







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
cat id_rsa.pub >> authorized_keys #再次使用cat追加方式
* 此时hadoop9的authorized\_keys文件中拥有了hadoop7/8/9的密钥,再使用scp命令将hadoop9的authorized\_keys文件发送到hadoop7和hadoop8覆盖掉原文件。
scp authorized_keys root@hadoop7:/root/.ssh/
scp authorized_keys root@hadoop8:/root/.ssh/
可以使用命令vim authorized\_keys查看该文件里面是否有三台主机的密钥。

C、验证免密是否成功
使用ssh 用户名@节点名或ssh ip地址 命令验证免密码登录。
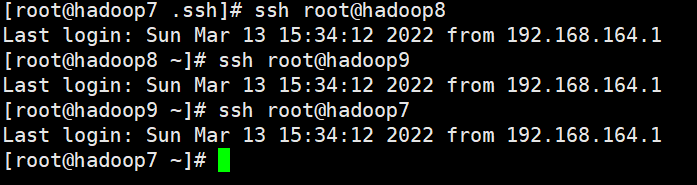
#### 6、启动HDFS、YARN
进入目录/usr/local/hadoop-2.7.3/sbin
./start-dfs.sh
./start-yarn.sh
jps #查看进程
主机hadoop7

从机hadoop8
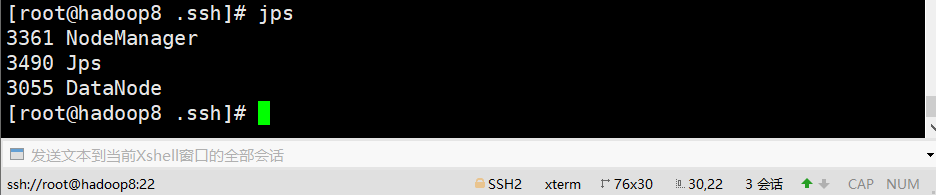
从机hadoop9
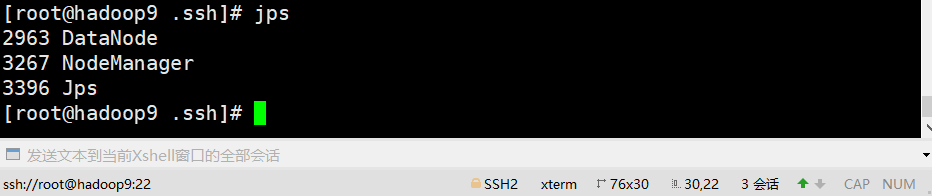
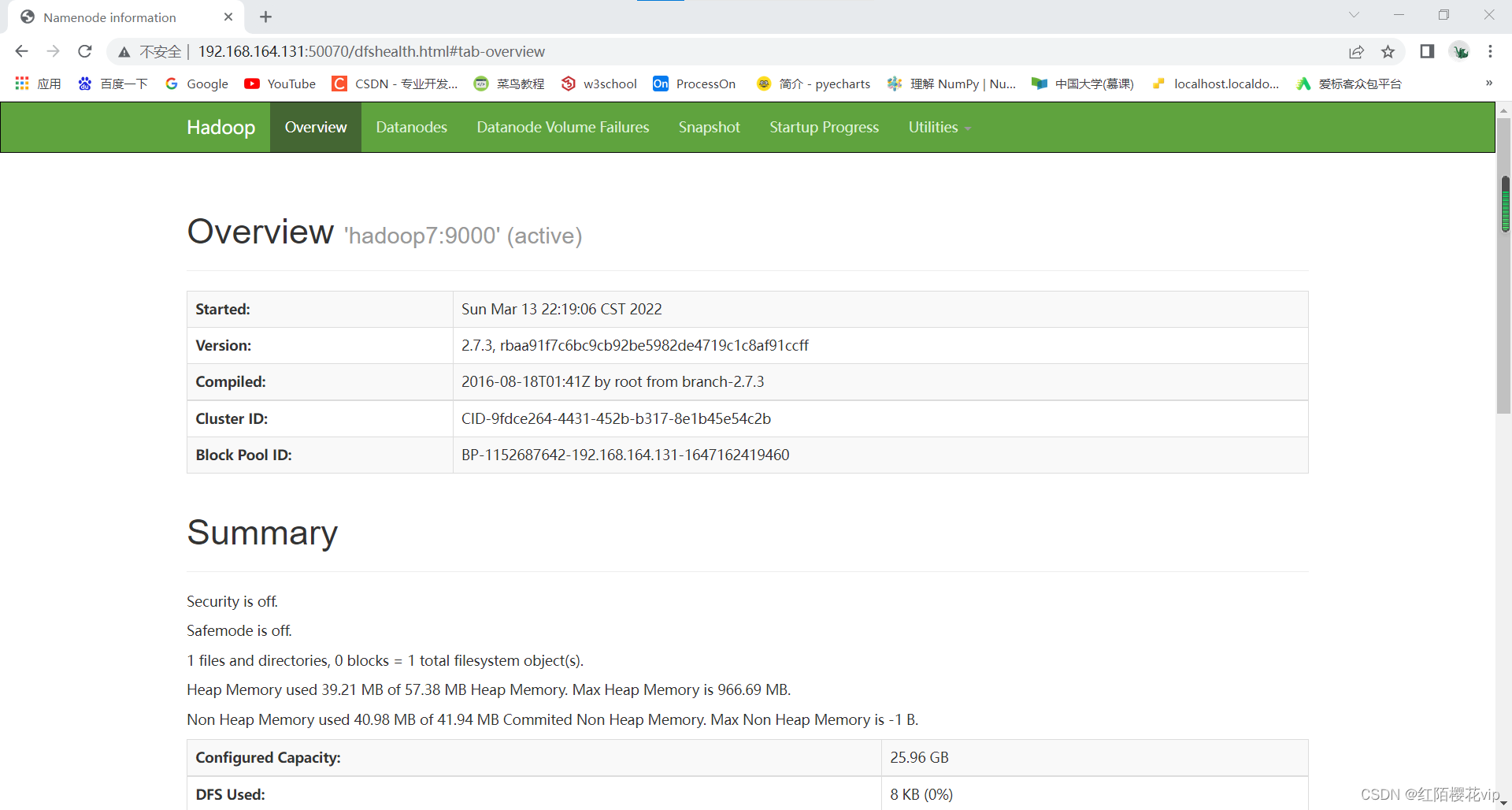
#### 7、查看页面
在浏览器中查看hdfs和yarn的web界面
ip地址:50070

ip地址:8088


### 二、Spark安装配置
#### 1、上传解压
将spark压缩包上传到Linux的/usr/local目录下并解压。
rz #上传
tar -zxvf spark-2.4.7-bin-hadoop2.7.tgz #解压
rm -rf spark-2.4.7-bin-hadoop2.7.tgz #解压完可以删除压缩包
#### 2、文件配置
切换到spark安装包的/conf目录下,进行配置。

使用cp命令将配置文件复制一份,原文件备份
cp slaves.template slaves
cp spark-defaults.conf.template spark-defaults.conf
cp spark-env.sh.template spark-env.sh

**配置slaves文件:**
****
scp slaves root@hadoop8:/usr/local/spark-2.4.7-bin-hadoop2.7/conf
scp slaves root@hadoop9:/usr/local/spark-2.4.7-bin-hadoop2.7/conf
将配好的slaves文件发送到hadoop8和hadoop9
**配置spark-defaults.conf文件:**
hadoop7:
spark.hadoop7 spark://hadoop7:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop7:9000/spark-logs
spark.history.fs.logDirectory hdfs://hadoop7:9000/spark-logs
hadoop8和hadoop9:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop7:9000/spark-logs
spark.history.fs.logDirectory hdfs://hadoop7:9000/spark-logs
**配置spark-env.sh文件:**
结尾添加
export JAVA_HOME=/usr/local/jdk1.8.0_144
export HADOOP_HOME=/usr/local/hadoop-2.7.3
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.3/etc/hadoop
export SPARK_MASTER_IP=hadoop7
#### 3、启动hadoop集群
cd /usr/local/hadoop-2.7.3/sbin
./start-all.sh
创建spark-logs目录
hdfs dfs -mkdir /spark-logs


cd /usr/local/spark-2.4.7-bin-hadoop2.7/sbin # 进入spark的/sbin目录下
./start-all.sh # 启动集群命令
启动后主节点jps进程:

从节点jps进程:

#### 4、在web界面访问主节点
IP地址:8080

#### 5、测试spark-shell和spark-sql
cd /usr/local/spark-2.4.7-bin-hadoop2.7/bin # 进入spark的/bin目录下
启动命令
./spark-shell # 退出spark-shell命令“:quit”
./spark-sql # 退出spark-sql命令“quit;”


### 三、 Flink安装配置
#### 1、安装 Flink
进入[下载页面]( )。选择一个与你的Hadoop版本相匹配的Flink包。
下载后上传到主节点上,并解压:
tar -zxvf apache-flink-1.10.2.tar.gz
rm -rf apache-flink-1.10.2.tar.gz
mv apache-flink-1.10.2 flink
#### 2、配置 Flink
cd /usr/local/flink/deps/conf
设置`jobmanager.rpc.address`配置项为你的master节点地址。另外为了明确 JVM 在每个节点上所能分配的最大内存,我们需要配置`jobmanager.heap.mb`和`taskmanager.heap.mb`,值的单位是 MB。如果对于某些worker节点,你想要分配更多的内存给Flink系统,你可以在相应节点上设置`FLINK_TM_HEAP`环境变量来覆盖默认的配置。
A、配置zoo.cfg
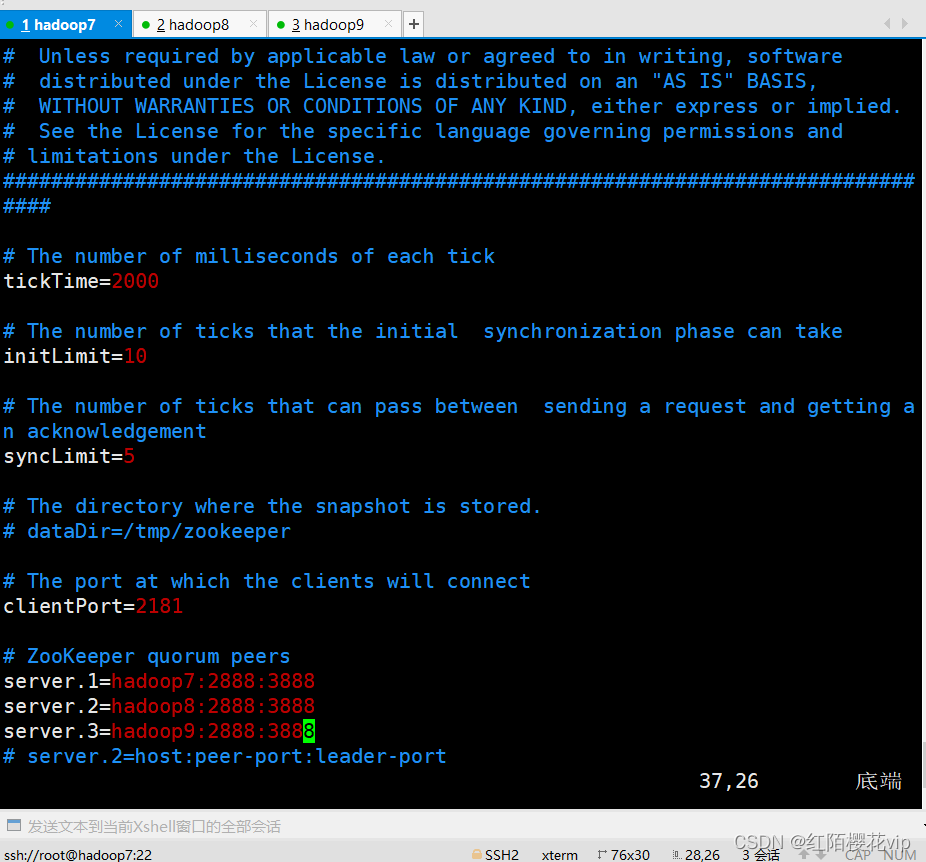
B、配置slaves
最后,你需要提供一个集群中worker节点的列表。因此,就像配置HDFS,编辑*conf/slaves*文件,然后输入每个worker节点的 IP/Hostname。每一个worker结点之后都会运行一个 TaskManager。
每一条记录占一行,就像下面展示的一样:
C、配置flink-conf.yaml
D、配置masters
每一个worker节点上的 Flink 路径必须一致。你可以使用共享的 NSF 目录,或者拷贝整个 Flink 目录到各个worker节点。
cd /usr/local
scp -r flink root@hadoop8:/usr/local
scp -r flink root@hadoop9:/usr/local
注意:
* TaskManager 总共能使用的内存大小(`taskmanager.heap.mb`)
* 每一台机器上能使用的 CPU 个数(`taskmanager.numberOfTaskSlots`)
* 集群中的总 CPU 个数(`parallelism.default`)
* 临时目录(`taskmanager.tmp.dirs`)
#### 3、启动 Flink
下面的脚本会在本地节点启动一个 JobManager,然后通过 SSH 连接所有的worker节点(*slaves*文件中所列的节点),并在每个节点上运行 TaskManager。现在你的 Flink 系统已经启动并运行了。跑在本地节点上的 JobManager 现在会在配置的 RPC 端口上监听并接收任务。
在主节点flink的bin目录下:
./start-cluster.sh
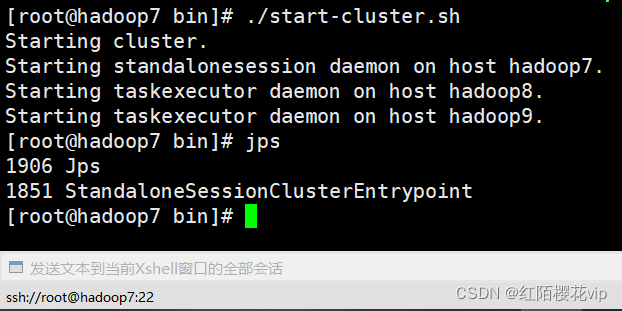
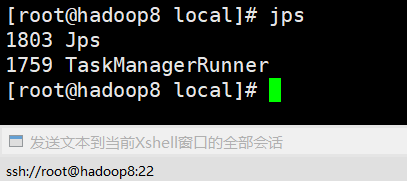
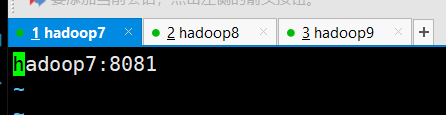
如上图flink集群进程启动成功,也可以通过web界面验证,flink端口号8081


#### 4、添加实例到集群中
* #### 添加一个 JobManager
./jobmanager.sh (start cluster)|stop|stop-all
* #### 添加一个 TaskManager
./taskmanager.sh start|stop|stop-all
### 四、Kafka安装配置
#### 1、安装zookeeper
A、上传解压
将zookeeper压缩包上传到/usr/local目录下并解压
rz # 上传
tar -zxvf zookeeper-3.4.12.tar.gz # 解压
B、修改配置文件
进入zookeeper的配置文件目录,并查看该目录下的文件:
cd /usr/local/zookeeper-3.4.12/conf
ll

该目录下有示例配置文件zoo\_sample.cfg,将其拷贝为zoo.cfg:
cp zoo_sample.cfg zoo.cfg
使用vim编辑配置文件zoo.cfg:
vim zoo.cfg
更改配置文件内容为下图:

在/usr/local/zookeeper-3.4.12目录下创建tmp文件
cd /usr/local/zookeeper-3.4.12
mkdir tmp
在/usr/local/zookeeper-3.4.12/tmp目录下创建myid文件
cd /usr/local/zookeeper-3.4.12/tmp
vim myid
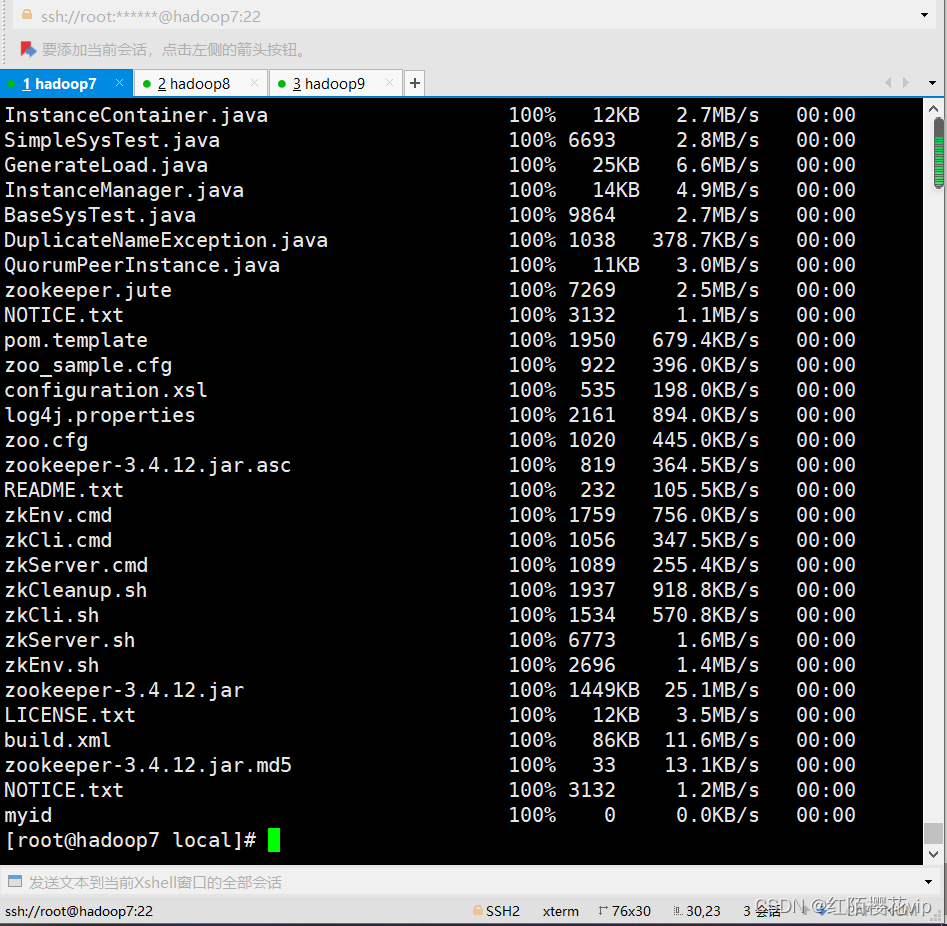
保存退出,使用scp将/usr/local下的zookeeper-3.4.12远程拷贝到hadoop8和hadoop9主机的/usr/local目录下:
scp -r zookeeper-3.4.12 root@hadoop8:/usr/local
scp -r zookeeper-3.4.12 root@hadoop9:/usr/local
如下图所示,拷贝完成:
将myid文件的内容更改为各自主机对应的server号。
在hadoop7的myid中添加以下内容:
1
在hadoop8的myid中添加以下内容:
2
在hadoop9的myid中添加以下内容:
3
C、配置环境变量
vim /etc/profile (配置如下图,在原有的基础上添加zookeeper环境变量,hadoop7/8/9都要配)
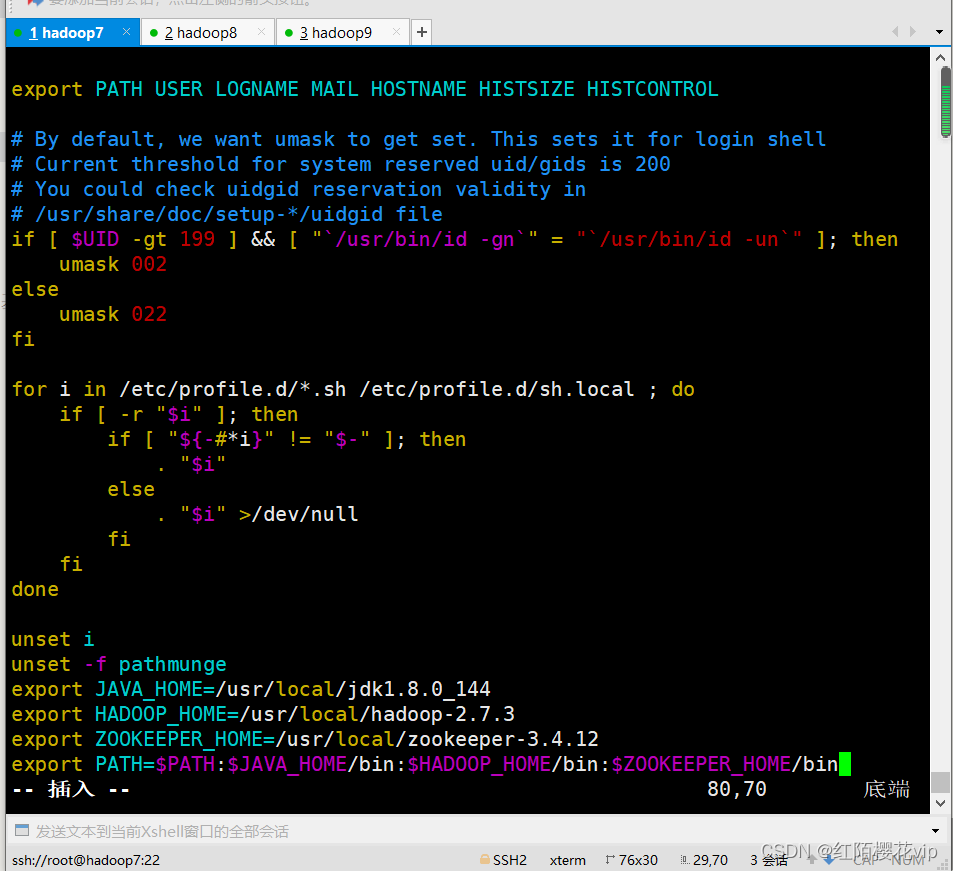
source /etc/profile # 使配置立即生效,不用重启
D、启动
分别进入**三台主机**的/usr/local/zookeeper-3.4.12/bin目录下,执行启动脚本:
cd /usr/local/zookeeper-3.4.12/bin
./zkServer.sh start

E、查看状态
zkServer.sh status
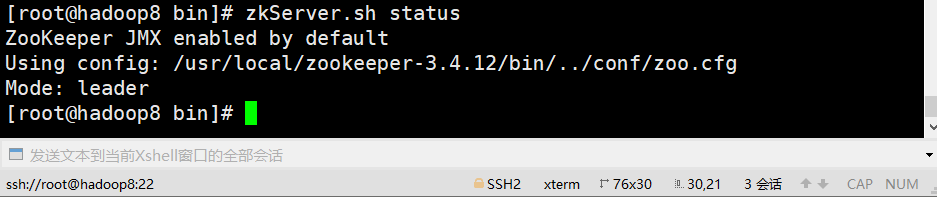
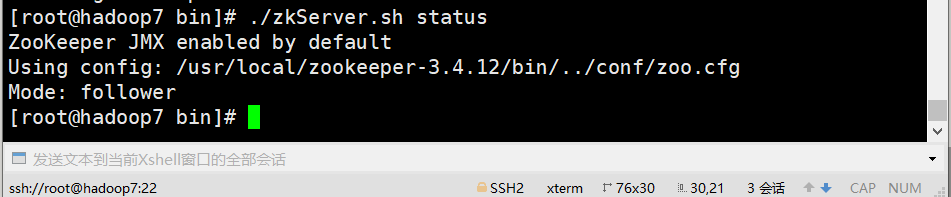
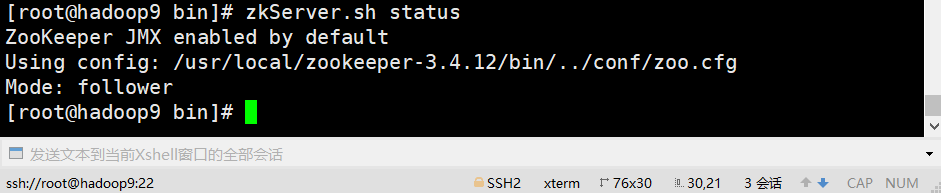
#### 2、安装kafka
A、上传解压
将下载好的kafka压缩包上传到/usr/local目录下
rz # 上传
tar -zxvf kafka_2.11-2.0.0.tgz # 解压
rm -rf kafka_2.11-2.0.0.tgz # 删除压缩包
mv kafka_2.11-2.0.0 kafka #改名
scp -r kafka root@hadoop8:/usr/local # 将解压改名好的kafka发送到hadoop8和hadoop9,也可使用rz命令在hadoop8和hadoop9重复上面几步操作
B、启动zookeeper集群
分别进入**三台主机**的/usr/local/zookeeper-3.4.12/bin目录下,执行启动脚本:
cd /usr/local/zookeeper-3.4.12/bin
./zkServer.sh start
C、修改配置文件
进入/usr/local/kafka/config目录下修改server.properties配置文件
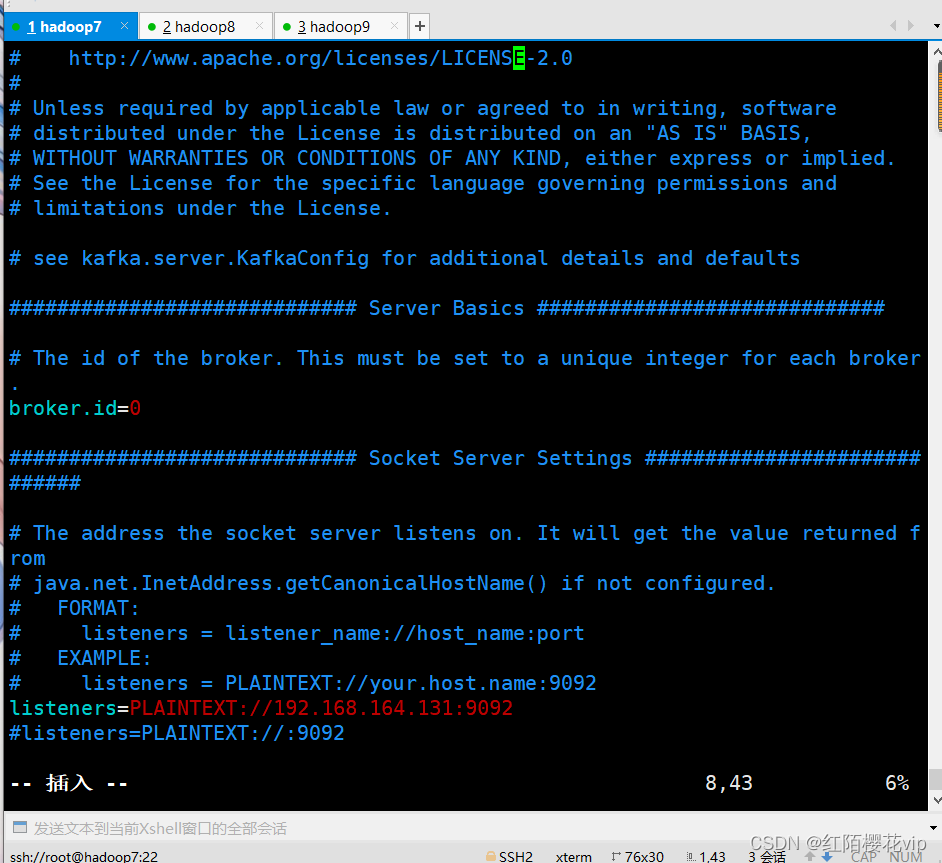


server.properties配置文件的修改主要在开头和结尾,中间保持默认配置即可;需要注意的点是broker.id的值三个节点要配置不同的值,分别配置为0,1,2;log.dirs必须保证目录存在,自己去创建一个,不会根据配置文件自动生成;
scp server.properties root@hadoop8:/usr/local/kafka/config #使用scp命令将配置好的文件发送到其他节点,然后修改其他节点的broker.id
**还需要注意的是**:因为hadoop8和hadoop9的kafka是通过scp发送的,所以除了要自己去修改主机和从机的broker.id还要自己去修改下图配置,改成从机对应的IP地址。


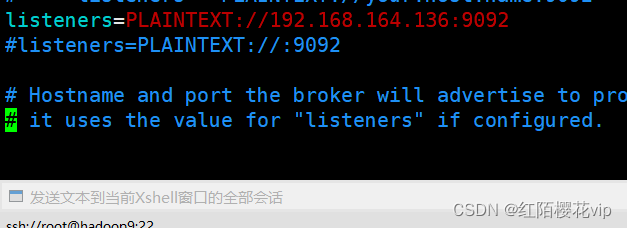
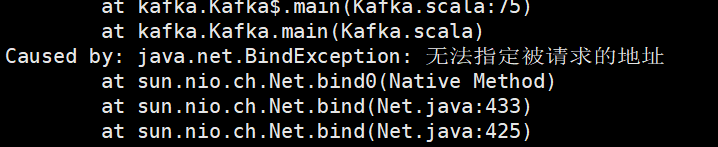
不然主机启动没问题,从机会遇到下图的问题:
(我一开始就没注意,然后从机报错启动不了,去百度看了有一会才改正错误)
D、启动kafka
启动kafka集群,进入kafka的bin目录,执行如下命令 :
./kafka-server-start.sh /usr/local/kafka/config/server.properties
三个节点均要启动;启动无报错,即搭建成功,可以生产和消费消息,来检测是否搭建成功。

E、常见kafka命令
创建topic–test
./bin/kafka-topics.sh --create --zookeeper IP地址:2181, IP地址:2181, IP地址:2181 --replication-factor 3 --partitions 3 --topic test
列出已创建的topic列表
./bin/kafka-topics.sh --list --zookeeper hadoop7:2181
更多:https://blog.csdn.net/zxy987872674/article/details/72493128
### 五、Flume安装配置
#### 1、上传解压
rz
tar -zxvf apache-flume-1.8.0-bin.tar.gz
mv apache-flume-1.8.0-bin flume
#### 2、配置环境变量
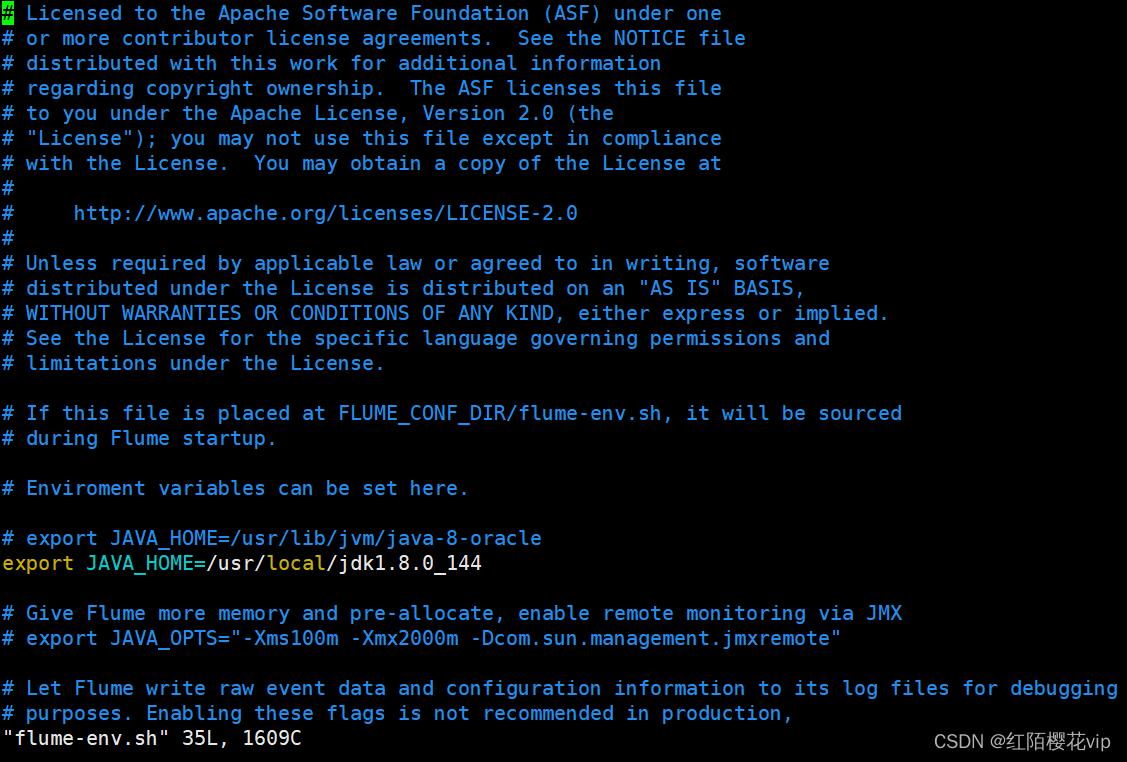
然后进入flume的目录,修改conf下的flume-env.sh,在里面配置JAVA\_HOME
#### 3、测试是否安装成功
使用命令**flume-ng version**
如下图则成功:

继续测试:
1、先在flume的conf目录下新建一个文件
>
> vim netcat-logger.conf
>
>
>
>
> # 定义这个agent中各组件的名字
> a1.sources = r1
> a1.sinks = k1
> a1.channels = c1
>
>
> # 描述和配置source组件:r1
> a1.sources.r1.type = netcat
> a1.sources.r1.bind = localhost
> a1.sources.r1.port = 44444
>
>
> # 描述和配置sink组件:k1
> a1.sinks.k1.type = logger
>
>
> # 描述和配置channel组件,此处使用是内存缓存的方式
> a1.channels.c1.type = memory
> a1.channels.c1.capacity = 1000
> a1.channels.c1.transactionCapacity = 100
>
>
> # 描述和配置source channel sink之间的连接关系
> a1.sources.r1.channels = c1
> a1.sinks.k1.channel = c1
>
>
>
2. 在Flume安装目录下启动agent去采集数据
>
> /usr/local/flume/bin/flume-ng agent -c conf -f /usr/local/flume/conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
>
>
>
-c conf 指定flume自身的配置文件所在目录
-f conf/netcat-logger.con 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字
3.测试
再开一shell窗口 输入以下命令
>
> telnet localhost 44444
>
>
>
> 注意: 如出现找不到这个命令 则是没有安装 telnet 服务
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
els.c1.transactionCapacity = 100
>
>
> # 描述和配置source channel sink之间的连接关系
> a1.sources.r1.channels = c1
> a1.sinks.k1.channel = c1
>
>
>
2. 在Flume安装目录下启动agent去采集数据
>
> /usr/local/flume/bin/flume-ng agent -c conf -f /usr/local/flume/conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
>
>
>
-c conf 指定flume自身的配置文件所在目录
-f conf/netcat-logger.con 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字
3.测试
再开一shell窗口 输入以下命令
>
> telnet localhost 44444
>
>
>
> 注意: 如出现找不到这个命令 则是没有安装 telnet 服务
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**
[外链图片转存中...(img-3LWpp6y4-1713390895671)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









