








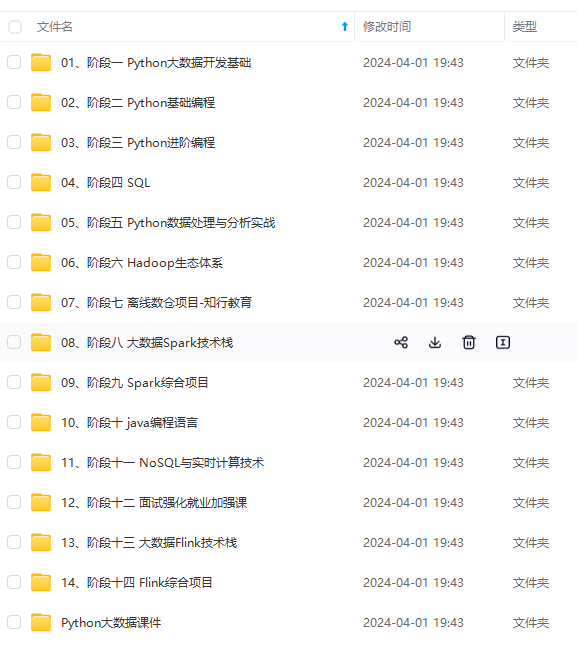
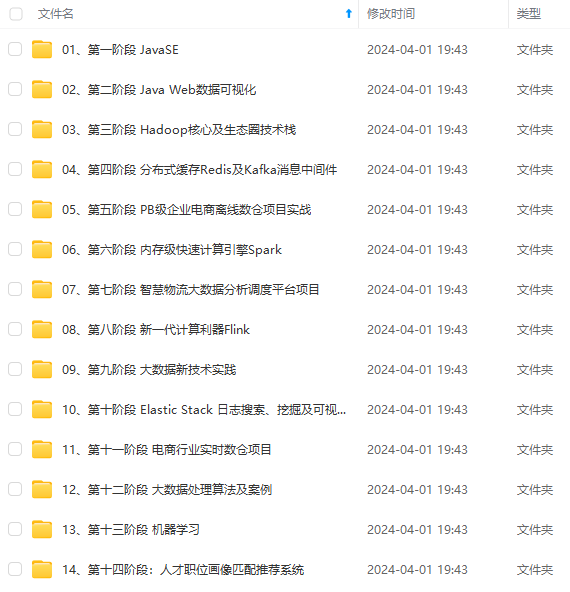
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
- Python共享队列
from multiprocessing import Manager
queue = manager.Queue(maxsize=16384)
当你执行queue.put(data)操作时,如果队列已满(即队列中的元素数量已经达到maxsize指定的数量),那么PUT操作会被阻塞,也就是说这一行代码会被暂时挂起不往下执行,直到队列中有元素被取走,队列有足够的空间放入新的元素,put操作才会继续执行并把元素放入队列。
需要注意的是,put方法还有一个可选参数block,默认为True。当block=False时,如果队列已满,put操作将会立即抛出queue.Full异常,而不会发生阻塞。
- “消费和心跳是在同一个线程中进行的,心跳会强制中断消费吗?”
不会。在Kafka客户端的设计中,消费消息(即poll操作)和发送心跳是在同一个线程中进行的,但这并不意味着心跳会强制中断消息消费操作。
在Kafka Consumer的实现中,心跳发送采用了轮询的方式,即只有当执行poll操作时,才可能会发送心跳。而大部分的时间,线程都在执行消息消费操作,因此并不会被心跳操作强制中断。只有当消息消费完毕,线程进入轮询时,心跳操作才可能被执行。
但是,如果消息消费速度太慢,或者每一次消费的消息数(由
max.poll.records控制)过大,导致一次poll操作的处理时间过长,可能会导致在一段时间内(由session.timeout.ms控制)没有发送任何心跳给Kafka Broker,此时Kafka Broker便会误以为该Consumer已经离线,从而触发了rebalance操作,重新分配partition。
5. “下游的kafka数据很多时,会影响上游的kafka数据生产吗?”
一般来说,下游(消费者)对Kafka数据的消费速度,不会直接影响到上游(生产者)对Kafka的数据生产。因为在Kafka的设计中,生产者和消费者是解耦和的,各自基于自己的缓冲策略和处理速率进行处理。

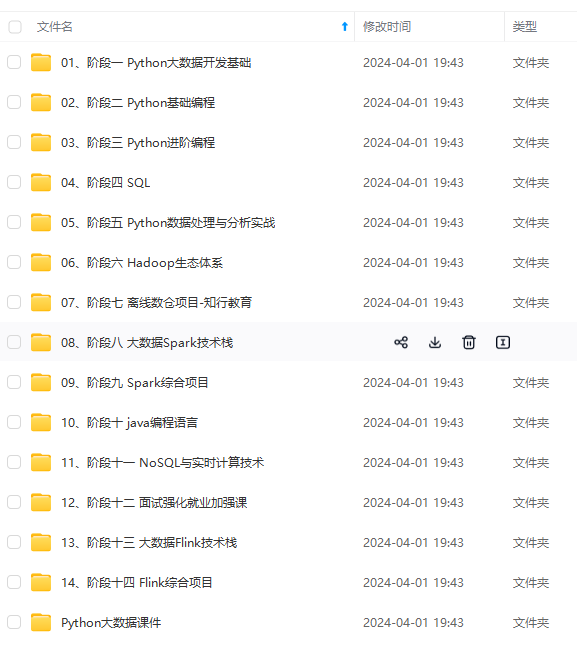
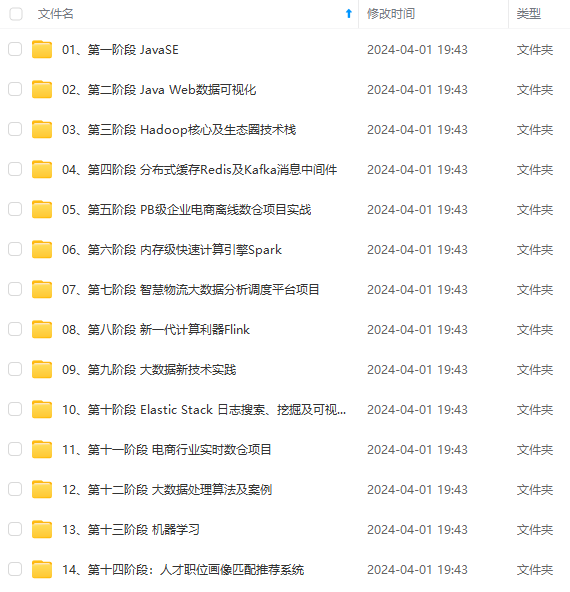
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 1355
1355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









