







- java gc 可达性分析+垃圾回收器+垃圾回收算法+为什么分代垃圾回收+调优
- 数据库引擎,innodb 索引实现+聚集和非聚集区别+为什么用 b+树不用 hash
- 聊聊 tcp 和 udp 的区别
- http 知道吗?说一下
- http 版本之间的比较
- 让你设计一个 hash 表,怎么设计?
- 时间不多了,手撸一个二分查找
答案解析
本文首发公众号【五分钟学大数据】,可以搜索关注下,超多大数据精品文章
- 自我介绍+项目介绍
自我介绍可以参考美团面试的这篇文章:美团优选大数据开发岗面试题
- 为什么用 kafka、sparkstreaming、hbase?有什么替代方案吗?
根据简历中写的项目,谈谈为什么用这几个框架,是公司大数据平台历史选择还是更适合公司业务。
然后在说下每个框架的优点:
Kafka:
- 高吞吐量、低延迟:kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒;
- 可扩展性:kafka 集群支持热扩展;
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
- 容错性:允许集群中节点故障(若副本数量为 n,则允许 n-1 个节点故障);
- 高并发:支持数千个客户端同时读写。
Kafka 应用场景:
- 日志收集:一个公司可以用 Kafka 可以收集各种服务的 log,通过 kafka 以统一接口服务的方式开放给各种 consumer;
- 消息系统:解耦生产者和消费者、缓存消息等;
- 用户活动跟踪:kafka 经常被用来记录 web 用户或者 app 用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到 kafka 的 topic 中,然后消费者通过订阅这些 topic 来做实时的监控分析,亦可保存到数据库;
- 运营指标:kafka 也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
- 流式处理:比如 spark streaming 和 flink。
Spark Streaming 优点:
- spark streaming 会被转化为 spark 作业执行,由于 spark 作业依赖 DAGScheduler 和 RDD,所以是粗粒度方式而不是细粒度方式,可以快速处理小批量数据,获得准实时的特性;
- 以 spark 作业提交和执行,很方便的实现容错机制;
- DStreaming 是在 RDD 上的抽象,更容易与 RDD 进行交互操作。需要将流式数据与批数据结合分析的情况下,非常方便。
因为我们的业务对实时性要求不是特别高,所以使用 spark streaming 是非常合适的。
HBase 优点:
- HDFS 有高容错,高扩展的特点,而 Hbase 基于 HDFS 实现数据的存储,因此 Hbase 拥有与生俱来的超强的扩展性和吞吐量。
- HBase 采用的是 Key/Value 的存储方式,这意味着,即便面临海量数据的增长,也几乎不会导致查询性能下降。
- HBase 是一个列式数据库,相对于于传统的行式数据库而言。当你的单张表字段很多的时候,可以将相同的列(以 regin 为单位)存在到不同的服务实例上,分散负载压力。
有什么替代方案,就可以聊聊和这几个功能类似的框架,它们的优缺点等,比如 Apache kafka 对应的 Apache Pulsar;Spark Streaming 对应的 Flink;HBase 对应的列式数据库可以举几个例子,如 Cassandra、MongoDB 等。
- 聊聊你觉得大数据的整个体系?
这个是一个开放性题,把你知道的大数据框架都可以说下,下面是我做的一个 Apache 大数据框架的集合图,当然也没有包含全部,只是比较常见的几个:

说的时候尽量按照它们的功能划分及时间先后顺序讲解。
- 你看过 hdfs 源码?nn 的高可用说一下
一个 NameNode 有单点故障的问题,那就配置双 NameNode,配置有两个关键点,一是必须要保证这两个 NN 的元数据信息必须要同步的,二是一个 NN 挂掉之后另一个要立马补上。
- 元数据信息同步在 HA 方案中采用的是“共享存储”。每次写文件时,需要将日志同步写入共享存储,这个步骤成功才能认定写文件成功。然后备份节点定期从共享存储同步日志,以便进行主备切换。
- 监控 NN 状态采用 zookeeper,两个 NN 节点的状态存放在 ZK 中,另外两个 NN 节点分别有一个进程监控程序,实施读取 ZK 中有 NN 的状态,来判断当前的 NN 是不是已经 down 机。如果 standby 的 NN 节点的 ZKFC 发现主节点已经挂掉,那么就会强制给原本的 active NN 节点发送强制关闭请求,之后将备用的 NN 设置为 active。
如果面试官再问 HA 中的 共享存储 是怎么实现的知道吗?
可以进行解释下:NameNode 共享存储方案有很多,比如 Linux HA, VMware FT, QJM 等,目前社区已经把由 Clouderea 公司实现的基于 QJM(Quorum Journal Manager)的方案合并到 HDFS 的 trunk 之中并且作为默认的共享存储实现
基于 QJM 的共享存储系统主要用于保存 EditLog,并不保存 FSImage 文件。FSImage 文件还是在 NameNode 的本地磁盘上。QJM 共享存储的基本思想来自于 Paxos 算法,采用多个称为 JournalNode 的节点组成的 JournalNode 集群来存储 EditLog。每个 JournalNode 保存同样的 EditLog 副本。每次 NameNode 写 EditLog 的时候,除了向本地磁盘写入 EditLog 之外,也会并行地向 JournalNode 集群之中的每一个 JournalNode 发送写请求,只要大多数 (majority) 的 JournalNode 节点返回成功就认为向 JournalNode 集群写入 EditLog 成功。如果有 2N+1 台 JournalNode,那么根据大多数的原则,最多可以容忍有 N 台 JournalNode 节点挂掉
注:Hadoop3.x 允许用户运行多个备用 NameNode。例如,通过配置三个 NameNode 和五个 JournalNode,群集能够容忍两个节点而不是一个节点的故障。
HDFS 的其他内容可看之前写的这篇文章:HDFS 分布式文件系统详解
- zookeeper 简单介绍一下,为什么要用 zk?zk 的架构?zab?
zk 介绍及功能:
Zookeeper 是一个分布式协调服务的开源框架。 主要用来解决分布式集群中应用系统的一致性问题,例如怎样避免同时操作同一数据造成脏读的问题。
ZooKeeper 本质上是一个分布式的小文件存储系统。提供基于类似于文件系统的目录树方式的数据存储,并且可以对树中的节点进行有效管理。从而用来维护和监控你存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。 诸如: 统一命名服务(dubbo)、分布式配置管理(solr 的配置集中管理)、分布式消息队列(sub/pub)、分布式锁、分布式协调等功能。
zk 架构:
zk 架构图:
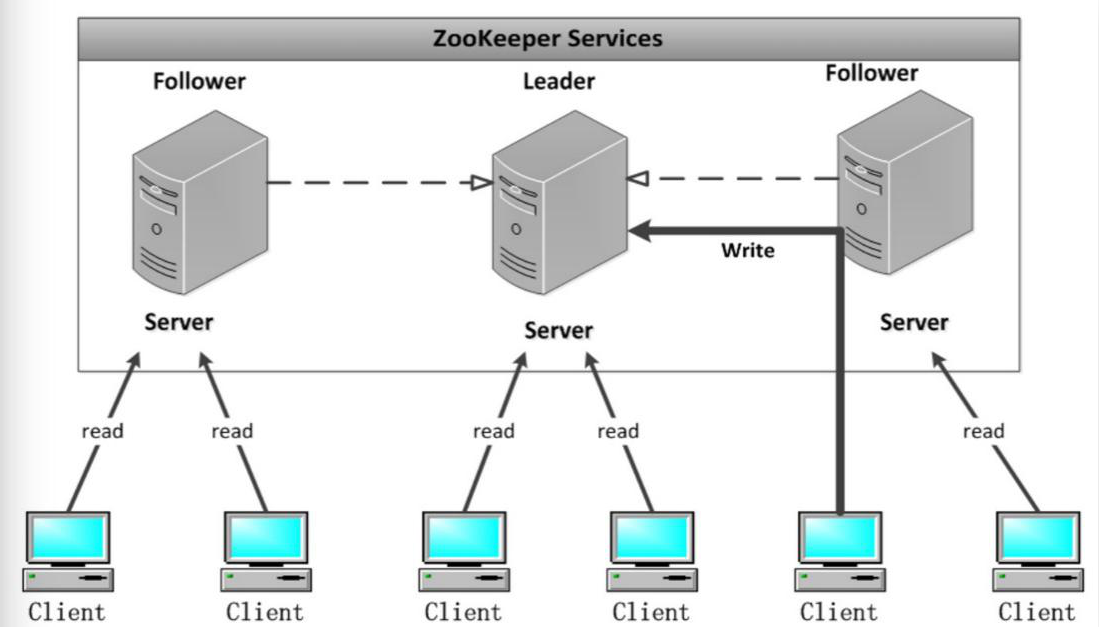
Leader:
Zookeeper 集群工作的核心;
事务请求(写操作) 的唯一调度和处理者,保证集群事务处理的顺序性;
集群内部各个服务器的调度者。
对于 create, setData, delete 等有写操作的请求,则需要统一转发给 leader 处理, leader 需要决定编号、执行操作,这个过程称为一个事务。
Follower:
处理客户端非事务(读操作) 请求,
转发事务请求给 Leader;
参与集群 Leader 选举投票 2n-1 台可以做集群投票。
此外,针对访问量比较大的 zookeeper 集群, 还可新增观察者角色。
Observer:
观察者角色,观察 Zookeeper 集群的最新状态变化并将这些状态同步过来,其对于非事务请求可以进行独立处理,对于事务请求,则会转发给 Leader 服务器进行处理。
不会参与任何形式的投票只提供非事务服务,通常用于在不影响集群事务 处理能力的前提下提升集群的非事务处理能力。
简答:说白了就是增加并发的读请求
ZAB 协议全称:Zookeeper Atomic Broadcast(Zookeeper 原子广播协议)。
ZAB 协议是专门为 zookeeper 实现分布式协调功能而设计。zookeeper 主要是根据 ZAB 协议是实现分布式系统数据一致性。
zookeeper 根据 ZAB 协议建立了主备模型完成 zookeeper 集群中数据的同步。这里所说的主备系统架构模型是指,在 zookeeper 集群中,只有一台 leader 负责处理外部客户端的事物请求(或写操作),然后 leader 服务器将客户端的写操作数据同步到所有的 follower 节点中。
- HBase 的架构,读写缓存?
HBase 的架构可以看这篇文章,非常详细:HBase 底层原理详解
下面说下HBase 的读写缓存:
HBase 的 RegionServer 的缓存主要分为两个部分,分别是MemStore和BlockCache,其中 MemStore 主要用于写缓存,而 BlockCache 用于读缓存。
HBase 执行写操作首先会将数据写入 MemStore,并顺序写入 HLog,等满足一定条件后统一将 MemStore 中数据刷新到磁盘,这种设计可以极大地提升 HBase 的写性能。
不仅如此,MemStore 对于读性能也至关重要,假如没有 MemStore,读取刚写入的数据就需要从文件中通过 IO 查找,这种代价显然是昂贵的!
BlockCache 称为读缓存,HBase 会将一次文件查找的 Block 块缓存到 Cache 中,以便后续同一请求或者邻近数据查找请求,可以直接从内存中获取,避免昂贵的 IO 操作。
- BlockCache 的底层实现?你提到了 LRU 那除了 LRU 还可以有什么方案?
我们知道缓存有三种不同的更新策略,分别是FIFO(先入先出)、LRU(最近最少使用)和 LFU(最近最不常使用)。
HBase 的 block 默认使用的是 LRU 策略:LRUBlockCache。此外还有 BucketCache、SlabCache(此缓存在 0.98 版本已经不被建议使用)
LRUBlockCache 实现机制:
LRUBlockCache 是 HBase 目前默认的 BlockCache 机制,实现机制比较简单。它使用一个 ConcurrentHashMap 管理 BlockKey 到 Block 的映射关系,缓存 Block 只需要将 BlockKey 和对应的 Block 放入该 HashMap 中,查询缓存就根据 BlockKey 从 HashMap 中获取即可。
同时该方案采用严格的 LRU 淘汰算法,当 Block Cache 总量达到一定阈值之后就会启动淘汰机制,最近最少使用的 Block 会被置换出来。在具体的实现细节方面,需要关注几点:
- 缓存分层策略
HBase 在 LRU 缓存基础上,采用了缓存分层设计,将整个 BlockCache 分为三个部分:single-access、mutil-access 和 inMemory。
需要特别注意的是,HBase 系统元数据存放在 InMemory 区,因此设置数据属性 InMemory = true 需要非常谨慎,确保此列族数据量很小且访问频繁,否则有可能会将 hbase.meta 元数据挤出内存,严重影响所有业务性能。
- LRU 淘汰算法实现
系统在每次 cache block 时将 BlockKey 和 Block 放入 HashMap 后都会检查 BlockCache 总量是否达到阈值,如果达到阈值,就会唤醒淘汰线程对 Map 中的 Block 进行淘汰。
系统设置三个 MinMaxPriorityQueue 队列,分别对应上述三个分层,每个队列中的元素按照最近最少被使用排列,系统会优先 poll 出最近最少使用的元素,将其对应的内存释放。可见,三个分层中的 Block 会分别执行 LRU 淘汰算法进行淘汰。
- 聊聊 sparkstreaming 和 flink?flink 流批一体解释一下?
Flink 是标准的实时处理引擎,基于事件驱动。而 Spark Streaming 是微批( Micro-Batch )的模型。
下面就分几个方面介绍两个框架的主要区别:
-
架构模型:
- Spark Streaming 在运行时的主要角色包括:Master、Worker、Driver、Executor;
- Flink 在运行时主要包:Jobmanager、Taskmanager 和 Slot。
-
任务调度:
- Spark Streaming 连续不断的生成微小的数据批次,构建有向无环图 DAG, Spark Streaming 会依次创 DStreamGraph、JobGenerator、JobScheduler;
- Flink 根据用户提交的代码生成 StreamGraph,经过优化生成 JobGraph,然后提交给 JobManager 进行处理, JobManager 会根据 JobGraph 生成 ExecutionGraph,ExecutionGraph 是 Flink 调度最核心的数据结构,JobManager 根据 ExecutionGraph 对 Job 进行调度。
-
时间机制:
- Spark Streaming 支持的时间机制有限,只支持处理时间。
- Flink 支持了流处理程序在时间上的三个定义:处理时间、事件时间、注入时间。同时也支持 watermark 机 制来处理滞后数据。
-
容错机制:
- 对于 Spark Streaming 任务,我们可以设置 checkpoint,然后假如发生故障并重启,我们可以从上次 checkpoint 之处恢复,但是这个行为只能使得数据不丢失,可能 会重复处理,不能做到恰好一次处理语义。
- Flink 则使用两阶段提交协议来解决这个问题。
Flink 的两阶段提交协议具体可以看这篇文章:八张图搞懂 Flink 端到端精准一次处理语义 Exactly-once
- spark 的几种 shuffle 说下?为什么要丢弃 hashshuffle?
前段时间刚写的,可以看下:Spark 的两种核心 Shuffle 详解
- java gc 可达性分析+垃圾回收器+垃圾回收算法+为什么分代垃圾回收+调优
JVM 相关的面试题可看这篇文章,文中第四、五题和本问题相关:精选大数据面试真题 JVM 专项
- 数据库引擎,innodb 索引实现+聚集和非聚集区别+为什么用 b+树不用 hash
innodb 索引实现:
innoDB使用的是聚集索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。
第二步使用主键在主索引B+树中再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
聚集索引和非聚集索引的区别:
- 聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个。
- 聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续。
- 聚集索引:物理存储按照索引排序;聚集索引是一种索引组织形式,索引的键值逻辑顺序决定了表数据行的物理存储顺序。
- 非聚集索引:物理存储不按照索引排序;非聚集索引则就是普通索引了,仅仅只是对数据列创建相应的索引,不影响整个表的物理存储顺序。
- 索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
数据库索引使用B+树原因:
InnoDB采用B+树结构,是因为B+树能够很好地配合磁盘的读写特性,减少单次查询的磁盘访问次数,降低IO、提升性能等。
数据库索引不适合用hash的原因:
-
区间值难找。因为单个值计算会很快,而找区间值,比如 100 < id < 200 就悲催了,需要遍历全部hash节点。
-
排序难。通过hash算法,也就是压缩算法,可能会很大的值和很小的值落在同一个hash桶里,比如一万个数压缩成1000个数存到hash桶里,也就是会产生hash冲突。
-
不支持利用索引完成排序、以及like ‘xxx%’ 这样的部分模糊查询。
-
不支持联合索引的最左前缀匹配规则。
-
聊聊 tcp 和 udp 的区别
简单说下:
- TCP面向连接 (如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接。
- TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付。
Tcp通过校验和,重传控制,序号标识,滑动窗口、确认应答实现可靠传输。如丢包时的重发控制,还可以对次序乱掉的分包进行顺序控制。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
分包进行顺序控制。
[外链图片转存中…(img-iw04A9xv-1714323054784)]
[外链图片转存中…(img-wCWGCZSx-1714323054784)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1728
1728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









