







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

■ 分类问题与回归问题区别
对于一个回归问题,从简单到复杂,可以采取的模型有多层感知机、SVR、回归森林算法等,下面将介绍如何使用这些算法完成这一任务。
01、使用MLP实现房价预测
首先是载入需要的各种包以及数据集,与前面使用树模型等不同的地方在于,使用多层感知机模型需要对数据集的X和y都根据最大最小值进行归一化处理。下图所示程序使用了线性归一化的方法,即

这种归一化方法比较适用在数值比较集中的情况。这种方法有个缺陷,如max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定,实际使用中可以用经验常量值来替代max和min。
sklearn库中提供了归一化的接口,如代码清单1所示为加载数据集并进行归一化处理的代码实现。
代码清单1 加载数据集并进行预处理操作
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from sklearn.neural_network import MLPRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error
# 加载数据集并进行归一化预处理
def loadDataSet():
boston_dataset = load_boston()
X = boston_dataset.data
y = boston_dataset.target
y = y.reshape(-1, 1)
# 将数据划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 分别初始化对特征和目标值的标准化器
ss_X, ss_y = preprocessing.MinMaxScaler(), preprocessing.MinMaxScaler()
# 分别对训练和测试数据的特征以及目标值进行标准化处理
X_train, y_train = ss_X.fit_transform(X_train), ss_y.fit_transform(y_train)
X_test, y_test = ss_X.transform(X_test), ss_y.transform(y_test)
y_train, y_test = y_train.reshape(-1, ), y_test.reshape(-1, )
return X_train, X_test, y_train, y_test
在预处理过数据集后,构建MLP模型,并设置模型的超参数,并在训练集上训练模型。
代码清单2 训练多层感知机模型
def trainMLP(X_train, y_train):
model_mlp = MLPRegressor(
hidden_layer_sizes=(20, 1), activation='logistic', solver='adam', alpha=0.0001, batch_size='auto',
learning_rate='constant', learning_rate_init=0.001, power_t=0.5, max_iter=5000, shuffle=True,
random_state=1, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True,
early_stopping=False, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model_mlp.fit(X_train, y_train)
return model_mlp
如代码清单2所示,该模型的超参数较多,最重要的几个超参数为hidden_layer_sizes(隐藏层神经元个数,在本次实验当中隐藏层分别为5和1),activations(激活函数,可以选择relu、logistic、tanh等),solver(优化方法,即sgd、adam等),以及与优化方法相关的learning_rate(学习率),momentum(动量)等,设置完模型参数后,使用fit函数完成训练过程。
代码清单3 测试模型效果
def test(model, X_test, y_test):
y_pre = model.predict(X_test)
print("The mean root mean square error of MLP-Model is {}".format(mean_squared_error(y_test, y_pre)**0.5))
print("The mean squared error of MLP-Model is {}".format(mean_squared_error(y_test, y_pre)))
print("The mean absolute error of MLP-Model is {}".format(mean_absolute_error(y_test, y_pre)))
训练完成后在测试集上验证模型的效果,如代码清单3所示,不同于分类模型有准确率召回率等指标,回归模型验证模型效果通常采用MSE,MAE、RMSE等。
- MSE(Mean Squared Error)叫做均方误差

- MAE(Mean Absolute Error)为平均绝对误差,是绝对误差的平均值,能更好地反映预测值误差的实际情况
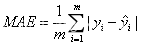
- RMSE(Root Mean Square Error)为均方根误差,是用来衡量观测值同真值之间的偏差

以上三项指标的值越小,则表示在测试集上预测的结果与真实结果之间的偏差越小,模型拟合效果越好。
如代码清单4所示,在主函数中依次调用上述函数,完成导入数据集、训练、预测的全过程。
代码清单4 构建main函数
if __name__ == '__main__':
X_train, X_test, y_train, y_test = loadDataSet()
# 训练MLP模型
model = trainMLP(X_train, y_train)
test(model, X_test, y_test)
最终可得输出如下图1所示。

图1 MLP模型预测效果
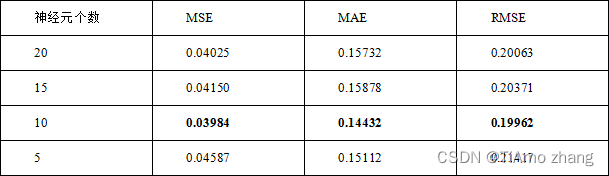
改变实验中的超参数,例如隐藏层的神经元个数,可以得到不同的模型以及这些模型在测试集上的得分。如表2所示,当神经元个数为10时,三项指标均获得了最小值,因此可以固定神经元个数为10,再调整其他参数,例如激活函数、优化方法等。
【小技巧】在难以确定参数时,可以将模型在训练集和测试集的误差都打印出来,当训练集误差远远大于测试集误差时,可能会存在过拟合的问题,应当减少参数数目,即神经元的个数。当训练集的误差与测试集误差都很大时,存在欠拟合的问题,应当增加神经元的个数。
表2 不同神经元个数的预测结果
02、使用随机森林模型实现房价预测
如代码清单5、代码清单6所示,导入与随机森林回归模型有关的包,并新增使用随机森林训练模型的函数,修改主函数,其他部分保持不变。
代码清单5 使用随机森林模型进行训练
def trainRF(X_train, y_train):
model_rf = RandomForestRegressor(n_estimators=10000)
model_rf.fit(X_train, y_train)
return model_rf
代码清单6 修改main函数内容

**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
...(img-56pGjySw-1714975433587)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**















 415
415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









