







一、写在前面🎈
大家好!我是初心,今天给大家带来的是Hadoop HA搭建保姆级教程,来自大二学长的万字长文自述和笔记!
相信很多人看到这个标题时,可能会产生一种疑问:博主你之前不是出过一期关于Hadoop HA高可用集群搭建的教程了吗,这次怎么还出一篇?是有什么改进的地方吗?
没错!本次将给大家带来更加详细的搭建教程以及解释! 希望能帮助大家更好的理解Hadoop HA集群。
老规矩,还是先介绍一下自己吧!(该走的流程不能少,嘿嘿嘿)
🏠 个人主页:初心%个人主页 🍺
🧑 个人简介:大家好,我是初心,和大家共同努力 🍺
💕 每日金句分享:迄今所有人生都大写着失败,但并不妨碍我继续向前。——狂铁《王者荣耀》🍺
💕欢迎大家:这里是CSDN,我记录知识的地方,喜欢的话请三连,有问题请私信😘
话不多说,就让我们一起进入正题吧!
二、集群准备🍟
这是我们本次搭建要完成的集群规划,也就是我们的,终极目标(The ultimate goal)。
2.1 集群规划

也就是说,总共有hadoop102,hadoop103,hadoop104,hadoop105四个节点。先来一张搭建好的图证明一下我搭建好了:
- 停止集群
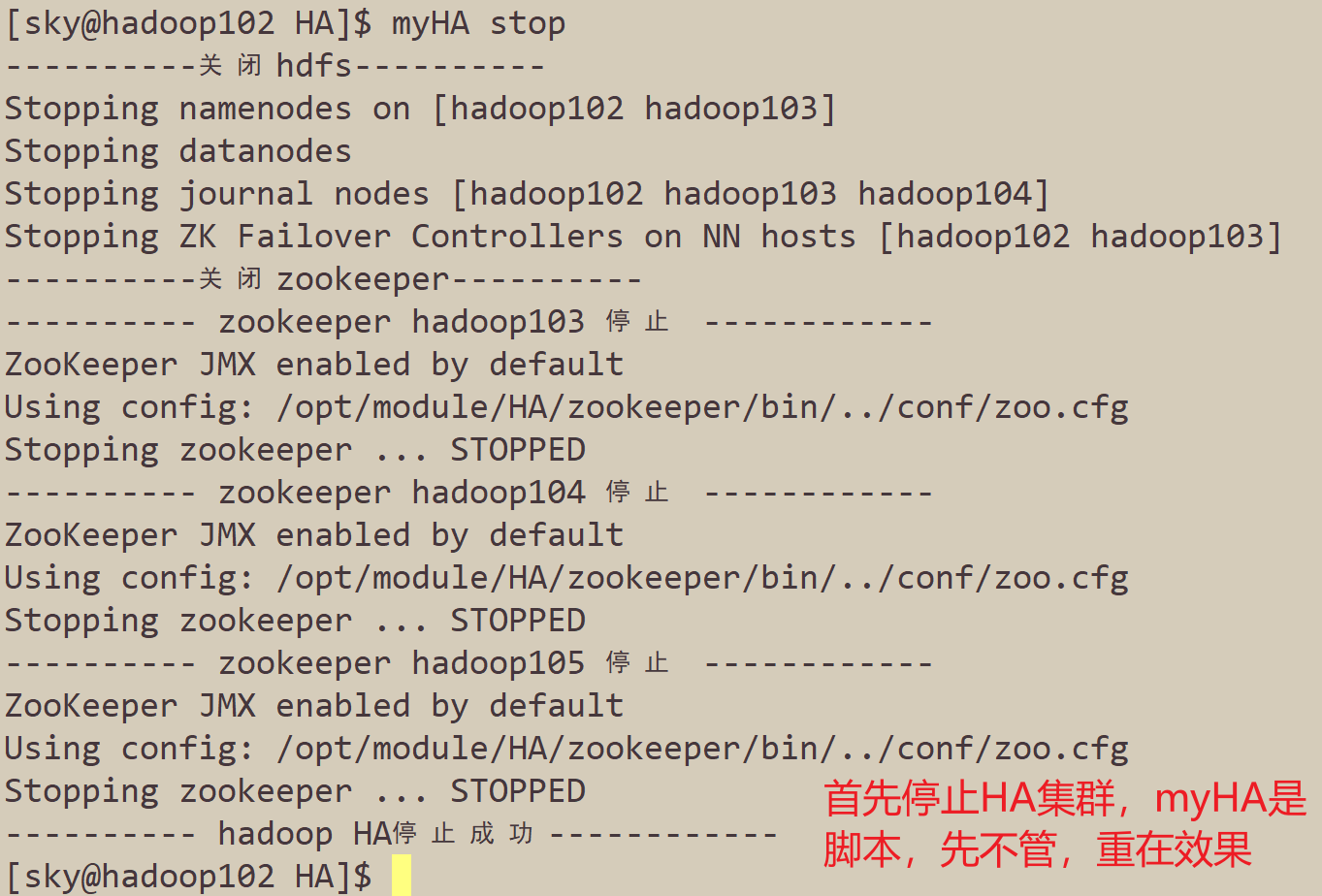
- 启动集群
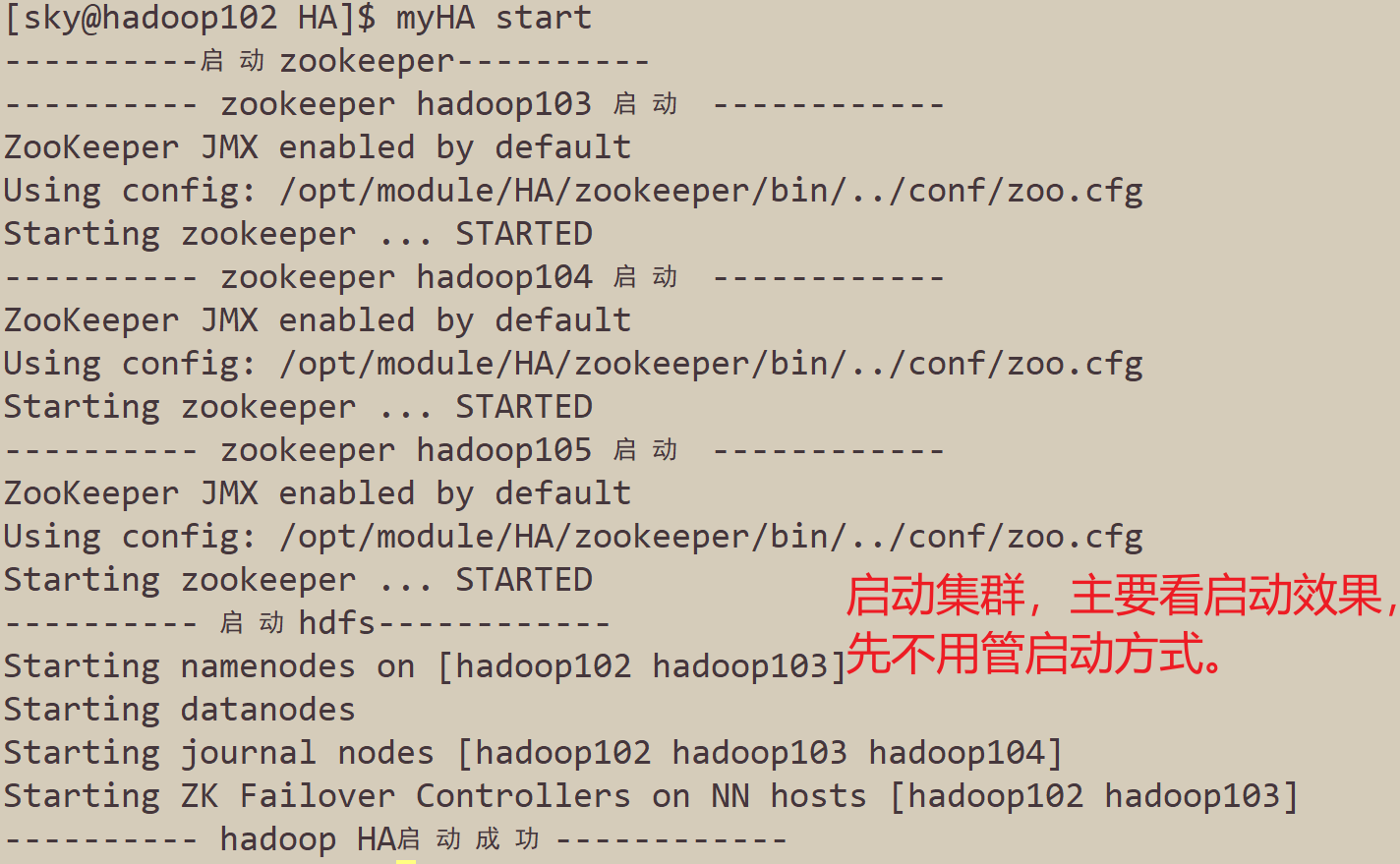
- 查看集群规划是否符合预期

2.2 集群解释
- NN-1
NameNode节点1,在 core-site.xml 文件中配置。
<!-- mycluster是集群名称,值是集群中的所有namenodes -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
- NN-2
NameNode节点2,也是在 core-site.xml 文件中配置。
- DN
DataNode,在workers中配置。 workers中的主机名要提前在/etc/hosts文件中做好主机名与IP的映射。

- ZK
Zookeeper,在 zoo.cfg 文件中配置。 注意要将 zoo_sample.cfg 文件改名为 zoo.cfg,这个文件在 zookeeper 目录的 conf 目录下。不需要启动Zookeeper的节点,不需要配置进来。
- ZKFC
ZKFailOverController,不需要主动配置,哪里的NameNode正常启动了ZKFC就会启动。 ZKFailOverController是Hadoop中通过ZK实现FC(故障转移)功能的一个实用工具。
- JNN
JournalNode,在需要启动的节点上启动,仅第一次启动Hadoop时需要手动启动,后面都不需要手动启动。
三、说明🔑
3.1 主机名说明
据了解,很多朋友使用的四个节点的名称 并不是 hadoop102,hadoop103,hadoop104,hadoop105 ,有是master、slave1,slave2,slave3的;有namenode,datanode1,datanode2,datanode3的。没关系,只是主机名不一样而已! 只需要将对应的地方修改一下,就可以。(如果你足够熟练,就知道哪些地方要用自己的主机名)
3.2 用户名说明
在搭建过程中,我也没有使用 root 账号,使用的是一个可以执行 sudo 命令的普通用户账号。
为什么不使用root账号?
试问一下大家,如果你在公司上班,如果你不是运维人员,只是普通的开发人员,你可以拿到root账号的权限吗?显然是不可以的,我认为我们在平时的训练中就要养成使用普通用户账号的习惯,实际操作中才能游刃有余。(类似于接受自己的平庸哈哈哈)
3.3 操作目录说明
所有操作均在 /opt/module/HA 目录下,当然如果需要修改环境变量就要切换到 /etc/profile.d/ 目录下。
3.3 必要工具说明
这里使用到的就是VMware(安装虚拟机),XShell(远程连接工具)、Xftp(文件传输工具)。
至此,我们的需求、要求以及硬件设备就准备好了。下面开始准备软件吧!
四、上传资料🌵
磨刀不误砍柴工!充分的准备可以让我们的搭建过程事半功倍,流畅无比! ,而且,这也是减少返工(软件工程中的名词)的重要条件,大家一定要做好哦!
4.1 资料准备
这里用到的安装包有:jdk-8u202-linux-x64.tar.gz,点我下载jdk,hadoop-3.1.3.tar.gz,点我下载hadoop,apache-zookeeper-3.5.7-bin.tar.gz。点我下载Zookeeper,如果没有这些文件的可以私信我获取,我都上传到百度网盘了。
4.2 脚本准备
这里,我主要使用到了分发脚本(脚本名xsync),Hadoop HA一键启动脚本(脚本名myHA),查看所有节点jps进程脚本(脚本名jpsall)。
脚本的使用之前有提到过,这里不再赘述,大家可以参考我的这篇文章或其他文章:hadoop集群启停脚本分享。
下面是脚本内容,需要注意的是如果你的主机名和我不同,记得修改文中代码!
- xsync
#! /bin/bash
# 1.判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Argument!
exit;
fi
# 2.遍历所有集群机器
for host in hadoop102 hadoop103 hadoop104 hadoop105
do
echo ==================== $host ===================
# 3.遍历所有目录,挨个发送
for file in $@
do
# 4.判断文件是否存在
if [ -e $file ]
then
# 5.获取父目录
pdir=$(cd -P $(dirname $file); pwd)
# 6.获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
- myHA
#! /bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit;
fi
case $1 in
"start"){
echo "----------启动zookeeper----------"
for i in hadoop103 hadoop104 hadoop105
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/HA/zookeeper/bin/zkServer.sh start"
done
echo "---------- 启动hdfs------------"
ssh hadoop102 "/opt/module/HA/hadoop-3.1.3/sbin/start-dfs.sh"
echo "---------- hadoop HA启动成功------------"
};;
"stop"){
echo "----------关闭hdfs----------"
ssh hadoop102 "/opt/module/HA/hadoop-3.1.3/sbin/stop-dfs.sh"
echo "----------关闭zookeeper----------"
for i in hadoop103 hadoop104 hadoop105
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/HA/zookeeper/bin/zkServer.sh stop"
done
echo "---------- hadoop HA停止成功------------"
};;
"status"){
for i in hadoop103 hadoop104 hadoop105
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/HA/zookeeper/bin/zkServer.sh status"
done
};;
\*)
echo "Input Args Error"
;;
esac
- jpsall
#! /bin/bash
for host in hadoop102 hadoop103 hadoop104 hadoop105
do
echo ----------$host----------
ssh $host jps
done
4.3 配置文件准备
由于篇幅原因,这里不展示配置文件的具体内容,但是却是非常重要,重中之重,大家可以私信我获取!这是搭建HA高可用中的关键,是减少我们遇到 报错风暴 的必由之路。
这里要用到的配置文件有:core-site.xml,hdfs-site.xml,hadoop-env.sh,workers,yarn-site.xml,mapred-site.xml(都在hadoop/etc/hadoop目录下)zoo.cfg(zookeeper/conf/目录下),my_env.sh(/etc/profile.d/目录下),共8个文件。
这8个配置文件均已上传百度网盘!点我获取资料。
至此,我们的资料也准备好了!
五、解压与修改文件🍉
5.1 解压软件包
将上述我们准备好的Zookeeper、Hadoop、JDK软件包通过Xshell+Xftp上传到 /opt/software 目录下,并解压到 /opt/module/HA 目录下。

上传文件过程请大家自己完成哦!下面是解压过程:(该过程只需要在一台节点上完成即可,我这里使用的hadoop102,其他的节点后面使用克隆)。
- 创建HA目录
mkdir /opt/module/HA
- 解压JDK
tar -xzvf /opt/software/jdk-8u202-linux-x64.tar.gz -C /opt/module/HA/
- 解压Hadoop
tar -xzvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/HA/
- 解压Zookeeper
tar -xzvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/HA/
- 重命名Zookeeper
mv apache-zookeeper-3.5.7-bin/ zookeeper
- 重命名JDK
mv jdk1.8.0_202/ jdk1.8
5.2 修改配置文件
hadoop目录下的文件共六个,在资料中已经给出,下面仅展示一部分要特别注意的配置文件。
- 1.core-site.xml
- 2.hdfs-site.xml
- 3.hadoop-env.sh
- 4.workers
hadoop103
hadoop104
hadoop105
- 5.yarn-site.xml
- 6.mapre-site.xml
zookeeper目录下的文件
- 1.zoo.cfg
server.1=hadoop103:2888:3888
server.2=hadoop104:2888:3888
server.3=hadoop105:2888:3888
- 2.myid
这个节点上没有使用Zookeeper,所以未使用myid文件。
/etc/profile.d目录下的文件
- my_env.sh
# JAVA\_HOME
# 只需修改java\_home 因人而异 是自己的jdk安装目录
export JAVA\_HOME=/opt/module/jdk1.8
export PATH=$PATH:$JAVA\_HOME/bin
# HADOOP\_HOME
# 同理 这里只需修改Hadoop\_home,是Hadoop安装目录
export HADOOP\_HOME=/opt/module/HA/hadoop-3.1.3
export PATH=$PATH:$HADOOP\_HOME/bin
export PATH=$PATH:$HADOOP\_HOME/sbin
export HDFS\_NAMENODE\_USER=sky
export HDFS\_DATANODE\_USER=sky
export HDFS\_SECONDARYNAMENODE\_USER=sky
export YARN\_RESOURCEMANAGER\_USER=sky
export YARN\_NODEMANAGER\_USER=sky
# ZOOKEEPER\_HOME
export ZOOKEEPER\_HOME=/opt/module/HA/zookeeper
export PATH=$PATH:$ZOOKEEPER\_HOME/bin
之后记得刷新环境变量:
source /etc/profile.d/my_env.sh
5.3 创建目录
创建Hadoop数据临时目录:
mkdir /opt/module/HA/tmp
创建JournalNode日志目录:
mkdir /opt/module/HA/logs
创建Zookeeper数据目录:
mkdir /opt/module/HA/zookeeper/zkData
5.4 分发HA目录
分发HA目录下的所有内容到hadoop103,hadoop104,hadoop105上。
xsync /opt/module/HA/
六、启动HA集群🎈
6.1 Zookeeper启动测试
分别在hadoop103,hadoop104,hadoop105三个节点上启动Zookeeper,因为这三个节点在集群规划中有ZK。
zkServer.sh start



网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
](https://img-blog.csdnimg.cn/130ac4ccb8874241a37a789bd677a915.png)
[外链图片转存中…(img-ly1OpPna-1714721163062)]
[外链图片转存中…(img-biVK3Hyf-1714721163062)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









