region 分布在集群中。数据增长时,region 会自动分割并重新分布;
- RegionServer 自动故障转移;
- Hadoop/HDFS 集成:HBase 支持开箱即用地支持 HDFS 作为它的分布式文件系统;
- MapReduce: HBase 通过 MapReduce 支持大并发处理;
- Java 客户端 API:HBase 支持易于使用的 Java API 进行编程访问;
- Thrift/REST API:HBase 也支持 Thrift 和 REST 作为非 Java 前端的访问;
- Block Cache 和 Bloom Filter:对于大容量查询优化, HBase 支持 Block Cache 和 Bloom Filter;
- 运维管理:HBase 支持 JMX 提供内置网页用于运维。
1. HBase 的应用场景
HBase 不适合所有场景。
首先,确信有足够多数据,如果有上亿或上千亿行数据,HBase 是很好的备选。如果只有上千或上百万行,则用传统的R DBMS 可能是更好的选择。因为所有数据可以在一两个节点保存,集群其他节点可能闲置。
其次,确信可以不依赖所有 RDBMS 的额外特性(例如,列数据类型、 第二索引、事务、高级查询语言等)。
第三,确信你有足够的硬件。因为 HDFS 在小于5个数据节点时,基本上体现不出它的优势。
虽然,HBase 能在单独的笔记本上运行良好,但这应仅当成是开发阶段的配置。
2. Hbase 的优缺点
Hbase 的优点:
- 列的可以动态增加,并且列为空就不存储数据,节省存储空间
- Hbase 自动切分数据,使得数据存储自动具有水平扩展
- Hbase 可以提供高并发读写操作的支持
- 与 Hadoop MapReduce 相结合有利于数据分析
- 容错性
- 版权免费
- 非常灵活的模式设计(或者说没有固定模式的限制)
- 可以跟 Hive 集成,使用类 SQL 查询
- 自动故障转移
- 客户端接口易于使用
- 行级别原子性,即,PUT 操作一定是完全成功或者完全失败
Hbase 的缺点:
- 不能支持条件查询,只支持按照 row key 来查询
- 容易产生单点故障(在只使用一个 HMaster 的时候)
- 不支持事务
- JOIN 不是数据库层支持的,而需要用 MapReduce
- 只能在逐渐上索引和排序
- 没有内置的身份和权限认证
3. HBase 与 Hadoop/HDFS 的差异
HDFS 是分布式文件系统,适合保存大文件。官方宣称它并非普通用途文件系统,不提供文件的个别记录的快速查询。另一方面,HBase 基于 HDFS,并能够提供大表的记录快速查找和更新。这有时会可能引起概念混乱。HBase 内部将数据放到索引好的“StoreFiles”存储文件中,以便提供高速查询,而存储文件位于 HDFS中。
如果想了解 HBase 更深层次的内容,推荐阅读 Lars George 的《HBase: The Definitive Guide》。
Apache HBase 基本概念
在 HBase 的数据被存储在表中,具有行和列。这和关系数据库(RDBMS中)的术语是重叠,但在概念上它们不是一类。相反,应该将 HBase 的表当作是一个多维的 map 结构而更容易让人理解。
1. 术语
- Table(表):HBase table 由多个 row 组成。
- Row(行):每一 row 代表着一个数据对象,每一 row 都是以一个 row key(行键)和一个或者多个 column 组成。row key 是每个数据对象的唯一标识的,按字母顺序排序,即 row 也是按照这个顺序来进行存储的。所以,row key 的设计相当重要,一个重要的原则是,相关的 row 要存储在接近的位置。比如网站的域名,row key 就是域名,在设计时要将域名反转(例如,org.apache.www、org.apache.mail、org.apache.jira),这样的话, Apache 相关的域名在 table 中存储的位置就会非常接近的。
- Column(列):column 由 column family 和 column qualifier 组成,由冒号(
:)进行进行间隔。比如family:qualifier。 - Column Family(列族):在 HBase,column family 是 一些 column 的集合。一个 column family 所有 column 成员是有着相同的前缀。比如, courses:history 和 courses:math 都是 courses 的成员。冒号(
:)是 column family 的分隔符,用来区分前缀和列名。column 前缀必须是可打印的字符,剩下的部分列名可以是任意字节数组。column family 必须在 table 建立的时候声明。column 随时可以新建。在物理上,一个的 column family 成员在文件系统上都是存储在一起。因为存储优化都是针对 column family 级别的,这就意味着,一个 column family 的所有成员的是用相同的方式访问的。 - Column Qualifier(列限定符):column family 中的数据通过 column qualifier 来进行映射。column qualifier 也没有特定的数据类型,以二进制字节来存储。比如某个 column family “content”,其 column qualifier 可以设置为 “content:html” 和 “content:pdf”。虽然 column family 是在 table 创建时就固定了,但 column qualifier 是可变的,可能在不同的 row 之间有很大不同。
- Cell(单元格):cell 是 row、column family 和 column qualifier 的组合,包含了一个值和一个 timestamp,用于标识值的版本。
- Timestamp(时间戳):每个值都会有一个 timestamp,作为该值特定版本的标识符。默认情况下,timestamp 代表了当数据被写入 RegionServer 的时间,但你也可以在把数据放到 cell 时指定不同的 timestamp。
2. map
HBase/Bigtable 的核心数据结构就是 map。不同的编程语言针对 map 有不同的术语,比如 associative array(PHP)、associative array(Python),Hash(Ruby)或 Object (JavaScript)。
简单来说,map 就是 key-value 对集合。下面是一个用 JSON 格式来表达 map 的例子:
{
“zzzzz” : “woot”,
“xyz” : “hello”,
“aaaab” : “world”,
“1” : “x”,
“aaaaa” : “y”
}
3. 分布式
毫无疑问,HBase/Bigtable 都是建立在分布式系统上的,HBase 基于 Hadoop Distributed File System (HDFS) 或者 Amazon’s Simple Storage Service(S3),而 Bigtable 使用 Google File System(GFS)。它们要解决的一个问题就是数据的同步。这里不讨论如何做到数据同步。 HBase/Bigtable 可以部署在成千上万的机器上来分散访问压力。
4. 排序
和一般的 map 实现有所区别,HBase/Bigtable 中的 map 是按字母顺序严格排序的。这就是说,对于 row key 是“aaaaa”的旁边 row key 应该是 “aaaab”,而与 row key 是“zzzzz”离得较远。
还是以上面的 JSON 为例,一个排好序的例子如下:
{
“1” : “x”,
“aaaaa” : “y”,
“aaaab” : “world”,
“xyz” : “hello”,
“zzzzz” : “woot”
}
在一个大数据量的系统里面,排序很重要,特别是 row key 的设置策略决定了查询的性能。比如网站的域名,row key 就是域名,在设计时要将域名反转(例如,org.apache.www、org.apache.mail、org.apache.jira)。
5. 多维
多维 map,即 map 里面嵌套 map。例如:
{
“1” : {
“A” : “x”,
“B” : “z”
},
“aaaaa” : {
“A” : “y”,
“B” : “w”
},
“aaaab” : {
“A” : “world”,
“B” : “ocean”
},
“xyz” : {
“A” : “hello”,
“B” : “there”
},
“zzzzz” : {
“A” : “woot”,
“B” : “1337”
}
}
6. 时间版本
在查询中不指定时间,返回的将是最近的一个时间的版本。如果给出 timestamp,返回的将是早于这个时间的数值。例如: 查询 row/column 是“aaaaa”/“A:foo”的,将返回 y;查询 row/column/timestamp 是“aaaaa”/“A:foo”/10的,将返回 m;查询 row/column/timestamp 是“aaaaa”/“A:foo”/2的,将返回 null。
{
// …
“aaaaa” : {
“A” : {
“foo” : {
15 : “y”,
4 : “m”
},
“bar” : {
15 : “d”, } }, “B” : { “” : { 6 : “w” 3 : “o” 1 : “w” } } }, // … }
7. 概念视图
下面表格是一个名为 webtable 的 table ,包含了两个 row(com.cnn.www 和 com.example.www)和三个 column family(contents、 anchor和people)。第一个 row(com.cnn.www)中,anchor 包含了两个 column(anchor:cssnsi.com和 anchor:my.look.ca),contents包含了一个 column(contents:html)。在这个例子里面,row key 是com.cnn.www的 row 包含了5个版本,而 row key 是com.example.www的 row 包含了1个版本。column qualifier 为 contents:html包含了给定网站的完整的 HTML。column family 是anchor的每个 qualifier 包含了网站的链接。人们列族代表与网站相关的人。column family 是people关联的是网站的人物资料。
| Row Key | Timestamp | ColumnFamily contents | ColumnFamily anchor | ColumnFamily people |
|---|---|---|---|---|
| “com.cnn.www” | t9 | anchor:cnnsi.com = “CNN” | ||
| “com.cnn.www” | t8 | anchor:my.look.ca = “CNN.com” | ||
| “com.cnn.www” | t6 | contents:html = “…” | ||
| “com.cnn.www” | t5 | contents:html = “…” | ||
| “com.cnn.www” | t3 | contents:html = “…” |
在这个表中显示为空的 cell 不占用空间,这使得 HBase 变得“稀疏”。除了表格方式来展现数据试图,也使用使用多维 map,如下:
{
“com.cnn.www”: {
contents: {
t6: contents:html: “…”
t5: contents:html: “…”
t3: contents:html: “…”
}
anchor: {
t9: anchor:cnnsi.com = “CNN”
t8: anchor:my.look.ca = “CNN.com”
}
people: {}
}
“com.example.www”: {
contents: {
t5: contents:html: “…”
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注鸿蒙)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
…"
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注鸿蒙)
[外链图片转存中…(img-KI4wJiMZ-1713553311553)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









