







 文章探讨了如何使用朴素贝叶斯公式在有限样本中计算产品经理超重且喜欢的概率,强调了特征独立假设的重要性,并介绍了拉普拉斯平滑在处理概率为零情况的方法。还讨论了朴素贝叶斯在文章分类中的应用,以及其优点和局限性。
文章探讨了如何使用朴素贝叶斯公式在有限样本中计算产品经理超重且喜欢的概率,强调了特征独立假设的重要性,并介绍了拉普拉斯平滑在处理概率为零情况的方法。还讨论了朴素贝叶斯在文章分类中的应用,以及其优点和局限性。
P(喜欢) = 4/7
P(程序员, 匀称) = 1/7(联合概率)
P(程序员|喜欢) = 2/4 = 1/2(条件概率)
P(程序员, 超重|喜欢) = 1/4
>
> 思考题:
>
>
> * 在小明是产品经理并且体重超重的情况下,如何计算小明被女神喜欢的概率?
> 即`P(喜欢|产品, 超重) = ?`
>
>
>
此时我们需要用到**朴素贝叶斯**进行求解。
那么思考题就可以套用贝叶斯公式这样来解决:
P(喜欢|产品, 超重) = P(产品, 超重|喜欢)P(喜欢)/P(产品, 超重)
计算上式可以发现:
* `P(产品, 超重|喜欢)` 和 `P(产品, 超重)` 的结果均为0,导致无法计算结果。这是因为我们的样本量太少了,不具有代表性。
* 本来现实生活中,肯定是存在职业是产品经理并且体重超重的人的,P(产品, 超重)不可能为0;
* 而且事件 `职业是产品经理` 和事件 `体重超重` 通常被认为是相互独立的事件,但是,根据我们有限的7个样本计算 `P(产品, 超重) = P(产品)P(超重)` 不成立。
而朴素贝叶斯可以帮助我们解决这个问题:
* 朴素贝叶斯,简单理解,就是假定了特征与特征之间相互独立的贝叶斯公式。
* 也就是说,朴素贝叶斯,之所以**朴素**,就在于假定了**特征与特征相互独立**。
所以,思考题如果按照朴素贝叶斯的思路来解决,就可以是
P(产品, 超重) = P(产品) * P(超重) = 2/7 * 3/7 = 6/49
p(产品, 超重|喜欢) = P(产品|喜欢) * P(超重|喜欢) = 1/2 * 1/4 = 1/8
P(喜欢|产品, 超重) = P(产品, 超重|喜欢)P(喜欢)/P(产品, 超重) = 1/8 * 4/7 / 6/49 = 7/12
## 3 拉普拉斯平滑系数
贝叶斯公式如果应用在**文章分类**的场景当中,我们可以这样看:
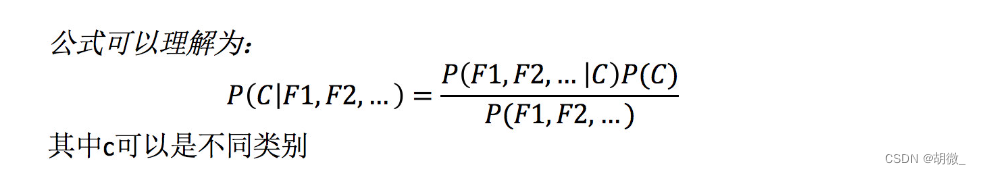

**下面通过一个案例进行理解**
需求:通过前四个训练样本(文章),判断第五篇文章,是否属于China类
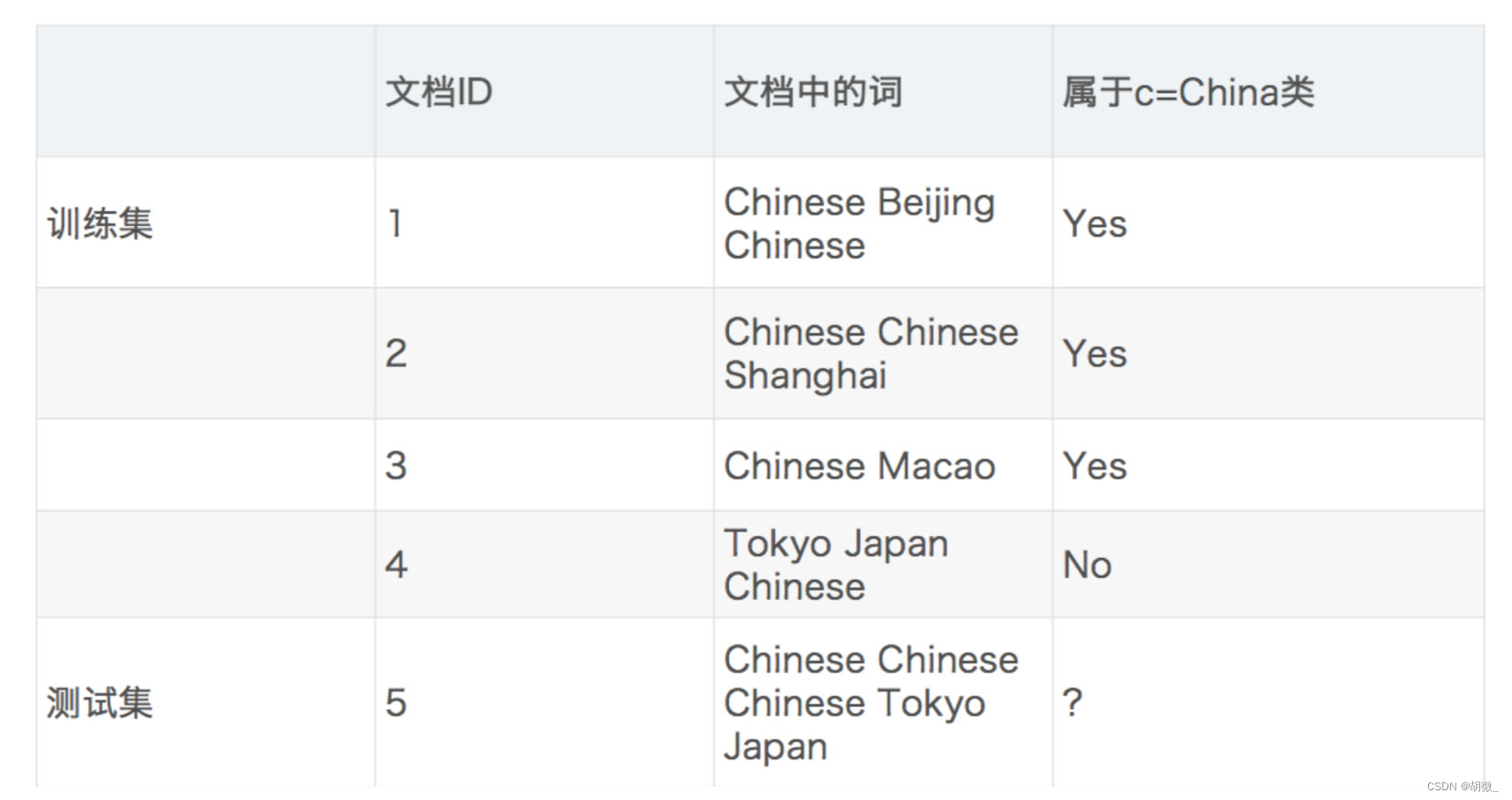
P(C|Chinese, Chinese, Chinese, Tokyo, Japan)
= P(Chinese, Chinese, Chinese, Tokyo, Japan|C) * P© / P(Chinese, Chinese, Chinese, Tokyo, Japan)
= P(Chinese|C)^3 * P(Tokyo|C) * P(Japan|C) * P© / [P(Chinese)^3 * P(Tokyo) * P(Japan)]
这个文章是需要计算是不是China类,是或者不是最后的分母值都相同:
首先计算是China类的概率:
P(Chinese|C) = 5/8
P(Tokyo|C) = 0/8
P(Japan|C) = 0/8
接着计算不是China类的概率:
P(Chinese|C) = 1/3
P(Tokyo|C) = 1/3
P(Japan|C) = 1/3
**问题**:从上面的例子我们可以得到 `P(Tokyo|C)` 和 `P(Japan|C)`都为0,这是不合理的,如果词频列表里面有很多次数都为0,很可能计算结果都为0。
**解决办法**:拉普拉斯平滑系数

这个文章是需要计算是不是China类:
该例中,m=6(训练集中特征词的个数,重复不计)
首先计算是China类的概率:
P(Chinese|C) = 5/8 --> 6/14
P(Tokyo|C) = 0/8 --> 1/14
P(Japan|C) = 0/8 --> 1/14
接着计算不是China类的概率:
P(Chinese|C) = 1/3 --> 2/9
P(Tokyo|C) = 1/3 --> 2/9
P(Japan|C) = 1/3 --> 2/9
## 4 朴素贝叶斯api使用
`sklearn.naive_bayes.MultinomialNB(alpha = 1.0)`
* 朴素贝叶斯分类
* `alpha`:拉普拉斯平滑系数
[朴素贝叶斯应用案例 —— 商品评论情感分析](https://bbs.csdn.net/topics/618545628)
## 5 朴素贝叶斯算法总结
### 5.1 朴素贝叶斯优缺点
(1)优点
* 朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率
* 对缺失数据不太敏感,算法也比较简单,常用于文本分类
* 分类准确度高,速度快
(2)缺点
* 由于使用了样本属性独立性的假设,所以如果特征属性有关联时其效果不好
* 需要计算先验概率,而先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳;
>
> * 先验概率:直观理解,所谓“先”,就是在事情之前,即在事情发生之前事情发生的概率。是根据以往经验和分析得到的概率,“由因求果”。
> * 后验概率:事情已经发生了,事情发生可能有很多原因,判断事情发生时由哪个原因引起的概率,“由果求因”。
> * 先验概率就是通常说的概率,后验概率是一种条件概率,但条件概率不一定是验后概率。贝叶斯公式是由先验概率求后验概率的公式
>
>
>
### 5.2 朴素贝叶斯疑难点
(1)朴素贝叶斯原理
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。
* 对于给定的待分类项x,通过学习到的模型计算后验概率分布,
* 即:在此项出现的条件下各个目标类别出现的概率,将后验概率最大的类作为x所属的类别。
(2)朴素贝叶斯朴素在哪里?
在计算条件概率分布 P(X=x∣Y=c\_k) 时,NB引入了一个很强的条件独立假设,即,当Y确定时,X的各个特征分量取值之间相互独立。
(3)为什么引入条件独立性假设?
为了避免贝叶斯定理求解时面临的组合爆炸、样本稀疏问题。
假设条件概率分为:

(4)在估计条件概率P(X∣Y)时出现概率为0的情况怎么办?


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









