







(1)有序流中内置水位线设置
对于有序流,主要特点就是时间戳单调增长,所以永远不会出现迟到数据的问题。这是周期性生成水位线的最简单的场景,直接调用WatermarkStrategy.forMonotonousTimestamps()方法就可以实现。
public class WatermarkMonoDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction());
// TODO 1.定义Watermark策略
WatermarkStrategy<WaterSensor> watermarkStrategy = WatermarkStrategy
// 1.1 指定watermark生成:升序的watermark,没有等待时间
.<WaterSensor>forMonotonousTimestamps()
// 1.2 指定 时间戳分配器,从数据中提取
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
@Override
public long extractTimestamp(WaterSensor element, long recordTimestamp) {
// 返回的时间戳,要 毫秒
System.out.println("数据=" + element + ",recordTs=" + recordTimestamp);
return element.getTs() * 1000L;
}
});
// TODO 2. 指定 watermark策略
SingleOutputStreamOperator<WaterSensor> sensorDSwithWatermark = sensorDS.assignTimestampsAndWatermarks(watermarkStrategy);
sensorDSwithWatermark.keyBy(sensor -> sensor.getId())
// TODO 3.使用 事件时间语义 的窗口
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(
new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
@Override
public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
long startTs = context.window().getStart();
long endTs = context.window().getEnd();
String windowStart = DateFormatUtils.format(startTs, "yyyy-MM-dd HH:mm:ss.SSS");
String windowEnd = DateFormatUtils.format(endTs, "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect("key=" + s + "的窗口[" + windowStart + "," + windowEnd + ")包含" + count + "条数据===>" + elements.toString());
}
}
)
.print();
env.execute();
}
}
(2)乱序流中内置水位线设置
由于乱序流中需要等待迟到数据到齐,所以必须设置一个固定量的延迟时间。这时生成水位线的时间戳,就是当前数据流中最大的时间戳减去延迟的结果,相当于把表调慢,当前时钟会滞后于数据的最大时间戳。调用WatermarkStrategy. forBoundedOutOfOrderness()方法就可以实现。这个方法需要传入一个maxOutOfOrderness参数,表示“最大乱序程度”,它表示数据流中乱序数据时间戳的最大差值;如果我们能确定乱序程度,那么设置对应时间长度的延迟,就可以等到所有的乱序数据了。
public class WatermarkOutOfOrdernessDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction());
// TODO 1.定义Watermark策略
WatermarkStrategy<WaterSensor> watermarkStrategy = WatermarkStrategy
// 1.1 指定watermark生成:乱序的,等待3s
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
// 1.2 指定 时间戳分配器,从数据中提取
.withTimestampAssigner(
(element, recordTimestamp) -> {
// 返回的时间戳,要 毫秒
System.out.println("数据=" + element + ",recordTs=" + recordTimestamp);
return element.getTs() * 1000L;
});
// TODO 2. 指定 watermark策略
SingleOutputStreamOperator<WaterSensor> sensorDSwithWatermark = sensorDS.assignTimestampsAndWatermarks(watermarkStrategy);
sensorDSwithWatermark.keyBy(sensor -> sensor.getId())
// TODO 3.使用 事件时间语义 的窗口
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(
new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
@Override
public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
long startTs = context.window().getStart();
long endTs = context.window().getEnd();
String windowStart = DateFormatUtils.format(startTs, "yyyy-MM-dd HH:mm:ss.SSS");
String windowEnd = DateFormatUtils.format(endTs, "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect("key=" + s + "的窗口[" + windowStart + "," + windowEnd + ")包含" + count + "条数据===>" + elements.toString());
}
}
)
.print();
env.execute();
}
}
四、自定义水位线生成器
1》周期性水位线生成器(Periodic Generator)
周期性生成器一般是通过onEvent()观察判断输入的事件,而在onPeriodicEmit()里发出水位线。下面是一段自定义周期性生成水位线的代码:
import com.bw.bean.Event;
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
// 自定义水位线的产生
public class CustomPeriodicWatermarkExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env
.addSource(new ClickSource())
.assignTimestampsAndWatermarks(new CustomWatermarkStrategy())
.print();
env.execute();
}
public static class CustomWatermarkStrategy implements WatermarkStrategy<Event> {
@Override
public TimestampAssigner<Event> createTimestampAssigner(TimestampAssignerSupplier.Context context) {
return new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element,long recordTimestamp) {
return element.timestamp; // 告诉程序数据源里的时间戳是哪一个字段
}
};
}
@Override
public WatermarkGenerator<Event> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
return new CustomBoundedOutOfOrdernessGenerator();
}
}
public static class CustomBoundedOutOfOrdernessGenerator implements WatermarkGenerator<Event> {
private Long delayTime = 5000L; // 延迟时间
private Long maxTs = -Long.MAX_VALUE + delayTime + 1L; // 观察到的最大时间戳
@Override
public void onEvent(Event event,long eventTimestamp,WatermarkOutput output) {
// 每来一条数据就调用一次
maxTs = Math.max(event.timestamp,maxTs); // 更新最大时间戳
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 发射水位线,默认200ms调用一次
output.emitWatermark(new Watermark(maxTs - delayTime - 1L));
}
}
}
我们在onPeriodicEmit()里调用output.emitWatermark(),就可以发出水位线了;这个方法由系统框架周期性地调用,默认200ms一次。
如果想修改默认周期时间,可以通过下面方法修改。例如:修改为400ms
env.getConfig().setAutoWatermarkInterval(400L);
2》断点式水位线生成器(PunctuatedGenerator)
断点式生成器会不停地检测onEvent()中的事件,当发现带有水位线信息的事件时,就立即发出水位线。我们把发射水位线的逻辑写在onEvent方法当中即可。
3》在数据源中发送水位线
我们也可以在自定义的数据源中抽取事件时间,然后发送水位线。这里要注意的是,在自定义数据源中发送了水位线以后,就不能再在程序中使用assignTimestampsAndWatermarks方法来生成水位线了。在自定义数据源中生成水位线和在程序中使用assignTimestampsAndWatermarks方法生成水位线二者只能取其一。示例程序如下:
env.fromSource(
kafkaSource, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)), "kafkasource"
)
五、水位线的传递
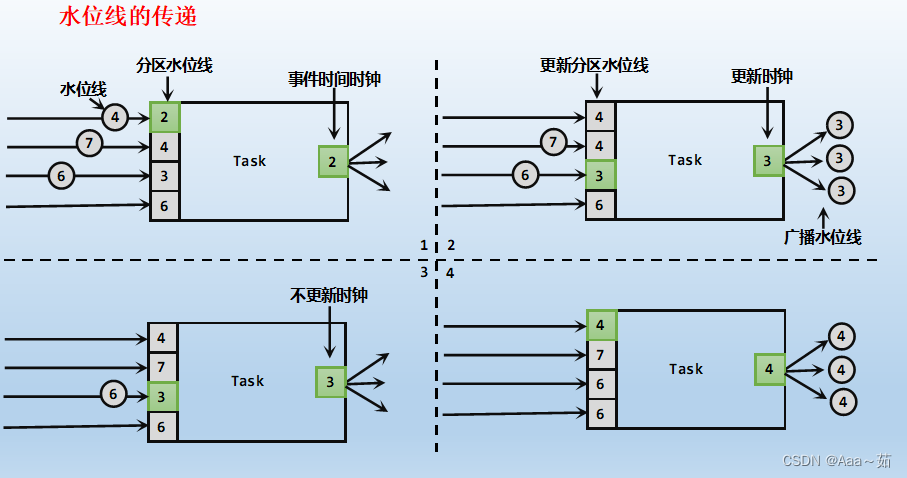
在流处理中,上游任务处理完水位线、时钟改变之后,要把当前的水位线再次发出,广播给所有的下游子任务。而当一个任务接收到多个上游并行任务传递来的水位线时,应该以最小的那个作为当前任务的事件时钟。
水位线在上下游任务之间的传递,非常巧妙地避免了分布式系统中没有统一时钟的问题,每个任务都以“处理完之前所有数据”为标准来确定自己的时钟。
案例:6.3.4.3 中乱序流的watermark,将并行度设为2,观察现象。
在多个上游并行任务中,如果有其中一个没有数据,由于当前Task是以最小的那个作为当前任务的事件时钟,就会导致当前Task的水位线无法推进,就可能导致窗口无法触发。这时候可以设置空闲等待。
用5.3.4.6中的自定义分区器,只输入奇数来模拟部分subtask无数据,代码如下:
public class WatermarkIdlenessDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
// 自定义分区器:数据%分区数,只输入奇数,都只会去往map的一个子任务
SingleOutputStreamOperator<Integer> socketDS = env
.socketTextStream("hadoop102", 7777)
.partitionCustom(new MyPartitioner(), r -> r)
.map(r -> Integer.parseInt(r))
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<Integer>forMonotonousTimestamps()
.withTimestampAssigner((r, ts) -> r * 1000L)
.withIdleness(Duration.ofSeconds(5)) //空闲等待5s
);
// 分成两组: 奇数一组,偶数一组 , 开10s的事件时间滚动窗口
socketDS
.keyBy(r -> r % 2)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new ProcessWindowFunction<Integer, String, Integer, TimeWindow>() {
@Override
public void process(Integer integer, Context context, Iterable<Integer> elements, Collector<String> out) throws Exception {
long startTs = context.window().getStart();
long endTs = context.window().getEnd();
String windowStart = DateFormatUtils.format(startTs, "yyyy-MM-dd HH:mm:ss.SSS");
String windowEnd = DateFormatUtils.format(endTs, "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect("key=" + integer + "的窗口[" + windowStart + "," + windowEnd + ")包含" + count + "条数据===>" + elements.toString());
}
})
.print();
env.execute();
}
}
六、迟到数据的处理
1》推迟水印推进
在水印产生时,设置一个乱序容忍度,推迟系统时间的推进,保证窗口计算被延迟执行,为乱序的数据争取更多的时间进入窗口
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(10));
2》设置窗口延迟关闭
Flink的窗口,也允许迟到数据。当触发了窗口计算后,会先计算当前的结果,但是此时并不会关闭窗口。
以后每来一条迟到数据,就触发一次这条数据所在窗口计算(增量计算)。直到wartermark 超过了窗口结束时间+推迟时间,此时窗口会真正关闭。
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(3))
注意:允许迟到只能运用在event time上
3》使用侧流接收迟到的数据
.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)))
.allowedLateness(Time.seconds(3))
.sideOutputLateData(lateWS)
完整案例代码如下:
public class WatermarkLateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction());
WatermarkStrategy<WaterSensor> watermarkStrategy = WatermarkStrategy
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner((element, recordTimestamp) -> element.getTs() * 1000L);
SingleOutputStreamOperator<WaterSensor> sensorDSwithWatermark = sensorDS.assignTimestampsAndWatermarks(watermarkStrategy);
OutputTag<WaterSensor> lateTag = new OutputTag<>("late-data", Types.POJO(WaterSensor.class));
SingleOutputStreamOperator<String> process = sensorDSwithWatermark.keyBy(sensor -> sensor.getId())
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**





**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)**

**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
...(img-JzZhoWpj-1712962485317)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)**
[外链图片转存中...(img-PB4HsK2g-1712962485317)]
**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1199
1199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









