







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
添加如下配置:
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile %h/.ssh/authorized_keys # 公钥文件路径
4.虚拟机关机,克隆虚拟机创建bigdata02、bigdata03节点:

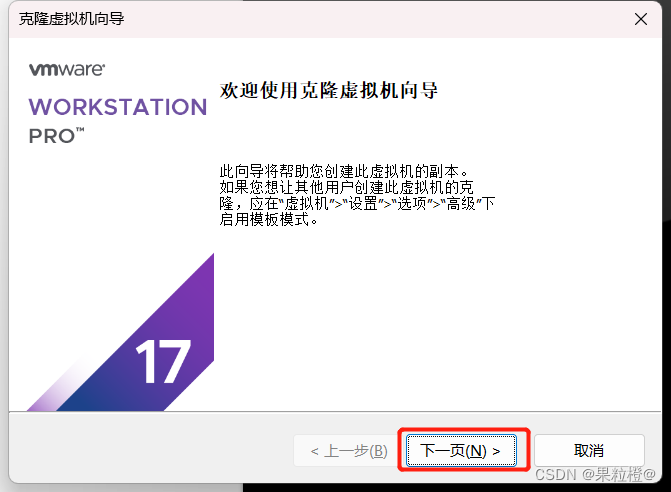

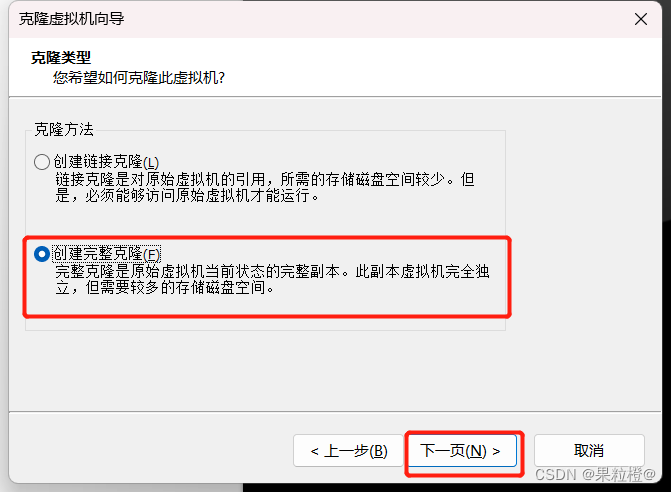

同样的方式创建bigdata03节点这里不再进行演示。
5.开机,三个节点修改主机名:
vim /etc/hostname
修改完成后需要重启虚拟机。
6.三个节点设置静态ip(之前博客有发这里不再进行演示)。
7.三个节点设置ip映射:
vim /etc/hosts
在文件底部作出如下配置:
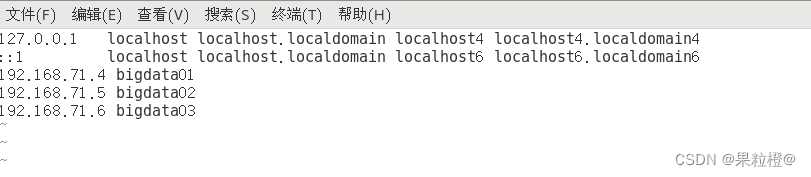
8.三个节点都测试⼀下配置是否成功:
ssh bigdata01
ssh bigdata02
ssh bigdata03
执行结果如下:

准备完毕!
### 三、配置hadoop完全分布式
1.在/opt/module/hadoop/etc/hadoop/目录下,编辑hadoop-env.sh、yarn-env.sh、mapred-env.sh文件:
vim hadoop-env.sh
vim yarn-env.sh
vim mapred-env.sh
均添加如下配置:
export JAVA_HOME=/opt/module/jdk
2.在/opt/module/hadoop/etc/hadoop/目录下,编辑core-site.xml文件:
vim core-site.xml
在<configuration>下添加如下配置:
3.在/opt/module/hadoop/etc/hadoop/目录下,编辑hdfs-site.xml文件:
vim hdfs-site.xml
在下添加如下配置:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/module/hadoop/dfs/data</value>
</property>
4.在/opt/module/hadoop/etc/hadoop/目录下,编辑yarn-site.xml文件:
vim yarn-site.xml
在下添加如下配置:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata01</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
5.在/opt/module/hadoop/etc/hadoop/目录下,编辑mapred-site.xml文件:
vim mapred-site.xml
在下添加如下配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop</value>
</property>
6.在/opt/module/hadoop/etc/hadoop/目录下,编辑works:
vim workers
删除原配置,添加如下配置:
bigdata01
bigdata02
bigdata03
7.在/etc/profile下配置hadoop的HDSF和YARN⽤户:
vim /etc/profile
在文件底部添加如下配置:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
8.source使配置⽂件⽣效:
source /etc/profile
9.将hadoop和将/etc/profile拷⻉到bigdata02和bigdata03:
scp -r /opt/module/hadoop/ @bigdata02:/opt/module/
scp -r /opt/module/hadoop/ @bigdata03:/opt/module/
scp -r /etc/profile @bigdata02:/etc/
scp -r /etc/profile @bigdata03:/etc/
10.格式化namenode:
hdfs namenode -format
执行结果如下:
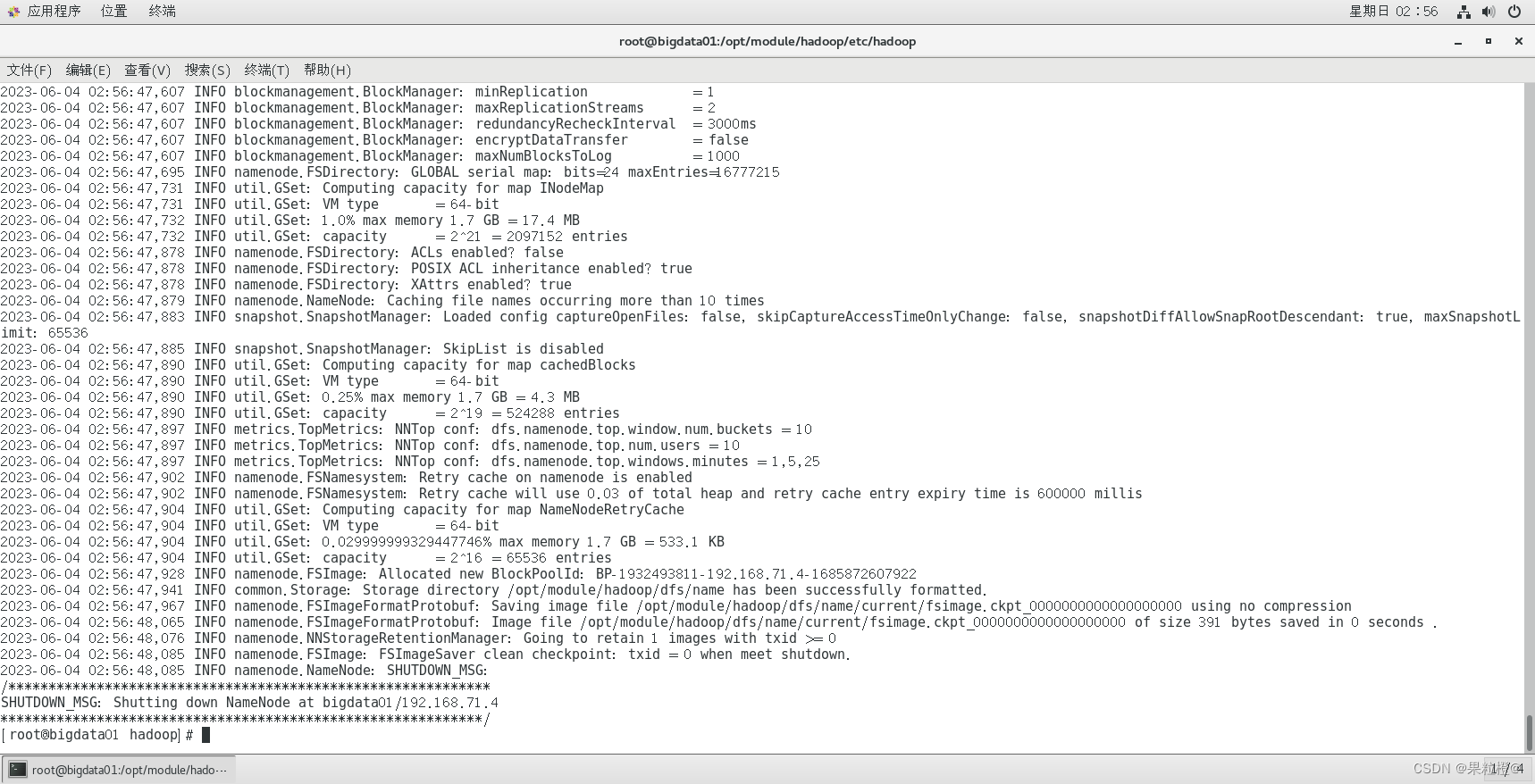
11.启动hadoop集群:

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
[外链图片转存中…(img-Y2GrFhkX-1715794716055)]
[外链图片转存中…(img-AwPXrsJx-1715794716056)]
[外链图片转存中…(img-8lbpFZJ3-1715794716056)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 5140
5140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









