









网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
4.1 下载安装包
Hadoop国外服务器来下载太慢了,本文选用从国内清华镜像站
在命令行下输入如下命令
wgethttps://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz

图 6 下载安装文件
4.2 解压文件并放置到适当的位置
一般将用户自己安装的程序放在**/usr/local/目录下,为了便于管理,我们统一创建/usr/local/bda/目录,并将此目录(及其子目录)的所有者改为hadoop**
sudo mkdir /usr/local/bda
sudo chown -R hadoop:hadoop /usr/local/bda
cd ~ # 切换回hadoop用户的home目录
tar xzvf hadoop-2.10.1.tar.gz
如图7所示。
注意:如果提示找不到 tar 命令,则需要先安装,如下面命令所示:
sudo yum install tar
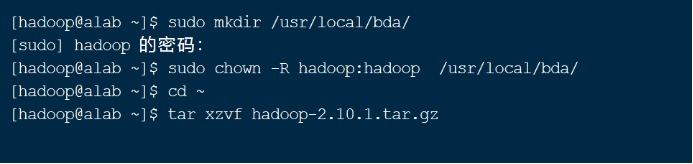
图 7 创建目录、解压安装文件
将解压后的文件夹移动到**/usr/local/bda/**目录下,并改名
mv ~/hadoop-2.10.1 /usr/local/bda/hadoop
4.3 配置Hadoop的配置文件
Hadoop 2.x主要由HDFS、yarn、MapReduce三部分组成,因此总共有5个文件需要进行配置,分别是:
- hadoop-env.sh:Hadoop运行环境
- core-site.xml:集群全局参数
- hdfs-site.xml:HDFS的配置
- yarn-site.xml:集群资源管理系统参数
- mapred-site.xml:MapReduce的参数
以下详细介绍。
需要说明的是:在执行完本节(4.3)的配置后,实际上完成的是整个Hadoop的配置(含MapReduce、YARN)而不仅仅是HDFS的配置。
4.3.1 建立Hadoop所需的目录
我们需要有一个思想就是Linux系统内的所有东西,皆文件的思想,那么我们部署hadoop系统,也是要建立相关目录文件,因为HDFS、MapReduce正常工作,需要一些专用的目录的辅助。因此在开始配置之前,需要建立相应的文件夹,如下
mkdir /usr/local/bda/hadoop/tmp
mkdir /usr/local/bda/hadoop/var
mkdir /usr/local/bda/hadoop/dfs
mkdir /usr/local/bda/hadoop/dfs/name
mkdir /usr/local/bda/hadoop/dfs/data
4.3.2 配置hadoop-env.sh
Hadoop系统环境,只需要配置一个环境变量:JAVA_HOME,也就是告诉Hadoop系统,java的安装位置,使用如下命令打开配置文件:
vim /usr/local/bda/hadoop/etc/hadoop/hadoop-env.sh
进行如下修改,然后保存、退出。

图 8 hadoop-env.sh文件的修改
4.3.3 配置core-site.xml
vim /usr/local/bda/hadoop/etc/hadoop/core-site.xml
将如下内容添加到core-site.xml文件configure中:
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/bda/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
说明:此处进行了两项配置,(1)配置了hadoop的临时目录;(2)配置了文件系统缺省的主机和端口。因为是伪分布式系统,所以此处的主机名是localhost
配置以后的core-site.xml文件,如下图所示:
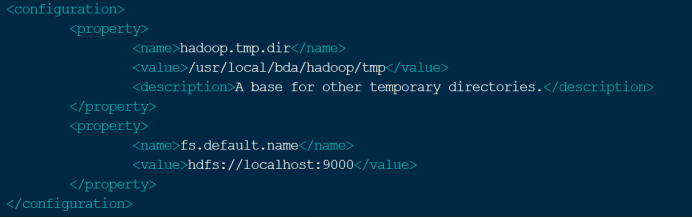
图 9 core-site.xml文件的配置
4.3.4 配置hdfs-site.xml
vim /usr/local/bda/hadoop/etc/hadoop/hdfs-site.xml
进行如下图的配置,各项的说明见下图中的红字,保存,退出
<configuration>
<property>
<name>dfs.name.dir </name>
<value>/usr/local/bda/hadoop/dfs/name </value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/local/bda/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks. </description>
</property>
<property>
<name>dfs.replication </name>
<value>1</value>
</property>
</configuration>

图 10 hdfs-site.xml文件的配置
4.3.5 配置mapred-site.xml
首先,将mapred-site.xml的配置模板文件mapred-site.xml.template复制一份,并命名为mapred-site.xml

然后用vim打开进行编辑
vim /usr/local/bda/hadoop/etc/hadoop/mapred-site.xml
配置内容如下图所示,保存、退出
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/usr/local/bda/hadoop/var</value>
</property>
</configuration>

图 11 mapred-site.xml文件的配置
4.3.6 配置yarn-site.xml
vim /usr/local/bda/hadoop/etc/hadoop/yarn-site.xml
配置内容如下图所示,保存、退出
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
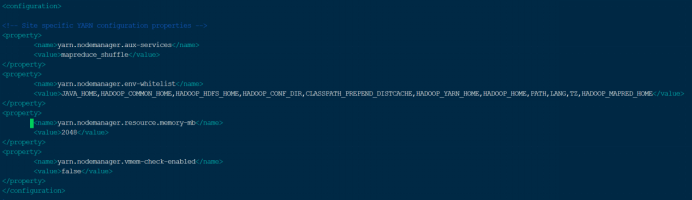
图 12 yarn-site.xml文件的配置
4.4 HDFS文件系统格式化及服务启动、关闭
4.4.1 HDFS文件系统格式化
如同其它的文件系统一样,HDFS在使用之前也要先进行格式化操作,使用如下的命令进行
/usr/local/bda/hadoop/bin/hdfs namenode -format

图 13 执行HDFS格式化命令后的部分输出信息
如图13所示,执行HDFS文件系统格式化命令后,会有较大的输出信息,可以检查是否有ERROR信息。
4.4.2 启动HDFS服务及验证
(1)启动DFS服务
输入如下命令,启动dfs服务,如图14所示。/usr/local/bda/hadoop/sbin/start-dfs.sh
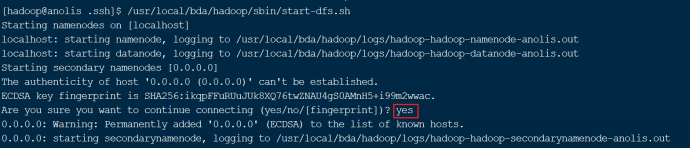
图 14 启动DFS服务
注意,首次启动后,需要输入如图中红框所示的yes。其后再次启动则无需输入。
(2)检查服务进程是否正常
输入jps 命令,查看相关进程是否正常
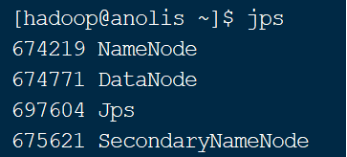
图 15 查看当前的java进程
jps命令的作用是查看当前系统中正在运行的java进程。如图15所示,执行完start-dfs.sh脚本后正常情况下有3个HDFS的进程,一个是NameNode进程,一个是DataNode进程,还有一个是SecondaryNameNode进程。除此之外还有jps进程自己。
(3)访问hdfs的http服务端口
HDFS提供了http服务端口,可以通过浏览器访问,但是需要注意的是,为了访问该端口,需要在防火墙上打开该端口,或者直接关闭防火墙。以下图16中,先检查防火墙状态,发现出于打开的状态,则禁用防火墙,并关闭防火墙。

图 16 防火墙状态检查及关闭
关闭防火墙端口后,就可以在windows系统打开浏览器,地址栏中输入虚拟机的“小网IP”及HDFS的http服务端口(2.x版本是50070)
所以当我的hdfs运行起来之后,通过浏览器 http://192.168.80.130:50070/
前面的192.168.80.130 是我虚拟机的ip
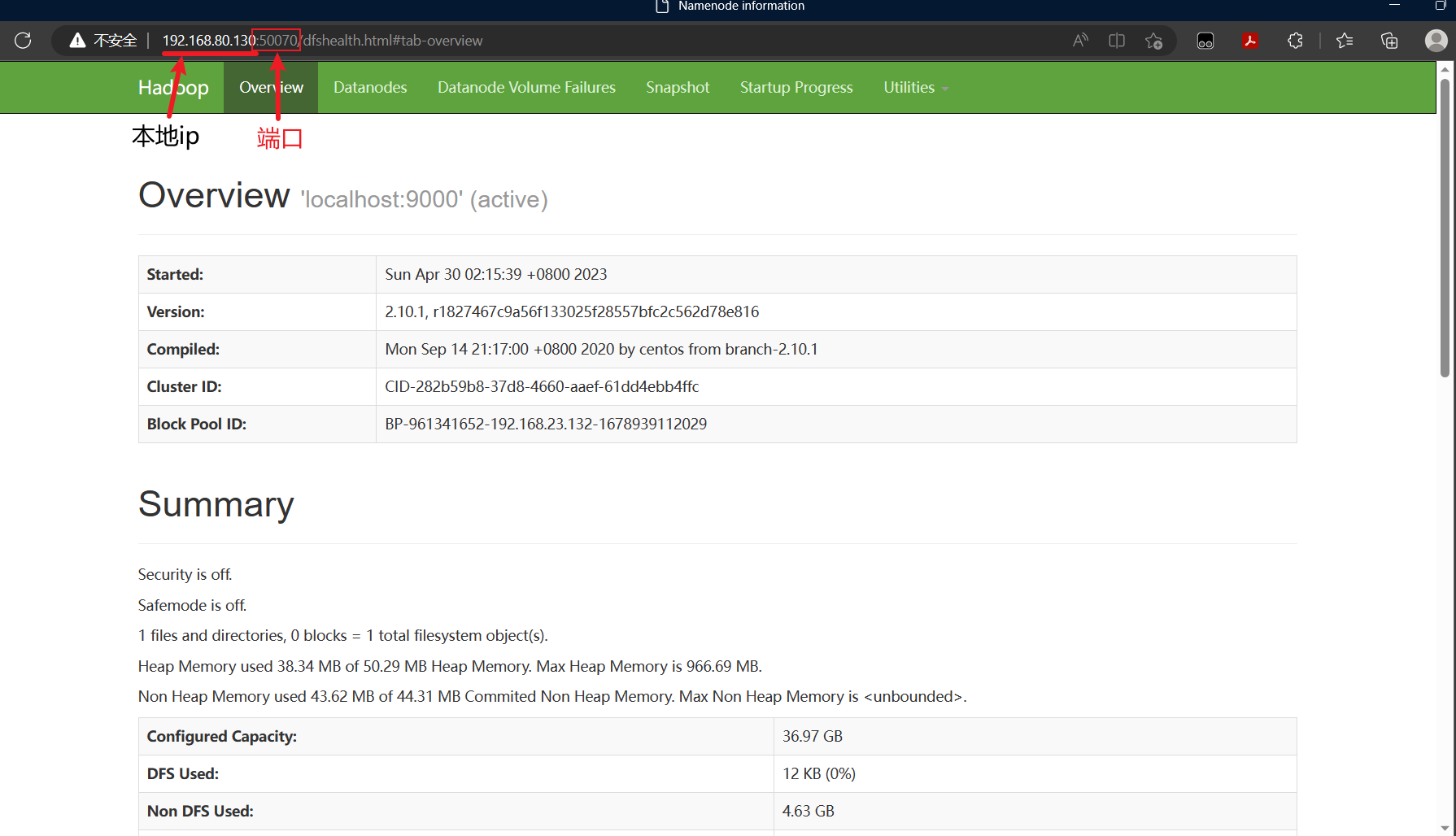
图 17 通过浏览器访问HDFS的http服务
4.4.3 停止HDFS服务
/usr/local/bda/hadoop/sbin/stop-dfs.sh
特别注意:在关闭服务器之前,一定要先使用stop-dfs.sh命令停止HDFS文件系统,如果不执行该命令,直接进行服务器的关机操作,则HDFS系统很容易受到损坏。
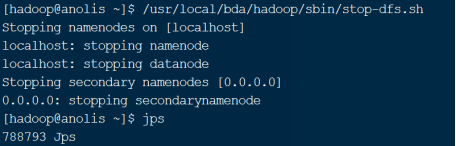
图 18 停止HDFS服务并使用jps命令检查
4.5 YARN服务启动及关闭

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
a69a1be7c91ac8005ce70.png)
图 18 停止HDFS服务并使用jps命令检查
4.5 YARN服务启动及关闭
[外链图片转存中…(img-dGjVpHjs-1715153146231)]
[外链图片转存中…(img-oWVArtqK-1715153146231)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 881
881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









