






MongoDB分片部署
MongoDB分片介绍

--configsvr 这里我们完全可以像启动普通 mongodb 服务一样启动,不需要添加 —shardsvr 和 configsvr 参数。因为这两个参数的作用就是改变启动端口的,所以我们自行指定了端口就可以。
分片架构
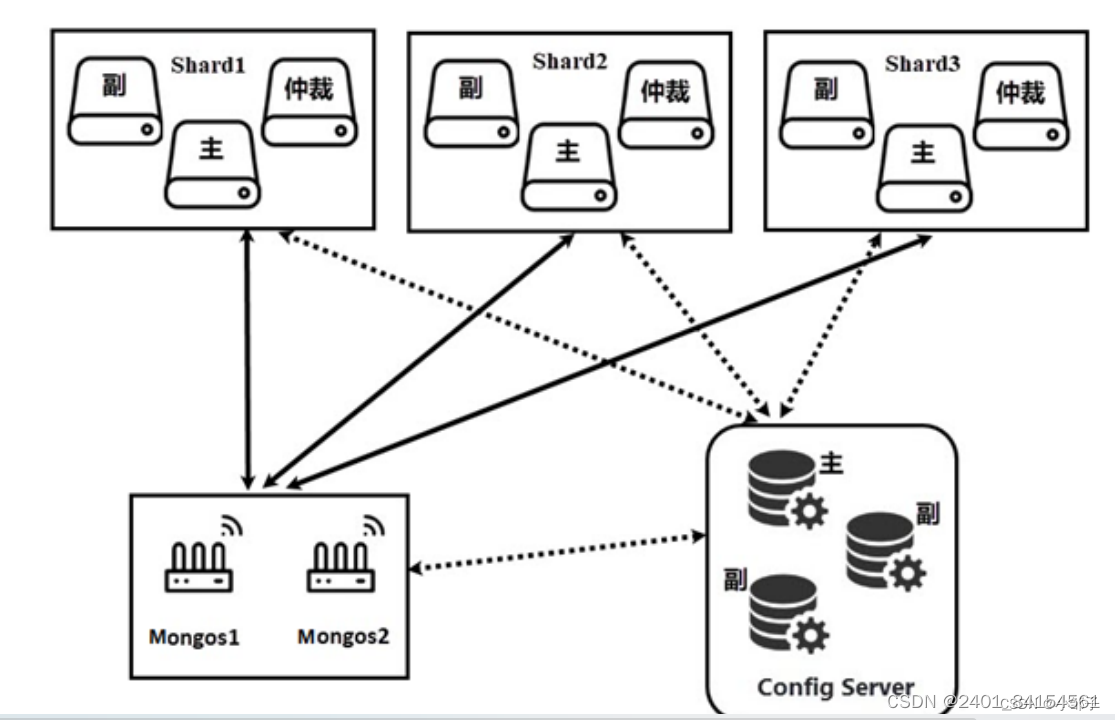
从图中可以看出,分片集群中主要由三个部分组成,即分片服务器( Shard )、路由服务器
( Mongos )以及配置服务器( Config Server )组成。其中,分片服务器有三个,即 Shard1 、
Shard2 、 Shard3 ;路由服务器有两个,即 Mongos1 和 Mongos2 ;配置服务器有三个,即主、副、副。
主要有如下所述三个主要组件:
Shard: 用于存储实际的数据块,实际生产环境中一个shard server 角色可由几台机器组个一个 replica set(副本集群) 承担,防止主机单点故障【3.6版本后必须配置成副本集群】
Config Server: mongod实例,存储了整个 ClusterMetadata ,其中包括 chunk 信息【3.4版本后必须部署成副本集群】。
Query Routers: 前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
部署分片集群
部署shard【副本集群】
部署两个shard分片块,数据存储的地方。
步骤一:环境准备
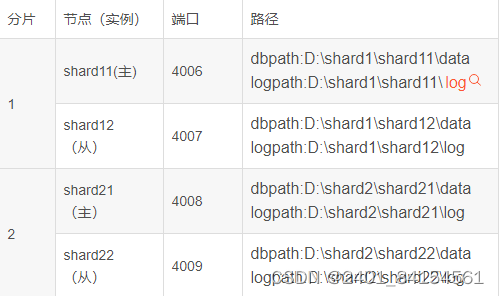
每一个分片都应该安装 MongoDB 实例,需要将 bin 文件复制到每个分片中, 并且创建data 文件以及 log 文件存放数据库数据和日志数据
![]()
每个shard包含两个实例,一主一从。
步骤二 启动分片服务(实例)
启动分片集群shard1(shard11和shard12)
shard11
然后进入数据库bin目录中,启动cmd
\bin>mongod --shardsvr --replSet shard1 -port 4006 -dbpath D:\shard1\shard11\data -logpath D:\shard1\shard11\log\shard11.log--shardsvr 为分片声明
当命令一直保持运行状态则说明服务运行成功,此服务为一次性服务,不要关闭此窗口,最小化即可。
shard12:

再次进入数据库bin目录中,启动cmd
bin>mongod --shardsvr --replSet shard1 -port 4007 -dbpath D:\shard1\shard12\data -logpath D:\shard1\shard12\log\shard12.log
启动分片集群2(shard21和shard22)
shard21
shard22
\bin>mongod --shardsvr --replSet shard2 -port 4009 -dbpath D:\shard2\shard22\data -logpath D:\shard2\shard22\log\shard22.log 
tips:
电脑版本比较高,所以的 cmd 需要使用管理员身份运行
启动服务均为一次性服务,关闭 cmd 即为关闭服务,所以在未完成前,请勿关闭
实例均未添加至系统环境变量,请在 bin 目录下启动
虽然窗口很多,操作不太友好,但是在 win 系统下,还是多有耐心一点, linux会简单一些
步骤三:配置分片(shard1和shard2)集群
进入到shard1集群任何一个节点中
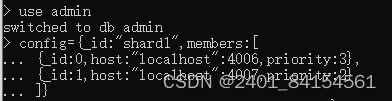
![]()
进入到shard2集群任何一个节点中
use admin
config={_id:"shard2",members:[
... {_id:0,host:"localhost:4008",priority:2},
... {_id:1,host:"localhost:4009",priority:1}
... ]}
rs.initiate(config)
至此,shard的两个集群配置好了。
部署config server
步骤一:环境准备
值得注意的是:在 MongoDB 3。4 版本后 config 服务必须配置为 副本集,这里设置为一主一从。
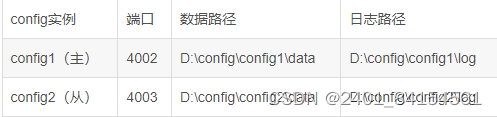
老样子,每个文件夹添加data和log
步骤二:启动config server
启动config1
进入到bin目录中,启动cmd
\bin>mongod --configsvr --replSet confset -port 4002 -dbpath D:\config\config1\data -logpath D:\config\config1\log\conf1.log--configsvr 这里我们完全可以像启动普通 mongodb 服务一样启动,不需要添加 —shardsvr 和 configsvr 参数。因为这两个参数的作用就是改变启动端口的,所以我们自行指定了端口就可以。

启动config2
\bin>mongod --configsvr --replSet confset -port 4003 -dbpath D:\config\config2\data -logpath D:\config\config2\log\conf2.log

不要关闭 cmd 窗口,最小化即可
步骤三:配置config server集群
进入任何一个配置服务器的节点初始化配置服务器的群集
![]()
use admin
config={_id:"confset",configsvr:true,members:[
... {_id:0,host:"localhost:4002"},
... {_id:1,host:"localhost:4003"}
... ]}
rs.initiate(config)![]()
部署路由服务器 Route Process
可以创建专门的文件夹存放日志
在进入 数据库 bin 目录中 启动 cmd
D:\MongoDB\bin>mongos --configdb confset/localhost:4002,localhost:4003 -logpath D:\mongos\log\mongos.log -port 4000mongos : mongos 就是一个路由服务器,它会根据管理员设置的 “ 片键 ” 将数据分摊到自己管理的
mongod 集群,数据和片的对应关系以及相应的配置信息保存在 "config 服务器 " 上。

配置分片信息
bin 目录下使用 MongoDB Shell 登录到 mongos ,添加 Shard 节点
![]()
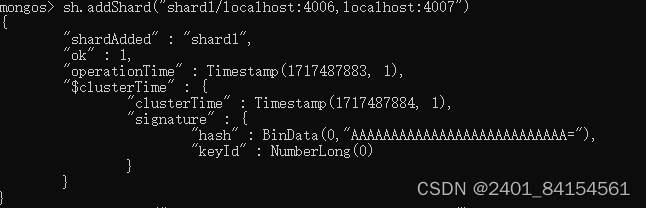
mongos> sh.addShard("shard1/localhost:4006,localhost:4007")
mongos> sh.addShard("shard2/localhost:4008,localhost:4009")
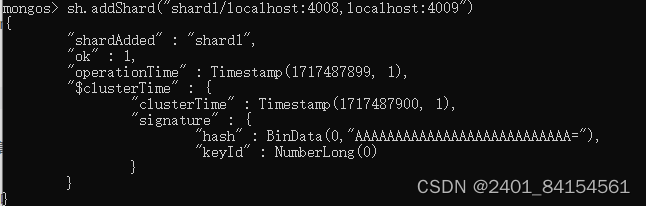
查看分片信息

开启安全认证

测试分片
登入路由(4000) 端口
指定要分片的数据库
mongos> sh.enableSharding("test")指定数据库里需要分片的集合和片键,片键根据实际情况选择
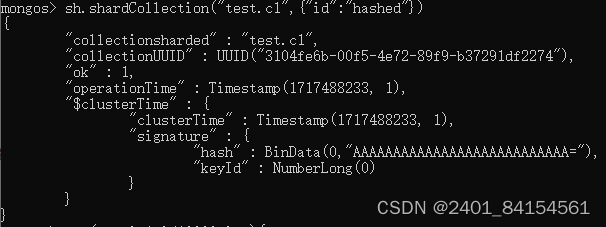
mongos> sh.shardCollection("test.c2",{"id":"hashed"})上述指令指定分片集合为c2,分片字段为“id”,分片形式是哈希分片,若改成“1”则为范围分片
如果集合已经包含数据,则必须在分片集合之前创建一个支持分片键的索引,如果集合为空,则
mongodb 将创建索引。
插入10000条数据验证,数据必须包含分片键:id
mongos> for(var i=1;i<=10000;i++){
... db.c2.save({id:i,name:"a"+i});}查看分片状态
输入sh.status() 查看分片集群状态
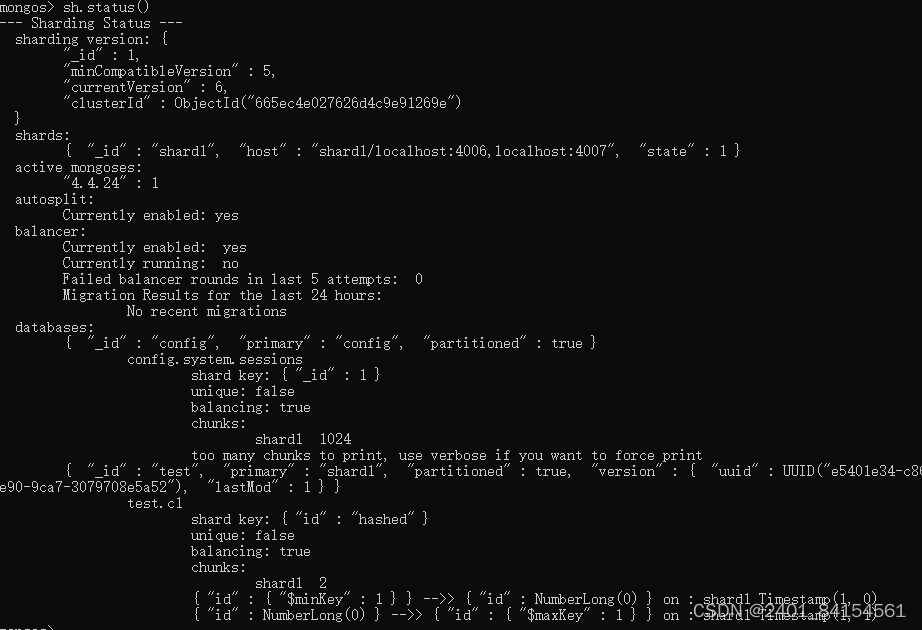
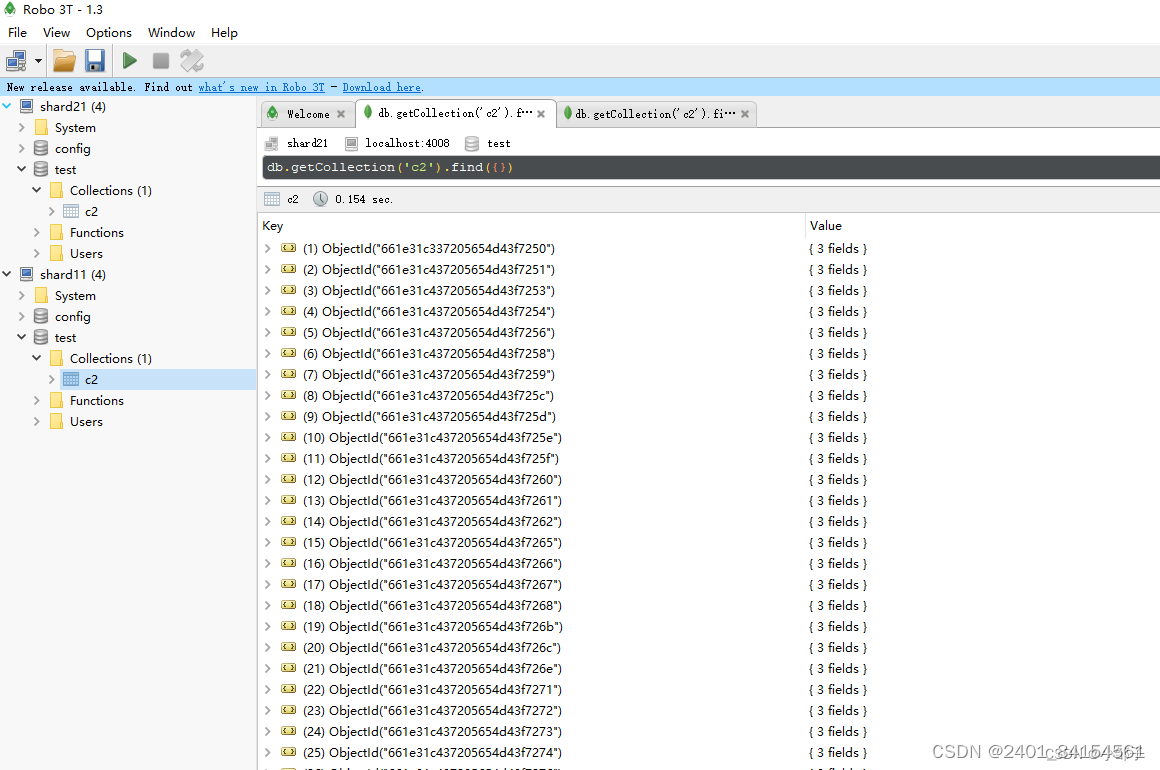
两个shard都有数据分布,说明分片成功!
robo 3T查看分片集
连接两个 shard 端口查看分片情况,若两个shard中的数据不同,则说明分片成功!!

副本集部署
前期环境准备:
| 节点 | 配置 |
| 主节点 | localhost:27017 |
| 从节点1 | localhost:27018 |
| 从节点2 | localhost:27019 |
每一个节点(实例)都创建对应的数据文件(data)和日志文件(log)。例如:

启动实例(服务)
语法:
bin>mongod -port 端口号 -dbpath 数据路径 -logpath 日志路径 -replSet 副本集名称
主节点:

从节点:
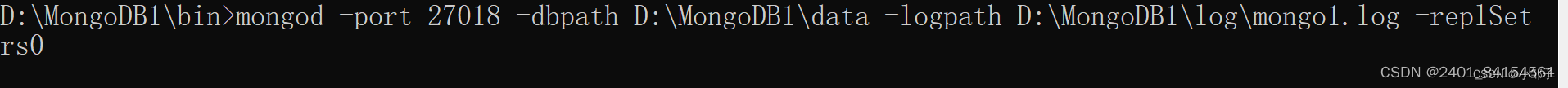 从节点2:
从节点2:
 以上三个节点启动的都是一次性服务,所以窗口不要关闭!
以上三个节点启动的都是一次性服务,所以窗口不要关闭!
tips:
节点启动可能会遇到问题,主要检查端口是否被占用,和路径配置问题,若都没问题则考虑以管理员身份启动cmd。
配置副本集
维持服务不要关闭,进入任何一个节点内:

进行配置:
1.切换到admin数据库
use admin
2.配置集群
config={_id:"rs0",members:[
... {_id:0,host:"localhost:27017","priority":3},
... {_id:1,host:"localhost:27018","priority":2},
... {_id:2,host:"localhost:27019","priority":1}]}
说明:第一个“_id”为副本集名称,“priority”为优先级,数字越大,优先级越高。
3.使得配置生效
rs.initiate(config)
 生效后可能会出现节点显示错误:
生效后可能会出现节点显示错误:
(明明是主节点,但却显示从节点)
![]()
只需要查看副本集状态即可更正:
rs.status()
![]()
从节点配置
刚刚配置好的副本集中的从节点是无法进行数据库操作的:
要先进行从节点永久化设置:
rs.slaveOk()
或者使用(推荐使用):
rs.secondaryOk()

副本集验证
在主节点中增加数据
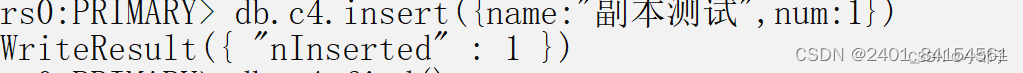
在从节点上验证: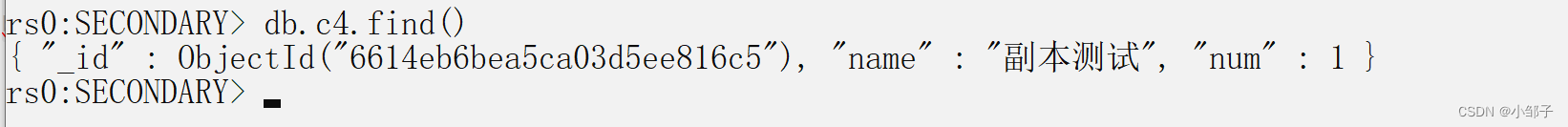
说明副本集群部署成功。
另介绍ACID
关系数据库, 最大的特点就是事务处理, 即满足ACID;
ACID可以理解为ACID最重要的含义,就是Atomicity和Isolation ,即强制一致性,要么全做要么不做,所有用户看到的数据一致。强调数据的可靠性, 一致性和可用性。
ACID 为 Atomicity, Consistency, Isolation, and Durability,其中ACID分别表示为:
1.原子性(Atomicity):事务中的操作要么都做,要么都不做。
2.一致性(Consistency):系统必须始终处在强一致状态下。
3.隔离性(Isolation):一个事务的执行不能被其他事务所干扰。
4.持续性(Durability):一个已提交的事务对数据库中数据的改变是永久性的。
保证ACID是传统关系型数据库中事务管理的重要任务,几种事务类型为:未提交读、可提交读、可重复读、可序列化。
BASE
分布式数据库, 最大的特点就是分布式,即满足BASE,ASE方法通过牺牲一致性和孤立性来提高可用性和系统性能。
BASE为Basically Available, Soft-state, Eventually consistent,其中BASE分别代表:
1.基本可用(Basically Available):系统能够基本运行、一直提供服务。
2.软状态(Soft-state):系统不要求一直保持强一致状态。
3.最终一致性(Eventual consistency):系统需要在某一时刻后达到一致性要求。
表示为支持可用性,牺牲一部分一致性,可以显著的提升系统的伸缩性,数据为最终一致。和ACID为相反的方向。其中事务支持不会很高。
链接库文件
import pymongo
链接数据库
#连接数据库,指定ip和端口
myclient=pymongo.MongoClient('localhost',27017)
查看数据库和集合
#查看数据库
dbs=myclient.list_database_names()
dbs
['admin', 'config', 'local', 'test']
#切换|创建(本身不存在)数据库
mydb=myclient['test']#切换到数据库test
#查看test数据库中的所有集合
cols=mydb.list_collection_names()
cols
['c1']
#直接切换|创建集合
cl=mydb['c1']
#显示创建、删除集合
mydb.create_collection("c2")
mydb.drop_collection("c2")
{'nIndexesWas': 1, 'ns': 'test.c2', 'ok': 1.0}
文档的增删改查
#打印文档
for i in c1.find():
print(i)
{'_id': ObjectId('664c3b031bd603b30b6505a8'), 'name': 'a11', 'age': 88.0}
{'_id': ObjectId('664c3b031bd603b30b6505a9'), 'name': 'aa2', 'age': 99.0}
{'_id': ObjectId('664c3b031bd603b30b6505aa'), 'name': 'aa3', 'age': 100.0}
增
单文档插入insert_one
d1={"name":"kjfd","age":18,"major":"大数据技术"}#在python中,key(字段)必须用双引号括起来
x=c1.insert_one(d1)
print(x.inserted_id)#打印_id
664c481656484bbff8259ebb
#查询c1文档
for i in c1.find():
print(i)
{'_id': ObjectId('664c3b031bd603b30b6505a8'), 'name': 'a11', 'age': 88.0}
{'_id': ObjectId('664c3b031bd603b30b6505a9'), 'name': 'aa2', 'age': 99.0}
{'_id': ObjectId('664c3b031bd603b30b6505aa'), 'name': 'aa3', 'age': 100.0}
{'_id': ObjectId('664c481656484bbff8259ebb'), 'name': 'kjfd', 'age': 18, 'major': '大数据技术'}
多文档插入 insert_many
#多文档插入,参数为列表#
d2=[
{"name":"jasgdkj","age":14,"major":"大数据技术"},
{"name":"kadh","age":49,"major":"大数据技术"},
{"name":"kagd","age":48,"major":"人工智能"}
]
x=c1.insert_many(d2)
print(x.inserted_ids)#打印多文档_id
[ObjectId('664c498656484bbff8259ebc'), ObjectId('664c498656484bbff8259ebd'), ObjectId('664c498656484bbff8259ebe')]
#查询c1文档
for i in c1.find():
print(i)
{'_id': ObjectId('664c3b031bd603b30b6505a8'), 'name': 'a11', 'age': 88.0}
{'_id': ObjectId('664c3b031bd603b30b6505a9'), 'name': 'aa2', 'age': 99.0}
{'_id': ObjectId('664c3b031bd603b30b6505aa'), 'name': 'aa3', 'age': 100.0}
{'_id': ObjectId('664c481656484bbff8259ebb'), 'name': 'kjfd', 'age': 18, 'major': '大数据技术'}
{'_id': ObjectId('664c498656484bbff8259ebc'), 'name': 'jasgdkj', 'age': 14, 'major': '大数据技术'}
{'_id': ObjectId('664c498656484bbff8259ebd'), 'name': 'kadh', 'age': 49, 'major': '大数据技术'}
{'_id': ObjectId('664c498656484bbff8259ebe'), 'name': 'kagd', 'age': 48, 'major': '人工智能'}
查
#按条件查询c1文档
#find()第一个参数为查询条件,第二个参数为(不)显示的列
for i in c1.find({"major":"大数据技术"},{"_id":0}):
print(i)
{'name': 'kjfd', 'age': 18, 'major': '大数据技术'}
{'name': 'jasgdkj', 'age': 14, 'major': '大数据技术'}
{'name': 'kadh', 'age': 49, 'major': '大数据技术'}
#按修饰符(运算符)进行查询
q={"age":{"$gt":20}}#查询条件,age大于20
for i in c1.find(q,{"_id":0}):
print(i)
{'name': 'a11', 'age': 88.0}
{'name': 'aa2', 'age': 99.0}
{'name': 'aa3', 'age': 100.0}
{'name': 'kadh', 'age': 49, 'major': '大数据技术'}
{'name': 'kagd', 'age': 48, 'major': '人工智能'}
#正则匹配¥regrex,查询name以k开头的所有文档
q1={"name":{"$regex":"k"}}
for i in c1.find(q1,{"_id":0}):
print(i)
{'name': 'jasgdkj', 'age': 14, 'major': '大数据技术'}
{'name': 'kadh', 'age': 49, 'major': '大数据技术'}
{'name': 'kagd', 'age': 48, 'major': '人工智能'}
{'name': 'kjfd', 'age': 18, 'major': '大数据技术'}
for i in c1.find({},{"_id":0}):
print(i)
{'name': 'a11', 'age': 88.0}
{'name': 'aa2', 'age': 99.0}
{'name': 'aa3', 'age': 100.0}
{'name': 'kjfd', 'age': 18, 'major': '大数据技术'}
{'name': 'jasgdkj', 'age': 14, 'major': '大数据技术'}
{'name': 'kadh', 'age': 49, 'major': '大数据技术'}
{'name': 'kagd', 'age': 48, 'major': '人工智能'}
#在python中管道必须为list形式,所以要用[括起来]
pin=[
{"$group":{"_id":"$major","max_age":{"$max":"$age"}}}
]
#返回结果为列表,循环打印
result=c1.aggregate(pin)
for i in result:
print(i)
{'_id': '人工智能', 'max_age': 48}
{'_id': None, 'max_age': 100.0}
{'_id': '大数据技术', 'max_age': 49}
按照major分组,统计年龄平均值,并统计每个分组文档数,按照平均年龄降序排序
pin1=[
{"$group":{"_id":"$major","avg_age":{"$avg":"$age"},"count":{"$sum":1}}},
{"$sort":{"avg_age":-1}}
]
#返回结果为列表,循环打印
result=c1.aggregate(pin1)
for i in result:
print(i)
{'_id': None, 'avg_age': 95.66666666666667, 'count': 3}
{'_id': '人工智能', 'avg_age': 48.0, 'count': 1}
{'_id': '大数据技术', 'avg_age': 27.0, 'count': 3}
改(更新
更新单个文档updata_one
for d in c1.find({},{"_id":0}):
print(d)
{'name': 'a11', 'age': 88.0}
{'name': 'aa2', 'age': 99.0}
{'name': 'aa3', 'age': 100.0}
{'name': 'kjfd', 'age': 18, 'major': '大数据技术'}
{'name': 'jasgdkj', 'age': 14, 'major': '大数据技术'}
{'name': 'kadh', 'age': 49, 'major': '大数据技术'}
{'name': 'kagd', 'age': 48, 'major': '人工智能'}
#name为aa3的文档,年龄改为77,#set--修改列值
c1.update_one({"name":"aa3"},{"$set":{"age":77}})#第一个参数为查询条件,参数2为修改表达式
#查询验证
for d in c1.find({"name":"aa3"},{"_id":0}):
print(d)
{'name': 'aa3', 'age': 77}
更新多个文档update_many:更新找到的所有文档
#更新major为大数据技术的文档中的年龄字段,全部加5岁--$inc
q={"major":"大数据技术"}#条件
n_d={"$inc":{"age":5}}#新数据
c1.update_many(q,n_d)
for i in c1.find({},{"_id":0}):
print(i)
{'name': 'a11', 'age': 88.0}
{'name': 'aa2', 'age': 99.0}
{'name': 'aa3', 'age': 77}
{'name': 'kjfd', 'age': 23, 'major': '大数据技术'}
{'name': 'jasgdkj', 'age': 19, 'major': '大数据技术'}
{'name': 'kadh', 'age': 54, 'major': '大数据技术'}
{'name': 'kagd', 'age': 48, 'major': '人工智能'}
删
删除单个文档-delete_one:删除匹配上的第一个文档
#删除name为aa2的文档
c1.delete_one({"name":"aa2"})
for i in c1.find({},{"_id":0}):
print(i)
{'name': 'a11', 'age': 88.0}
{'name': 'aa3', 'age': 77}
{'name': 'kjfd', 'age': 23, 'major': '大数据技术'}
{'name': 'jasgdkj', 'age': 19, 'major': '大数据技术'}
{'name': 'kadh', 'age': 54, 'major': '大数据技术'}
{'name': 'kagd', 'age': 48, 'major': '人工智能'}
删除多个文档-delete_many:删除所有匹配上的文档
#删除name以k开头的文档,需要使用正则表达式匹配
c1.delete_many({"name":{"$regex":"k"}})
for i in c1.find({},{"_id":0}):
print(i)
{'name': 'a11', 'age': 88.0}
{'name': 'aa3', 'age': 77}
删除所有文档-delete_many-查询条件为空即可
其他
#排序--sort():按照年龄进行升序排序
for i in c1.find({},{"_id":0}).sort("age",1):
print(i)
{'name': 'aa3', 'age': 77}
{'name': 'a11', 'age': 88.0}
#限制返回数--limit():只返回指定个数的文档
for i in c1.find({},{"_id":0}).limit(1):
print(i)
{'name': 'a11', 'age': 88.0}
#跳过—skip():跳过指定的文档数,返回剩下的文档
for i in c1.find({},{"_id":0}).skip(1):
print(i)
{'name': 'aa3', 'age': 77}














 1295
1295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









