







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。




既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
Kafka组成
- Topic:主题,Kafka处理的消息的不同分类。
- Broker:消息代理,Kafka集群中的一个kafka服务节点称为一个broker,主要存储消息数据。存在硬盘中每个topic都是有分区的。
- Partition:Topic物理上的分组,一个topic在broker中被分为1个或者多个partition,分区在创建topic的时候指定。
- Replica:数据副本,可以为保存在Kafka中的数据指定副本数,以提高数据冗余性,防止数据丢失;
- Message:消息,是通信的基本单位,每个消息都属于一个partition
Kafka服务相关
- Producer:消息和数据的生产者,向Kafka的一个topic发布消息。
- Consumer:消息和数据的消费者,定于topic并处理其发布的消息。
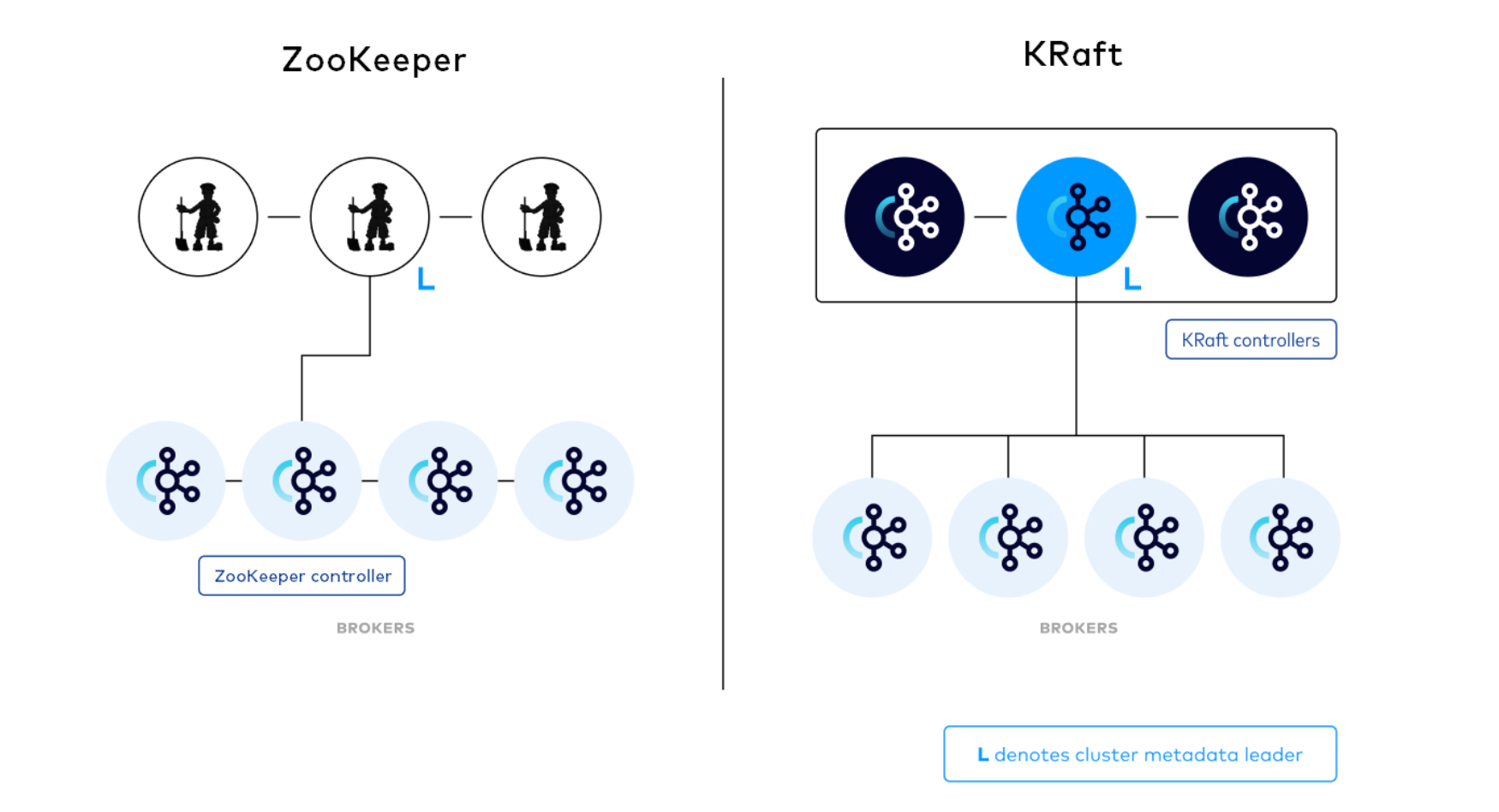
- Zookeeper:协调kafka的正常运行。
- KRaft:Kafka的KRaft模式在2.8.0版本中被引入。从2.8.0版本开始,Kafka提供了对KRaft的支持,其中最大的变化之一就是不再依赖外部的ZooKeeper来管理Kafka的元数据。因此,如果你使用2.8.0版本或更高版本的Kafka,你将能够使用KRaft模式,无需安装和配置ZooKeeper。
Kafka架构设计
一个典型的Kafka集群包含若干个生产者(Producer)、若干Kafka集群节点(Broker)、若干消费者(Consumer)以及一个Zookeeper集群或者KRaft模式。Kafka通过Zookeeper管理集群配置,选举Leader以及在消费者发生变化时进行负载均衡。生产者使用推(Push)模式将消息发布到集群节点,而消费者使用拉(Pull)模式从集群节点中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1487
1487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









