







celeborn.master.port 9097
celeborn.metrics.enabled true
celeborn.worker.flusher.buffer.size 256k
If Celeborn workers have local disks and HDFS. Following configs should be added.
If Celeborn workers have local disks, use following config.
Disk type is HDD by defaut.
#celeborn.worker.storage.dirs /mnt/disk1:disktype=SSD,/mnt/disk2:disktype=SSD
If Celeborn workers don’t have local disks. You can use HDFS.
Do not set celeborn.worker.storage.dirs and use following configs.
celeborn.storage.activeTypes HDFS
celeborn.worker.sortPartition.threads 64
celeborn.worker.commitFiles.timeout 240s
celeborn.worker.commitFiles.threads 128
celeborn.master.slot.assign.policy roundrobin
celeborn.rpc.askTimeout 240s
celeborn.worker.flusher.hdfs.buffer.size 4m
celeborn.storage.hdfs.dir hdfs://10.67.78.xx:8020/celeborn
celeborn.worker.replicate.fastFail.duration 240s
If your hosts have disk raid or use lvm, set celeborn.worker.monitor.disk.enabled to false
celeborn.worker.monitor.disk.enabled false
### 4.复制到其他节点
scp -r /root/apache-celeborn-0.3.2-incubating-bin 10.67.78.xx1:/root/
scp -r /root/apache-celeborn-0.3.2-incubating-bin 10.67.78.xx2:/root/
因为在配置文件中已经配置了master 所以启动matster和worker即可。
### **5.启动master和worker**
cd $CELEBORN_HOME
./sbin/start-master.sh
./sbin/start-worker.sh celeborn://:
**之后在master的日志中看woker是否注册上**
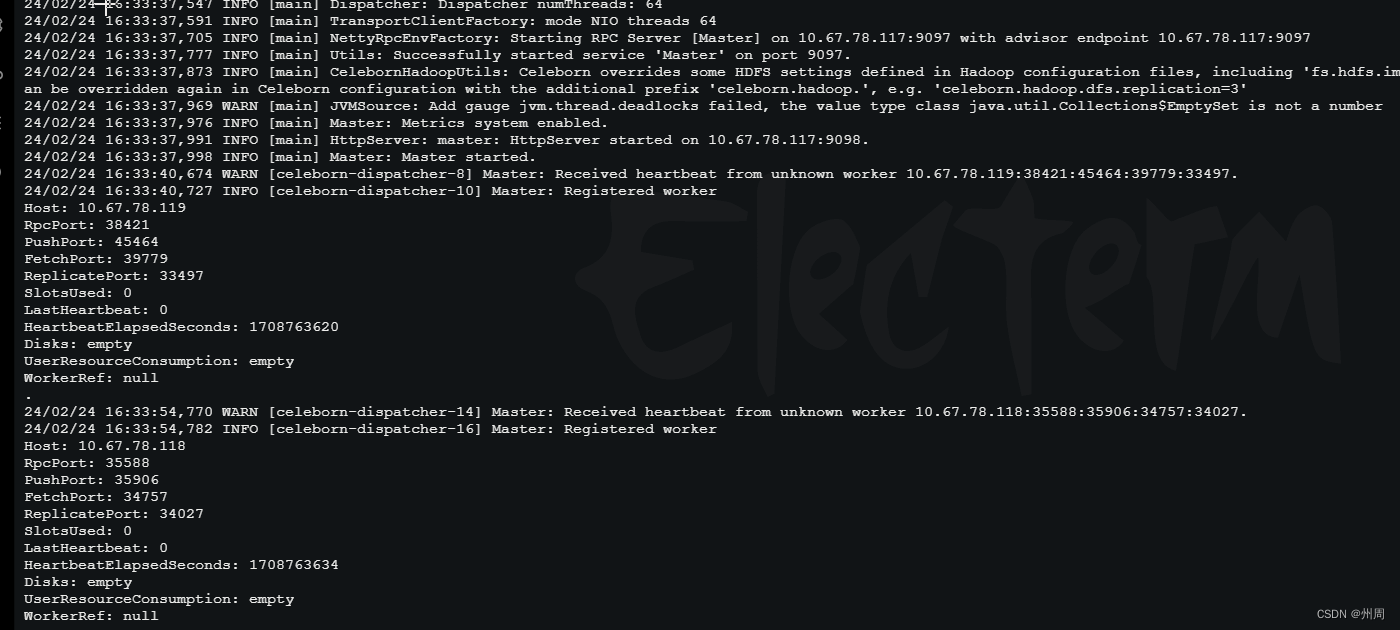
### 6.在 spark客户端使用
**复制 $CELEBORN\_HOME/spark/\*.jar 到 $SPARK\_HOME/jars/**
**修改spark-defaults.conf**
Shuffle manager class name changed in 0.3.0:
before 0.3.0: org.apache.spark.shuffle.celeborn.RssShuffleManager
since 0.3.0: org.apache.spark.shuffle.celeborn.SparkShuffleManager
spark.shuffle.manager org.apache.spark.shuffle.celeborn.SparkShuffleManager
must use kryo serializer because java serializer do not support relocation
spark.serializer org.apache.spark.serializer.KryoSerializer
celeborn master
spark.celeborn.master.endpoints clb-1:9097,clb-2:9097,clb-3:9097
This is not necessary if your Spark external shuffle service is Spark 3.1 or newer
spark.shuffle.service.enabled false
options: hash, sort
Hash shuffle writer use (partition count) * (celeborn.push.buffer.max.size) * (spark.executor.cores) memory.
Sort shuffle writer uses less memory than hash shuffle writer, if your shuffle partition count is large, try to use sort hash writer.
spark.celeborn.client.spark.shuffle.writer hash
We recommend setting spark.celeborn.client.push.replicate.enabled to true to enable server-side data replication
If you have only one worker, this setting must be false
If your Celeborn is using HDFS, it’s recommended to set this setting to false
spark.celeborn.client.push.replicate.enabled true
Support for Spark AQE only tested under Spark 3
we recommend setting localShuffleReader to false to get better performance of Celeborn
spark.sql.adaptive.localShuffleReader.enabled false
If Celeborn is using HDFS
spark.celeborn.storage.hdfs.dir hdfs:///celeborn
we recommend enabling aqe support to gain better performance
spark.sql.adaptive.enabled true
spark.sql.adaptive.skewJoin.enabled true
Support Spark Dynamic Resource Allocation
Required Spark version >= 3.5.0 注意spark版本是否满足
spark.shuffle.sort.io.plugin.class org.apache.spark.shuffle.celeborn.CelebornShuffleDataIO
Required Spark version >= 3.4.0, highly recommended to disable 注意spark版本是否满足
spark.dynamicAllocation.shuffleTracking.enabled false


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
s/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









