







查看欠采样后的数据形状
x.shape,y.shape
((61878, 93), (61878,))
x_resampled.shape,y_resampled.shape
((17361, 93), (17361,))
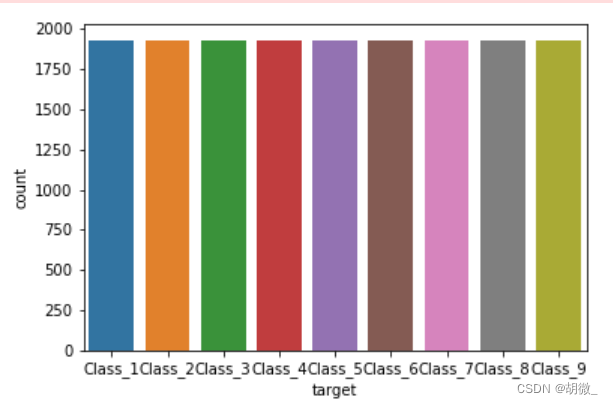
查看数据经过欠采样之后类别是否平衡
sns.countplot(y_resampled)
plt.show()
(3)把标签值转换为数字
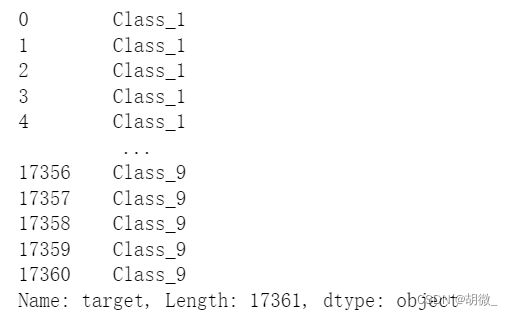
y_resampled
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_resampled = le.fit_transform(y_resampled)
y_resampled
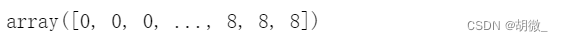
(4)分割数据
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x_resampled,y_resampled,test_size=0.2)
### 4.3 模型训练
from sklearn.ensemble import RandomForestClassifier
estimator = RandomForestClassifier(oob_score=True)
estimator.fit(x_train,y_train)
### 4.4 模型评估
本题要求使用logloss进行模型评估
y_pre = estimator.predict(x_test)
y_test,y_pre
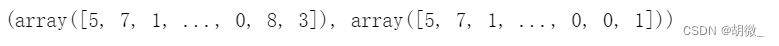
>
> 需要注意的是:logloss在使用过程中,必须要求将输出用one-hot表示
>
>
>
from sklearn.preprocessing import OneHotEncoder
one_hot = OneHotEncoder(sparse=False)
y_pre = one_hot.fit_transform(y_pre.reshape(-1,1))
y_test = one_hot.fit_transform(y_test.reshape(-1,1))
y_test,y_pre
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









