







论文信息
SpreadGNN: Serverless Multi-task Federated Learning for Graph Neural Networks

原文链接:SpreadGNN: Serverless Multi-task Federated Learning for Graph Neural Networks:https://arxiv.org/abs/2106.02743
摘要
Graph Neural Networks (GNNs) are the first choice methods for graph machine learning problems thanks to their ability to learn state-of-the-art level representations from graph-structured data. However, centralizing a massive amount of real-world graph data for GNN training is prohibitive due to user-side privacy concerns, regulation restrictions, and commercial competition. Federated Learning is the de-facto standard for collaborative training of machine learning models over many distributed edge devices without the need for centralization. Nevertheless, training graph neural networks in a federated setting is vaguely defined and brings statistical and systems challenges. This work proposes SpreadGNN, a novel multi-task federated training framework capable of operating in the presence of partial labels and absence of a central server for the first time in the literature. SpreadGNN extends federated multi-task learning to realistic serverless settings for GNNs, and utilizes a novel optimization algorithm with a convergence guarantee, Decentralized Periodic Averaging SGD (DPA-SGD), to solve decentralized multi-task learning problems. We empirically demonstrate the efficacy of our framework on a variety of non-I.I.D. distributed graph-level molecular property prediction datasets with partial labels. Our results show that SpreadGNN outperforms GNN models trained over a central server-dependent federated learning system, even in constrained topologies.
图神经网络( GNN )是图机器学习问题的首选方法,因为它们能够从图结构数据中学习最先进的表示。然而,由于用户方面的隐私问题、法规限制和商业竞争,将大量的真实世界图形数据集中用于GNN训练是令人望而却步的。联邦学习是在许多分布式边缘设备上协同训练机器学习模型的事实上的标准,而无需集中化。尽管如此,在联邦环境中训练图神经网络是模糊定义的,并带来统计和系统挑战。本文首次在文献中提出了可以在存在部分标签和没有中心服务器的情况下运行的新型多任务联邦训练框架SpreadGNN。SpreadGNN将联邦多任务学习扩展到GNN的实际无服务器设置,并使用具有收敛保证的新型优化算法- -分布式周期平均SGD ( DPA-SGD )来解决分布式多任务学习问题。我们在多种带有部分标签的非I . I . D .分布式图水平分子性质预测数据集上实证了我们框架的有效性。我们的结果表明,即使在有约束的拓扑结构中,SpreadGNN也优于在中央服务器依赖的联邦学习系统上训练的GNN模型。
SpreadGNN Framework
用于图层次学习的联邦图神经网络
我们寻求在位于边缘服务器的分散图数据集上学习图级别的表示,这些数据集由于隐私和规则限制而无法集中进行训练。例如,分子试验中的化合物可能由于知识产权或监管方面的考虑而无法跨实体共享。在此设置下,我们假设FL网络中有K个客户端,并且每个客户端有自己的数据集。每个客户端都拥有一个带有readout的GNN,以学习图级表示。我们把这个GNN模型设置为一个readout函数和一个graph classifier。多个客户端可以协作改进他们的GNN模型,而不必透露他们的图数据集。在本文中,我们将理论建立在消息传递神经网络( Message Passing Neural Network,MPNN )框架之上,因为大多数空间GNN模型都可以统一到这个框架中。一个MPNN的前向传递有两个阶段:消息传递阶段(式( 1 ) )和更新阶段(式( 2 ) )。对于每个客户端,我们用一个有L层的GNN和一个readout函数来定义图分类器,如下所示:
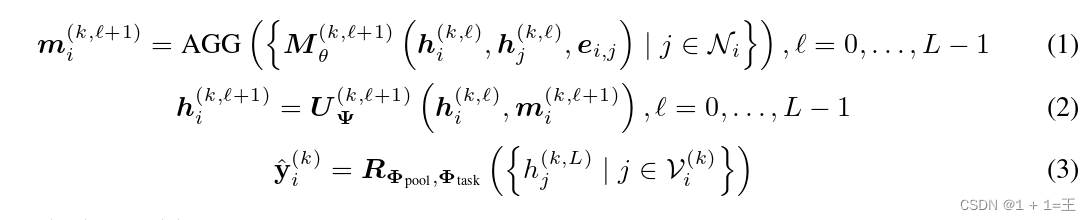
其中,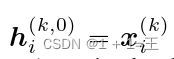 为第k个客户端的节点特征,l为层索引,AGG为聚合方法,Ni表示第i个节点的邻居。
为第k个客户端的节点特征,l为层索引,AGG为聚合方法,Ni表示第i个节点的邻居。
为了构造基于GNN的FL,使用上面的模型定义之外,我们定义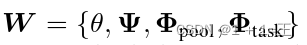 作为总体可学习的权重。注意,W独立于图结构,因为GNN和Readout参数都不对输入图做任何假设。因此,可以使用基于FL的方法学习W。整个FL任务可以表示为一个分布式优化问题:
作为总体可学习的权重。注意,W独立于图结构,因为GNN和Readout参数都不对输入图做任何假设。因此,可以使用基于FL的方法学习W。整个FL任务可以表示为一个分布式优化问题:
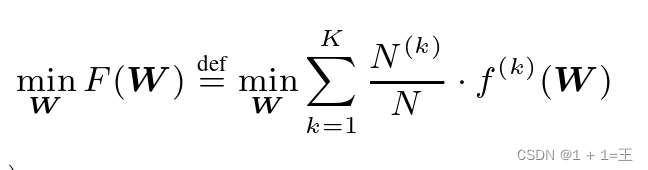
其中,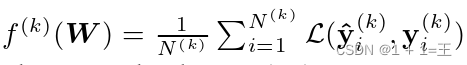 是度量异构图数据集D ( k )上的局部经验风险的第k个客户端的局部目标函数。L是全局图分类器的损失函数。
是度量异构图数据集D ( k )上的局部经验风险的第k个客户端的局部目标函数。L是全局图分类器的损失函数。
有了这样的公式,它可能看起来像是为基于FedAvg的优化器定制的优化问题。不幸的是,在分子图设置中,由于以下原因,情况并非如此。( a )在我们的环境中,客户端属于去中心化的无服务器拓扑。没有一个中心服务器可以从客户端对模型参数进行平均。( b )在我们的场景中,客户具有不完整的标签,因此Φ task的维度在不同的客户上可能不同。例如,一个客户可能只有一个分子的部分毒性标签,而另一个客户可能具有一个分子与另一个药物化合物的相互作用性质。即使每个客户的信息不完整,我们的学习任务也有兴趣在多个标签类别中对每个分子进行分类。联邦多任务学习( FMTL )是一个流行的框架,旨在处理这些问题。然而,目前的方法不能推广到非凸深度模型,如图神经网络。为了解决这些问题,我们首先在第2.2节中介绍一个用于图神经网络的集中式FMTL框架。但是,在由多个相互竞争的实体拥有的分子图中,依赖中央服务器可能是不可行的。因此,我们将这个集中式FMTL增强到第2.3节中的无服务器场景,我们称之为SpreadGNN。
图神经网络的联邦多任务学习
 在正则化MTL范式下,我们定义了如下的集中式联邦图MTL问题( FedGMTL ):
在正则化MTL范式下,我们定义了如下的集中式联邦图MTL问题( FedGMTL ):
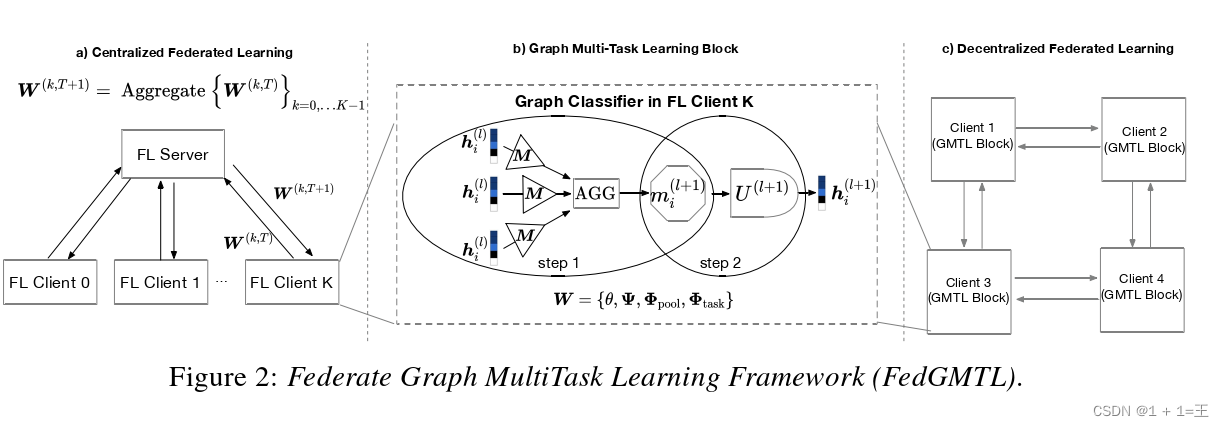
 图2-a描述了客户图分类器权重使用FLserver的FedGMTL框架。虽然上面的公式通过一个可用于GNN学习的受限正则化器增强了FMTL,但我们仍然需要解决最后的挑战,即消除对中央服务器的依赖,以执行公式5中的计算。因此,我们提出了一个去中心化图多任务学习框架SpreadGNN,并利用我们新的优化器去中心化周期平均SGD ( DPA-SGD )来扩展FMTL框架。去中心化框架如图2 - c所示。注意,每个客户机的学习任务保持不变,但SpreadGNN中的聚合过程不同。
图2-a描述了客户图分类器权重使用FLserver的FedGMTL框架。虽然上面的公式通过一个可用于GNN学习的受限正则化器增强了FMTL,但我们仍然需要解决最后的挑战,即消除对中央服务器的依赖,以执行公式5中的计算。因此,我们提出了一个去中心化图多任务学习框架SpreadGNN,并利用我们新的优化器去中心化周期平均SGD ( DPA-SGD )来扩展FMTL框架。去中心化框架如图2 - c所示。注意,每个客户机的学习任务保持不变,但SpreadGNN中的聚合过程不同。
SpreadGNN
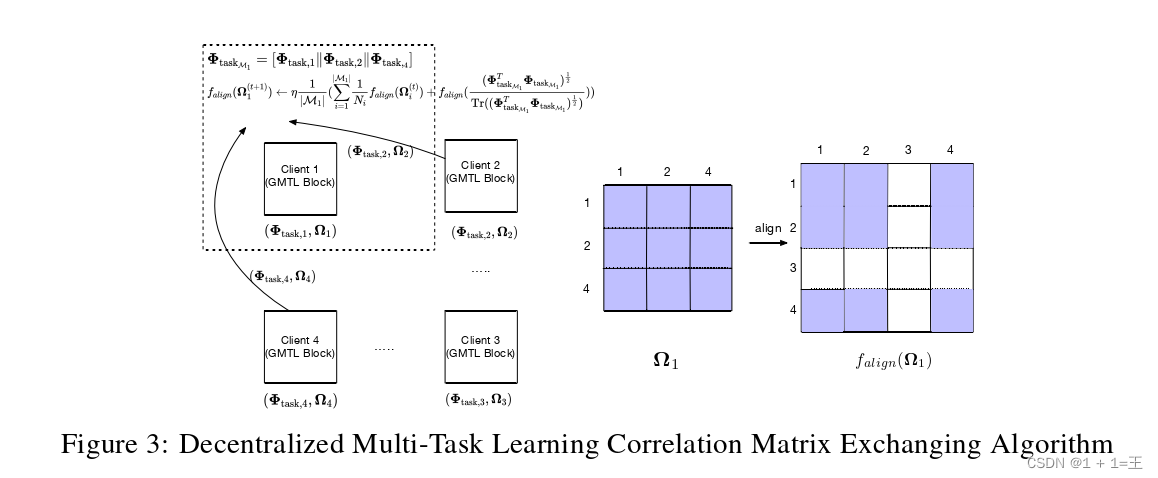
为了过渡到无服务器设置,我们引入了一种新的优化方法,称为去中心化周期平均SGD ( DPA-SGD )。DPA - SGD的主要思想是每个客户机在本地应用SGD,并在每τ次迭代发生的通信轮中仅与邻居同步所有参数。在一个分散的系统中,所有客户端不一定连接到所有其他客户端,这也使得维护一个任务协方差矩阵Ω是不可能的。因此,我们提出使用不同的协方差矩阵Ωkin每个客户端,并使用图3所示的交换机制进行高效更新。我们将这个想法形式化如下。考虑一个特定的客户m有任务权重Φ task,m∈Rd × Sm其中Sm为客户m拥有的任务数。
在去中心化的设置中,我们强调客户端可以集体学习任务的穷举集,即使客户端可能无法访问每个多类标签中的某些类。那么,新的非凸目标函数可以定义为:

 为了解决这个非凸问题,我们应用了文献中提出的交替优化方法,其中W k和Ωk以交替的方式更新。
为了解决这个非凸问题,我们应用了文献中提出的交替优化方法,其中W k和Ωk以交替的方式更新。

第一个平均项可以将附近的节点相关性合并为它自己的相关性。值得注意的是,每个Ωimay具有不同的维度(不同数量的邻居),因此该平均算法是基于全局Ω中的节点对齐。falign函数如图3所示。在这里,对每个客户机执行falign,第二项捕获其邻居之间的新相关性,如图3所示。
DPA-SGD的收敛性质


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
项目、大纲路线、讲解视频,并且后续会持续更新**














 8173
8173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









