







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

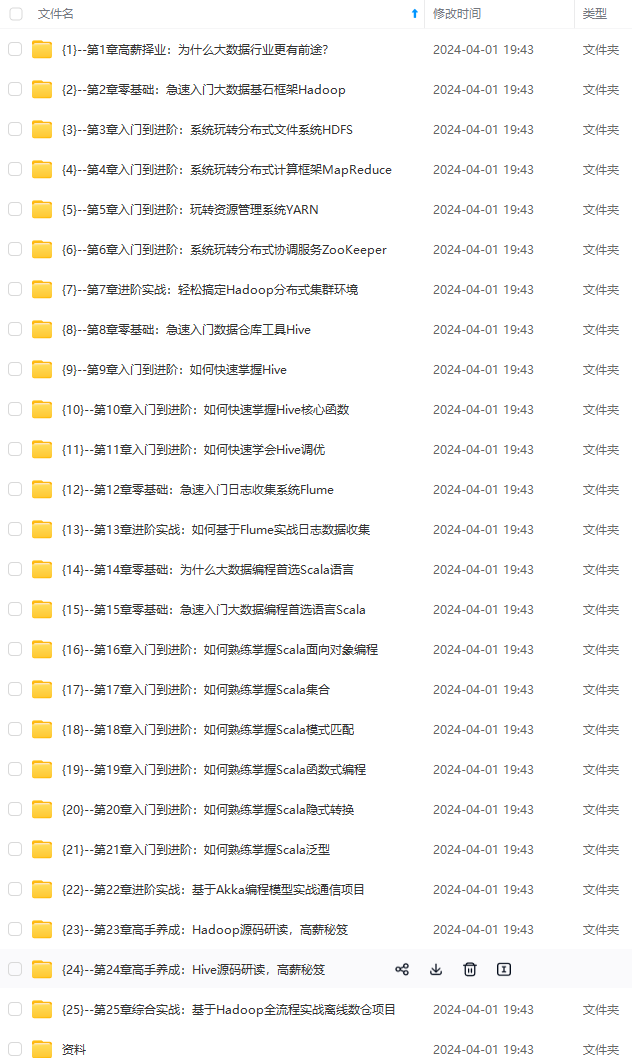
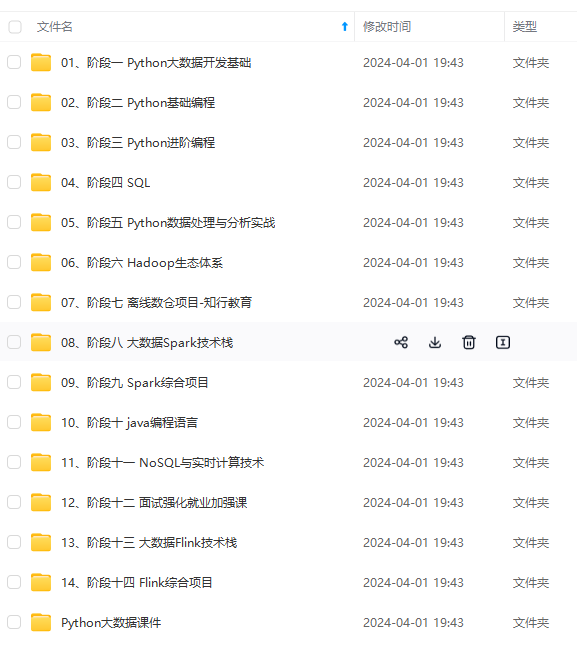
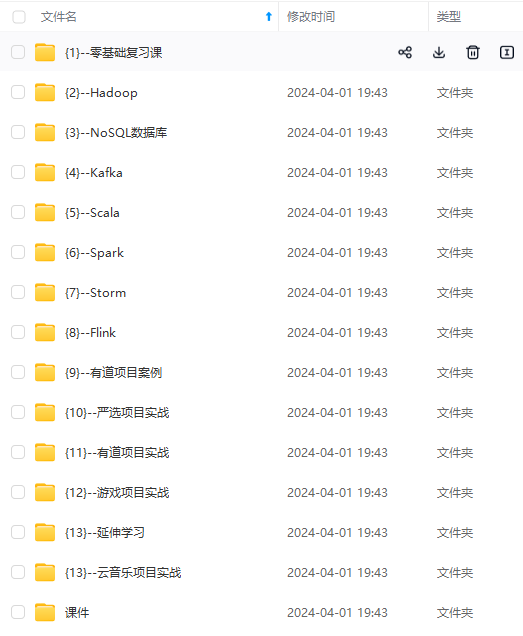
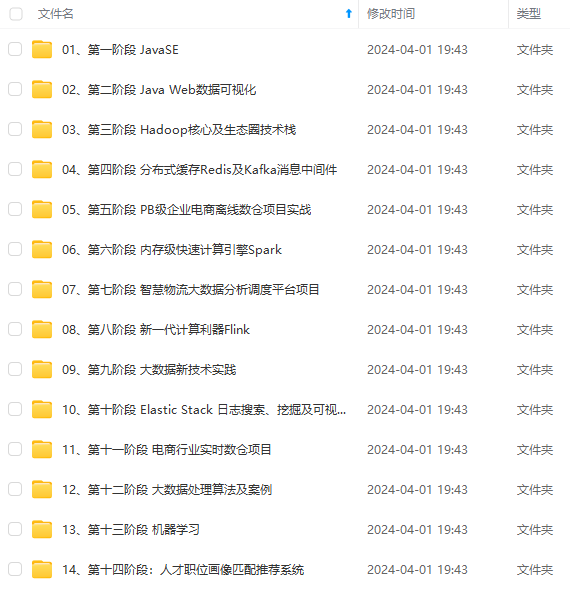
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
本栏目大数据开发岗高频面试题主要出自
大数据技术专栏的各个小专栏,由于个别笔记上传太早,排版杂乱,后面会进行原文美化、增加。
文章目录
停🤚
不要往下滑了,
默默想5min,
看看这5道面试题你都会吗?
面试题 01、spark.storage.memoryFraction参数的含义,实际生产中如何调优?
面试题02、Spark有哪两种算子?
面试题 03、Spark有哪些聚合类的算子,我们应该尽量避免什么类型的算子?
面试题04、如何从Kafka中获取数据?
面试题05、RDD创建有哪几种方式?


以下答案仅供参考:
面试题 01、spark.storage.memoryFraction参数的含义,实际生产中如何调优?
1)用于设置RDD持久化数据在Executor内存中能占的比例,默认是0.6,,默认Executor 60%的内存,可以用来保存持久化的RDD数据。根据你选择的不同的持久化策略,如果内存不够时,可能数据就不会持久化,或者数据会写入磁盘;
2)如果持久化操作比较多,可以提高spark.storage.memoryFraction参数,使得更多的持久化数据保存在内存中,提高数据的读取性能,如果shuffle的操作比较多,有很多的数据读写操作到JVM中,那么应该调小一点,节约出更多的内存给JVM,避免过多的JVM gc发生。在web ui中观察如果发现gc时间很长,可以设置spark.storage.memoryFraction更小一点。
面试题02、Spark有哪两种算子?
Transformation(转化)算子和Action(执行)算子。
面试题03、Spark有哪些聚合类的算子,我们应该尽量避免什么类型的算子?
在我们的开发过程中,能避免则尽可能避免使用reduceByKey、join、distinct、repartition等会进行shuffle的算子,尽量使用map类的非shuffle算子。
这样的话,没有shuffle操作或者仅有较少shuffle操作的Spark作业,可以大大减少性能开销。
面试题04、如何从Kafka中获取数据?
1)基于Receiver的方式 这种方式使用Receiver来获取数据。Receiver是使用Kafka的高层次Consumer API来实现的。receiver从Kafka中获取的数据都是存储在Spark Executor的内存 中的,然后Spark Streaming启动的job会去处理那些数据。
2)基于Direct的方式 这种新的不基于Receiver的直接方式,是在Spark 1.3中引入的,从而能够确保更加健壮的机制。替代掉使用Receiver来接收数据后,这种方式会周期性地 查询Kafka,来获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来 获取Kafka指定offset范围的数据。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









