







再比如,我们根据弹珠的花纹复杂程度来划分,就可以分为3群

我们就可以把它们分为3种,一种无花纹,一种不规则花纹,一种规则花纹。
所以聚类分析虽然是无监督模型,但是你心中要有模型。使用者需要什么结果,他就会产生什么样的变量。
聚类分析的重点有3:
1.我们如何用数字来表示成员间的相似性(或相异性)?
因为我们需要将他们根据这个特点来进行聚类
2.如何根据相似性将类似的成员分在同一群(算法的选择)
3.怎么去描述各群的特征。
实现我们解决第一个问题
如何衡量两笔数据的相似性
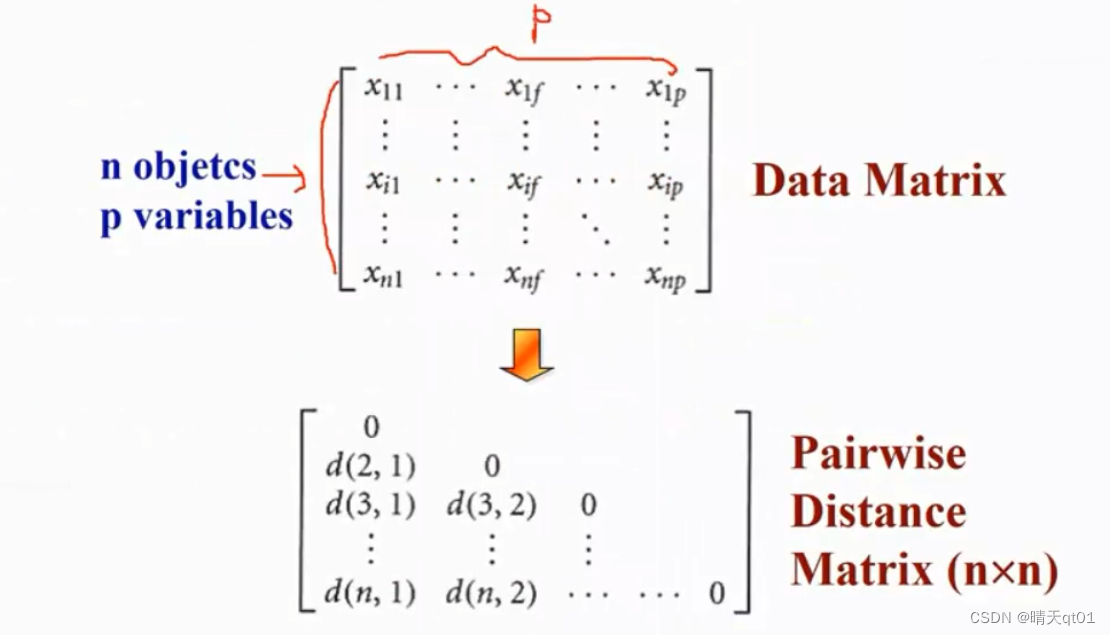
这里有n笔记录,p个字段。这个一般就是我们的数据。接下来我们需要计算它们之间彼此的距离,这里使用的是pairwise的距离,下表是两两一对的距离矩阵。
自己和自己的距离一定是0,说明相似性为百分百,距离越小,相似性越大。所以我们只需要看上三角或者下三角就可以。
距离矩阵的每个距离我们要如何计算?X下面用3种方式进行说明。
二元变量的相似性的衡量方法

这里用的是二变量的两个比较常用的公式,这种二元变量通常使用在推荐系统,有还是没有,有代表顾客对这个商品感兴趣,没有代表顾客对这个商品不感兴趣。这些都是属于二元变量。
在顾客中推荐购买这两种商品的相似度的时候经常用这两个公式。
它们是如何去计算的呢,首先它们需要产生上面的交叉表。Contingency table。需要两个对象i和j我们要看i和j的相似度。
q是代表两个字段都是1的个数,r+s代表一个是1,一个是0的个数(就是二者不相同的个数),tdaib都是0的个数
总共有几笔记录数就是q+r+s+t
我们第一个方法simple Matching coefficient简单比对技术,就是不相同的个数除以总共有几笔数据
第二种方法jaccard和simple Matching coefficient的区别就在于分母,它把分母中t(二者都是0)的情况除去了。分母变为q+r+s
一般第二种方法使用在电商产品,我和你都没购买这个商品,那么能说明这两个商品相似吗,当然不行,可能我们都不知道这个商品。说不定我们知道了就会买
举个案例:
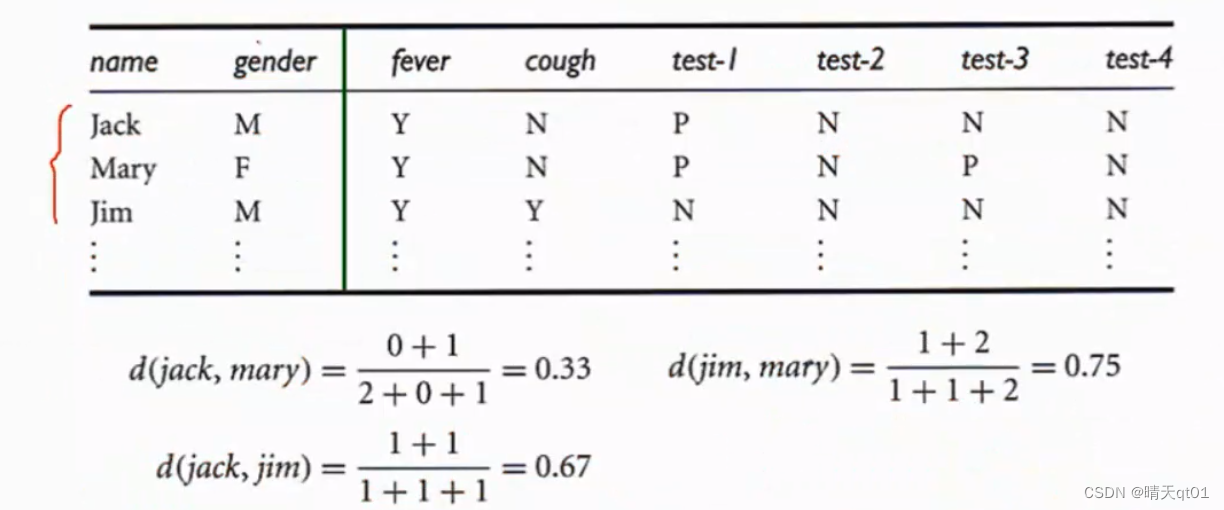
我们现在有3个病人,我们有病人的病症以及做的一些检验。后面的数据代表是否有这个病症。Test中的P代表它是否有这种阳性反应。写N代表阴性反应。
比如我们选择要计算jack和mary的的距离(相异性),Jack的值有可能Y有可能N,mary也有可能N有可能Y
我们画出他们的交叉表,第一个病症都是Y,那么q就加一,两个都是N,那么s加一…….以此类推。
总共有6个字段。不一致的部分是有一个test3.就不一致的部分一共是1,这里的分母采用的是除去都是N的情况,因为都是N可能他们都没去做测试,所以都是N,只是我们不了解具体情况,也有可能检测了就是阳性。我们也不懂。所以我们就把NN的情况排除在外。总数就是2+0+1
1/3来作为jack和mary的距离。其实蛮简单的。
那我们再举一个例子。Mary和jim的例子,它有Y和N,我们发现都是Y的有1个,q=1,两个不一致的有3个,都是N的有2个。
所以他的距离就是3/4.
所以我们认为jim和mary最不可能得到一样的疾病而jack和mary最可能得一样的疾病。
混合类别型变量与数值型变量的的相似性衡量
那如果我们字段里不仅仅只有二元变量,还有身高体重,温度这种数据,也就是混合类别的数据,或者完全都是数值型的字段,身高体重,温度,那么我们需要保证二元变量和身高体重的距离是相同权重的。
数值型的数据有一个好处,他有固定的标尺,数据和数据之间的距离是固定的,比如一公斤和两公斤,两公斤和三公斤的距离就是一样的。
顺序型的数据就不会一样,比如我们对某一幅画的喜欢程度,我们用1= detest(厌恶)2=dislike(不喜欢)3=indifferent(还好)4=like(喜欢)5=admire(很喜欢)。这里你就会发现数字和数字之间的距离是不同的,比如厌恶和不喜欢之间的距离和不喜欢和还好之间的距离其实因人而异。但是距离肯定不一样。
类别型的变量。眼睛的颜色,也可以编码为数字,但是注意这里的数字只是用来代替类别,不能起到数字的作用。还是类别
二元变量就是类别变量的特殊,比如性别。也可以编码为0,1,注意还是看你的应用。
距离的计算
Manhattan distance/City-Block Distance
曼哈顿距离,或者阶梯距离
他们的距离其实就是第一个维度的距离加上第二个维度的距离然后标准化,一般用极值标准化,直角距离
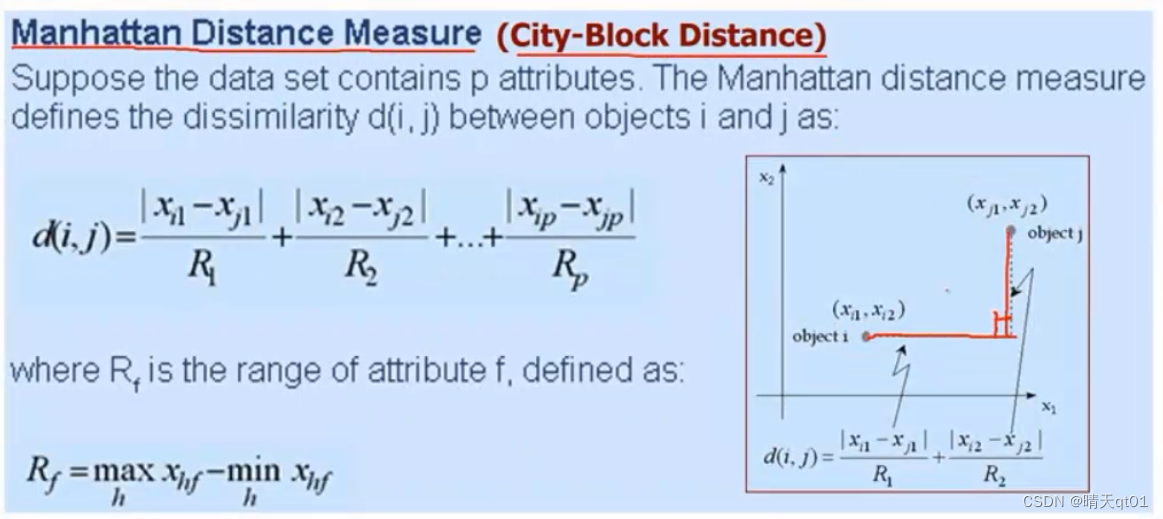
举个案例:

这里有两个人,第一个人年龄20岁,第二个人年龄30岁,第一个顾客收入30000第二个顾客收入50000.
他们之间的距离就是(年龄的差,除以年龄最大值减去最小值)加上(收入的差除以收入最大值减去最小值),也就是1/5+1/5=0.4
-Eucliden Distance
欧式距离:

第一个维度距离的平方加上第二个维度距离的平方……
还是举个例子

说个年龄,用年龄的差除以年龄最大值减去最小值,再把结果平方,加上收入的计算平方,最后把总值开根号。
现在了解距离的计算方法了,我们来看看一个混合数据的计算:

我们还是这两个客户,年龄是数值字段,occupation是职业(二元变量),gender是性别也二元变量,education level教育等级是分类变量,我们对他继续编码,1代表high school 2代表undergraduate 3代表master
我们分别计算各个字段(维度)的距离。
第一个数值字段采用曼哈顿距离,第二个二元变量距离使用相同为1,不同为0的处理方法,分类变量用曼哈顿距离。
最终我们得到二个客户的平均距离,平均距离的公式就是距离之和除以4.(因为都标准化了,所以可以直接除以4),这里得到的是平均曼哈顿距离。
我们用平均距离还有一个好处,我们可以用它来对空值进行填补。或者直接进行计算

这个案例就是没有职业,我们就可以对职业进行忽略,计算出结果,我们求平均距离还是会在0-1之间,所以对结果影响不是很大。然后我们在回头对它进行填补也是可以的。
明天我们在接下来解决剩下两个问题
2.如何根据相似性将类似的成员分在同一群(算法的选择)
3.怎么去描述各群的特征。
明天是我们学习聚类算法的重点
聚类算法的分类

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
img-c3CcND96-1714275114032)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新














 3253
3253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









