







kind: Project
apiVersion: api/v1
metadata:
name: sonar # 项目名称
spec:
engine:
sonar: | # 定义编排模板(一般较复杂且核心,因此另建文件管理)
%{readText “_projects/sonar.engine.yaml” | indent 6}%
default: # 设置全局的默认属性
env:
info:
sonar: # 设置所有环境的默认sonar地址和token
url: http://xxx:9090
token: xxx
envs:
prod:
code:
branch: master # 按环境设置默认分支
mvn:
profile: prod # maven管理代码 设置profile为prod
编排模板(_projects/sonar.engine.yaml)内容:
first: &first # 扫描的第一部分代码
sonar:
- name: common
second: &second # 扫描的第二部分代码
sonar:
- name: user
metadata:
annotations:
notify-types: “group,personal”
template: ‘sonar:latest’
spec:
global:
workflow: # 定义工作流信息
parallelism: 256 # 并发任务数
ttlStrategy:
secondsAfterCompletion: 86400 # 结束工作流保留1天时间
secondsAfterSuccess: 86400 # 结束工作流保留1天时间
secondsAfterFailure: 172800 # 失败工作流保留2天时间
kube: # 定义k8s的运行环境信息
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: app
operator: In
values: - ops
tolerations: - key: cattle.io/os
operator: Equal
value: linux
effect: “NoSchedule” - key: app
operator: Equal
value: ops
effect: “NoSchedule”
@{- $part := $.params.annotations.part }@
stages: - name: “sonar”
desc: “代码质量扫描”
modules:
@{- if eq $part “first” }@
<<: *first # 当代码仓库数量很多,而资源又有限时分开扫描
@{- else if eq $part “second” }@
<<: *second # 当代码仓库数量很多,而资源又有限时分开扫描
@{- else if eq $part “bigdata” }@ # 分类扫描:为大数据独立构建工作流
sonar: - name: bigdata
@{- end }@
定义模块
包含内容如图:
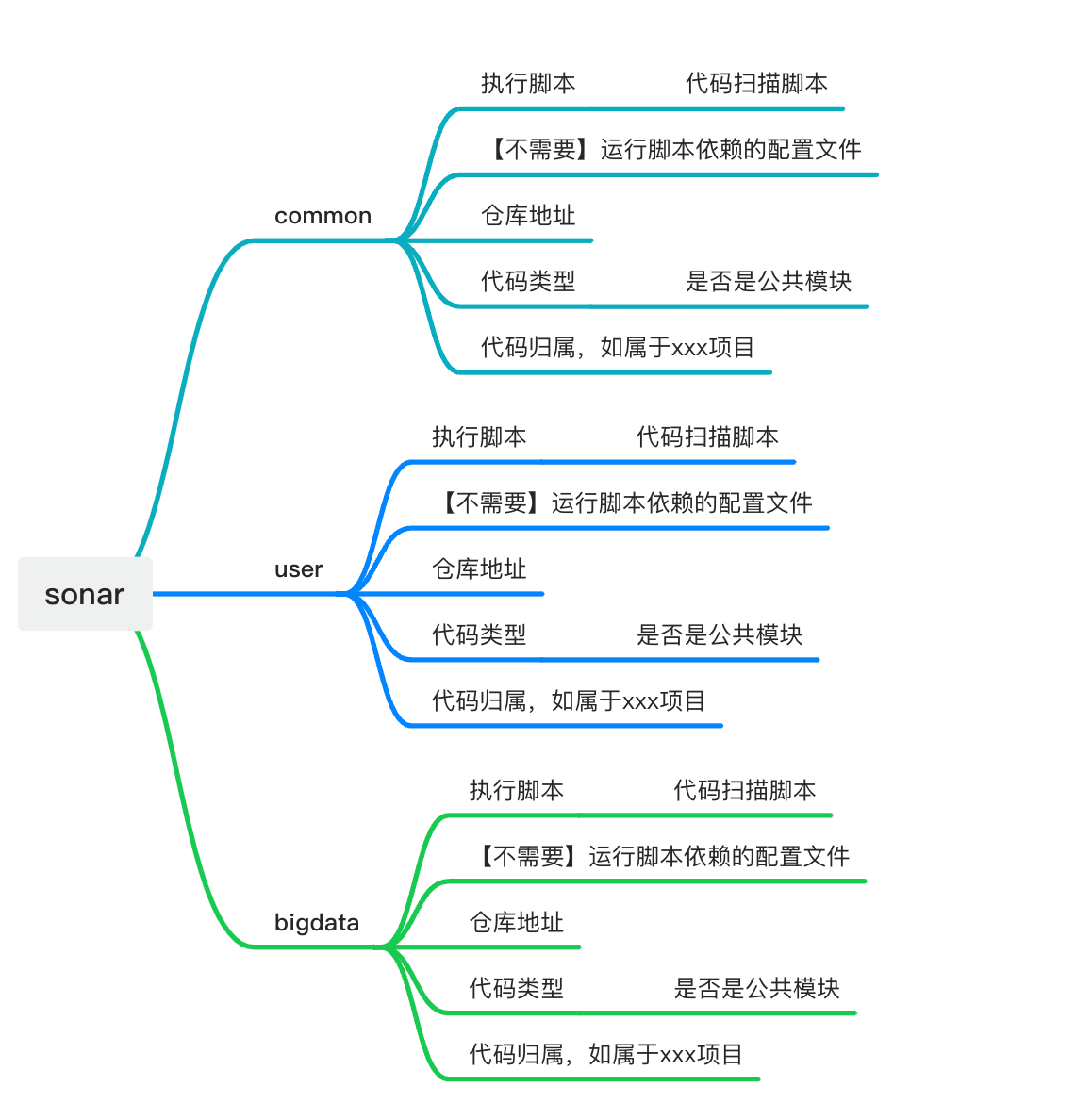
模板内容如下(执行脚本较复杂,也另建文件管理):
sonar:
__global__: # 模块层的全局配置
execTmpl: |
%{readText “code/sca.yaml” | indent 34}%
default: # 模块级的默认配置
type: git # 类型都为git
config: “” # 表示不需要生成配置文件
common:
labels:
package: true # 表示公共库
settings:
repo: http://xxx/common.git
mvn:
api: # 只上传jar包 不打包和构建镜像
dir: “”
sonar:
exclusions: ‘src/main/java/xxx/protobuf/**’ # sonar扫描排除pb代码
user:
labels:
role: user # 属于用户中心;默认(和不填)为公共模块,服务于所有部门;支持多个归属
settings:
repo: http://xxx/user.git
mvn:
api:
dir: user-api
service:
dir: user-service
bigdata:
labels:
role: bigdata # 属于大数据中心;默认(和不填)为公共模块,服务于所有部门;支持多个归属
settings:
repo: http://xxx/bigdata.git
branch: dev
mvn:
api:
dir: flink-stream
sonar:
exclusions: ‘src/main/**/proto/**’
执行脚本模板(code/sca.yaml)如下:
分两步:
1. 下载代码
2. 扫描代码
@{- $env := .env -}@
@{- $repoName := repoName .settings.repo}@
@{- $parent := . }@
- name: git
image: busybox
command: [/bin/sh, -c]
args: - |
echo 下载代码 @{.settings.repo}@ branch:@{ or .settings.tag .settings.branch (render $env.code.branch .) }@
@{- range t y p e , type, type,val := .settings.mvn}@
- name: mvn-sast-@{$type}@
depends: [git]
image: busybox
command: [/bin/sh, -c]
args: - |
echo 代码扫描
@{- $projName := $repoName }@
@{- if $val.dir }@
@{- $projName = concat $projName “:” $val.dir }@
@{- end}@
@{- $projName = replace $projName “/” “:” -1 }@
echo ‘mvn clean package sonar:sonar -DskipTests -U -P @{$env.mvn.profile}@
@{- if (or $parent.settings.sonar.exclusions “”) }@
-Dsonar.exclusions=@{ KaTeX parse error: Expected 'EOF', got '}' at position 34: …nar.exclusions }̲@ \ @{- end}@ -…projName}@
-Dsonar.projectName=SAST:@{KaTeX parse error: Expected 'EOF', got '}' at position 9: projName}̲@ \ -Dsonar.hos…env.info.sonar.url}@
-Dsonar.login=@{$env.info.sonar.token}@’
@{- end }@
执行编排
分两步:
- yaml定义参数
- cli执行
完整的执行脚本(Makefile)如下:
server=http://localhost:8888
OPS_USER需设置环境变量,eg:export OPS_USER=xxx
apply-sonar:
ops apply -p sonar -s ${server} -u ${OPS_USER} -f sonar/project.yaml
ops apply -p sonar -s ${server} -u ${OPS_USER} -f sonar/definitions/main.yaml
#扫描common代码
ops apply -p sonar -s ${server} -u ${OPS_USER} -f sonar/engines/params-common.yaml
#扫描user代码
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!**
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-LgnYFInh-1712514504766)]















 1385
1385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









