







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
hive://hive@{hostname}:{port}/{database}

安装包下载完成,可以测试是否可以连接hive了。
问题1:Could not load database driver: SparkEngineSpec
因为驱动不匹配导致的,返回重新下载依赖包
问题2:无法连接数据库下面的信息
连接数据库的时候一直报无法连接数据库下面的信息,所以我们此时应该重启superset或者关掉superset、关闭hadoop集群,再开启hadoop、superset、登录superset即可。
**问题3:**连接hive,使用superset进行可视化,一旦超过一分钟,直接可视化报错
需要找到并修改config.py文件。我的config.py文件的路径是:
/opt/module/miniconda3/envs/superset/lib/python3.9/site-packages/superset
问题4: 连接SparkSQL时报错,根据官方提示安装pyhive也没用
pip install pyhs2
**问题5:**数据库连接成功,添加数据库表选择下拉数据库表无法获取
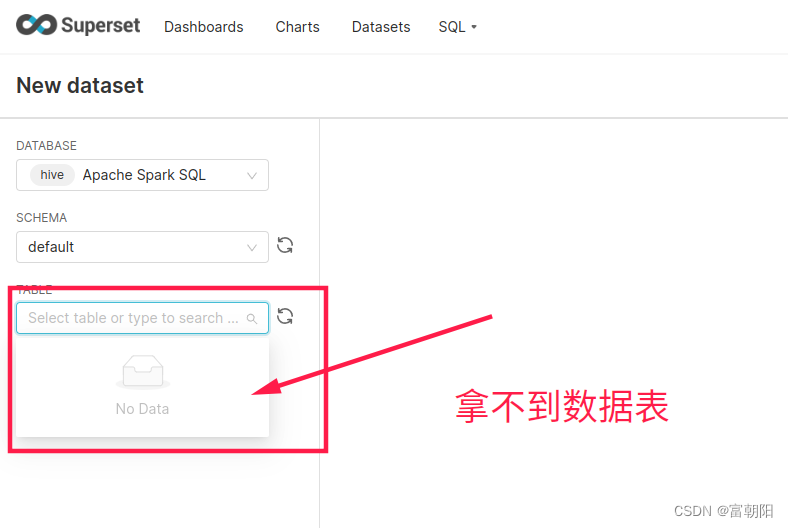
Apache Spark SQL数据结构决定的,无法直接像其他数据库一样查出表,需要手动查表添加,点击SQL Lab,手动查表保存
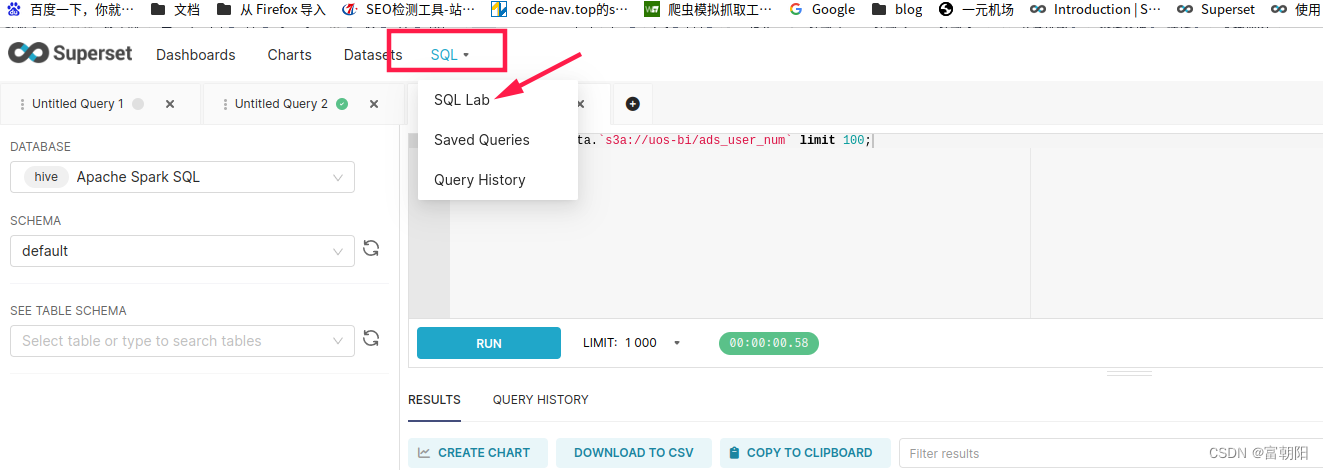
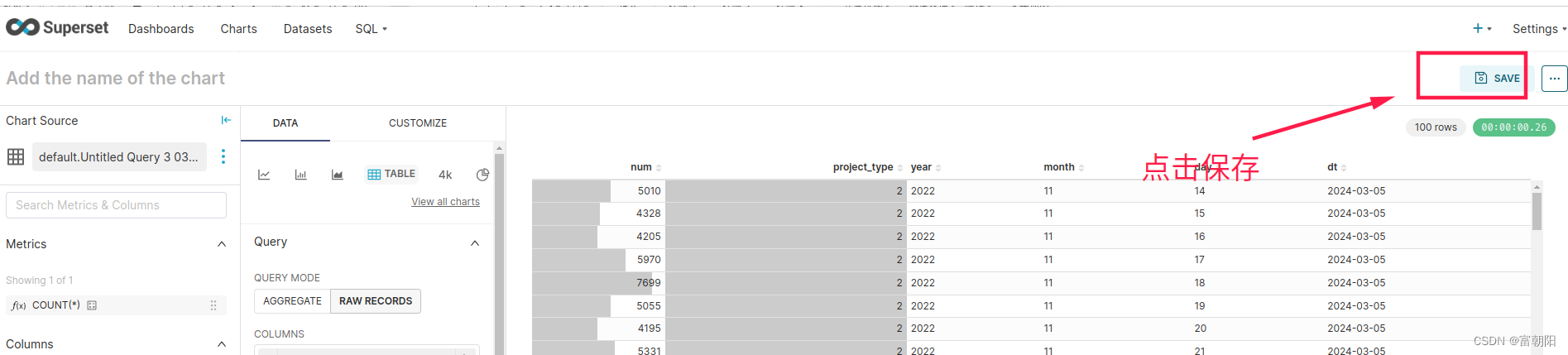
按以下步骤

再点击保存
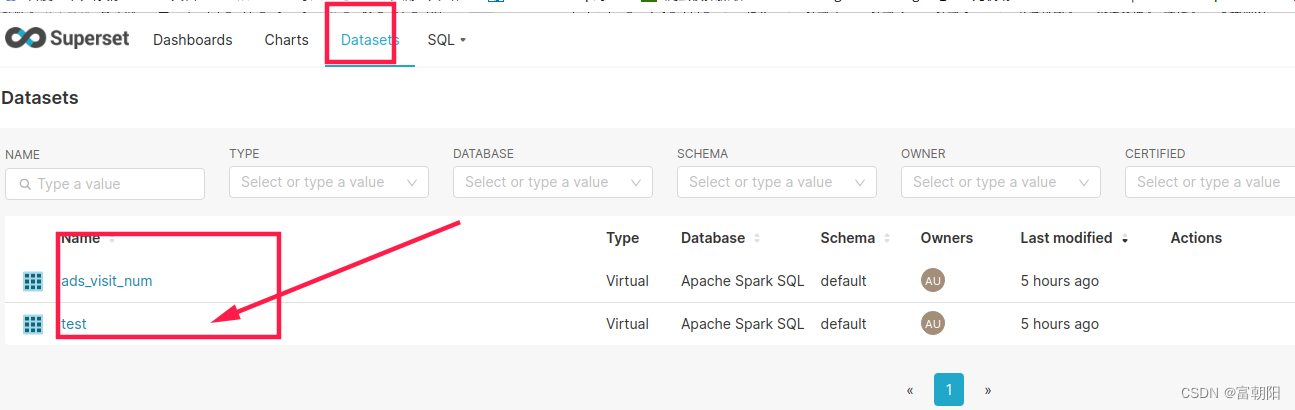
返回Datasets就能看到表了
今天就介绍到这里啦!希望能帮大家避坑!欢迎在评论区交流。如果文章对你有所帮助,**❤️关注+点赞❤️鼓励一下!**博主会持续更新。。。。
往期回顾

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**















 1968
1968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









