







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新HarmonyOS鸿蒙全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

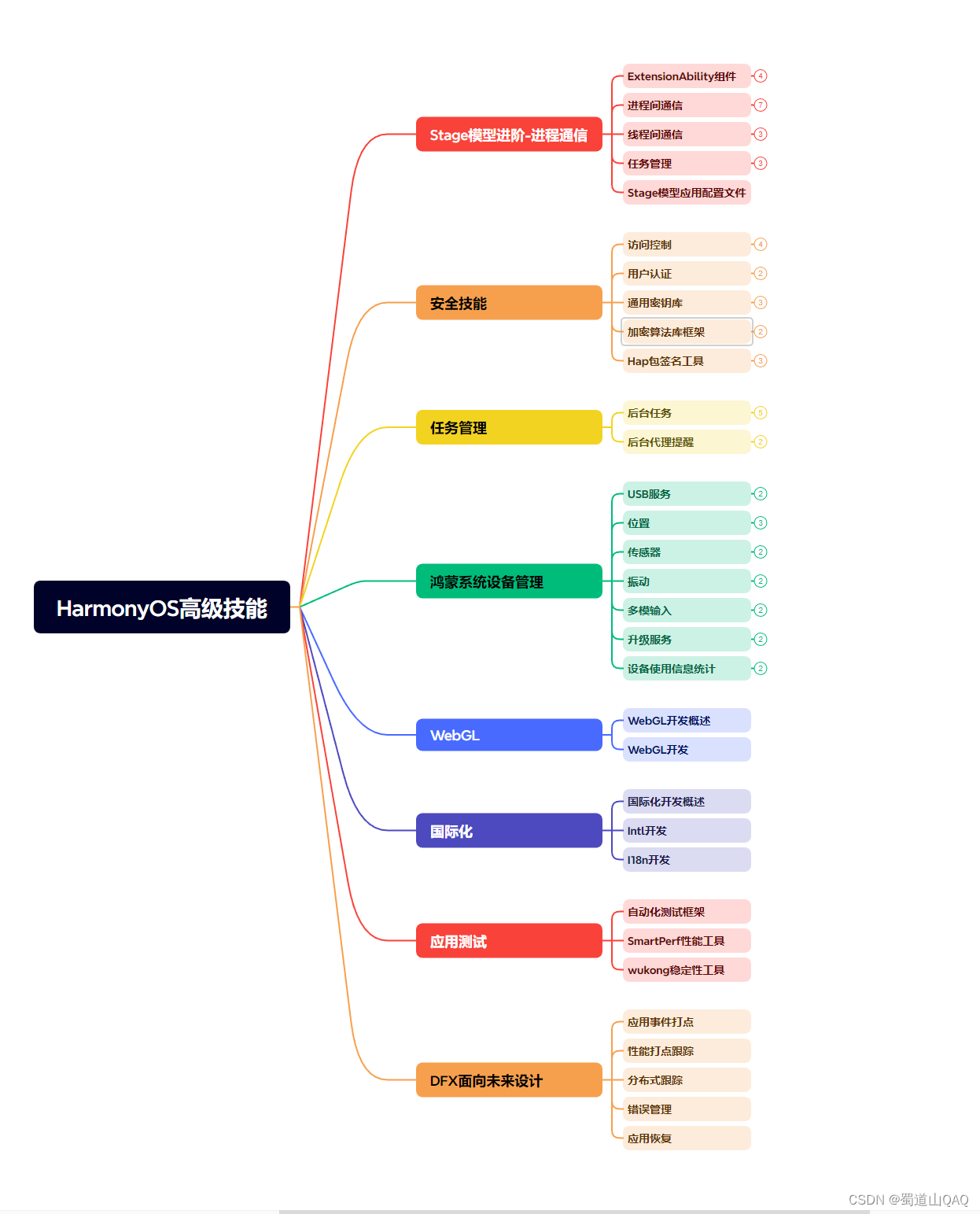
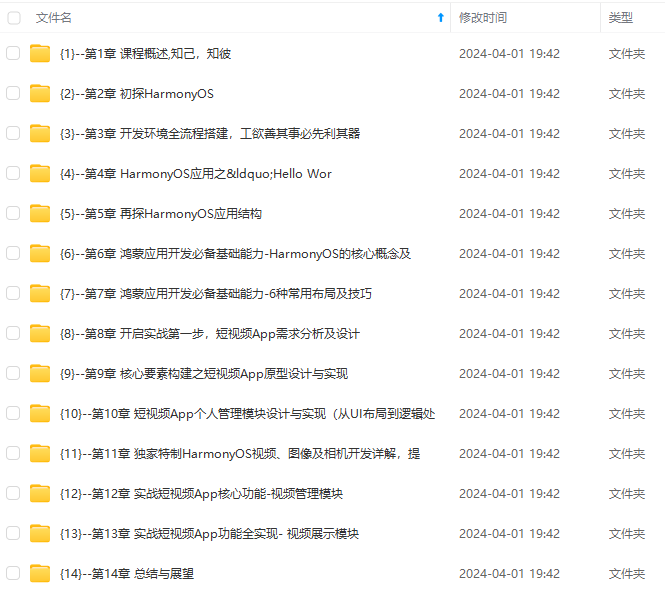


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注鸿蒙)

正文
这里可以看到一个sendMessageAtTime()方法,把消息传进去之外,还传了消息时间(系统启动时间+用户定义的时长),它其实就是核心方法,而同样handler的sendMessage()方法跟踪下去,它最后也是调用这个sendMessageAtTime()方法,所以来看该方法的详情:
public boolean sendMessageAtTime(Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
if (queue == null) {
RuntimeException e = new RuntimeException(
this + " sendMessageAtTime() called with no mQueue");
Log.w(“Looper”, e.getMessage(), e);
return false;
}
return enqueueMessage(queue, msg, uptimeMillis);
}
可以看到,在这里创建了MessageQueue对象,也就是我们常说的Handler机制里的四大元素之一队列,然后把发送的消息和队列以及时间参数传到了enqueueMessage()方法,也就是入队列操作:
private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {
msg.target = this;
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}
继续来看queue的enqueueMessage()方法:
boolean enqueueMessage(Message msg, long when) {
…
synchronized (this) {
if (mQuitting) {
IllegalStateException e = new IllegalStateException(
msg.target + " sending message to a Handler on a dead thread");
Log.w(TAG, e.getMessage(), e);
msg.recycle();
return false;
}
…
在分析这个方法前,先来想一想队列这个概念,可能有部分人对它有点陌生,这里解释一下,MessageQueue是一个队列,它并不是数组或者集合那样,是定义一个有容量的“容器”,而是通过单链表Message这个结构:
public final class MessageQueue {
private static final String TAG = “MessageQueue”;
private static final boolean DEBUG = false;
// True if the message queue can be quit.
private final boolean mQuitAllowed;
@SuppressWarnings(“unused”)
private long mPtr; // used by native code
Message mMessages;//单链表Message
…
作为MessageQueue持有的变量,Message里有一个指向下一个Message对象的引用,因此Message消息其实是一个单链表形式串联在一起的。它不同于线性表那样,比如一个数组是一块连续的内存空间,里面每一个对象按照顺序排在一起,因此查询的时候可以通过基址加偏移量(也就是直接a[index]的方式)来访问每一个元素对象,但它也有它的缺点,容易造成内存碎片,进而内存溢出:

每次构造都需要一大片连续内存空间才能构造出来,所以即使中间有些不是连续空出来的空间也只能浪费掉。
而单链表如果要访问第三个对象(比如此时有三个对象),则必须先要知道第二个对象的地址,而第二个对象又必须要靠第一个对象来获取,因此这就需要从头开始遍历才能最终访问到第三个对象。但单链表的好处就是,如果要在某个位置上插入或者删除某个节点对象,直接操作就可以(把它的指向下一个对象的引用的指向进行更改就可以)。

可以看到,创建链表不需要一大块连续内存空间,通过next引用的指向就能达到一个连一个,像一条链一样。了解单链表之后,回到enqueueMessage()方法来继续分析:
boolean enqueueMessage(Message msg, long when) {
…
msg.markInUse();
msg.when = when;
Message p = mMessages;
boolean needWake;
if (p == null || when == 0 || when < p.when) {
// New head, wake up the event queue if blocked.
msg.next = p;
mMessages = msg;
needWake = mBlocked;
} else {
…
}
…
这段代码其实很好理解,第一条消息进来时,P对象为空,mMessages对象也是为空,然后此时p==null成立,因此走if里面的代码块,然后让当前这条要发送的消息的下一个消息对象next引用指向p(也就是null),然后让mMessages等于当前消息对象。

那么当第二条消息进来时,又重新new了一个p对象,让它等于mMessage(也就是第一条消息对象),这次进来就需要判断第二条消息的时间是不是小于第一条消息的时间,也就是when < p.when是否成立,如果是小于的情况,那么就让当前消息对象msg(也就是第二条消息)的下一个指向next引用指向p(也就是第一条消息对象),而此时mMessages对象等于第二条消息对象,那现在这种情况也就是说如果我发送的第二条消息对象的时间是比第一条消息对象的时间还要小的话,那么就会让第二条消息排在第一条消息对象的前面,也就是先让第二条消息先发送:

第三条消息的时间也是比第二条消息要小,所以依然第三条消息的next引用指向第二条消息对象,那么当第四条消息对象的时间是比第三条消息对象的时间要大的话,则就走else块的代码,来看看会发生什么:
boolean enqueueMessage(Message msg, long when) {
…
msg.markInUse();
msg.when = when;
Message p = mMessages;
boolean needWake;
if (p == null || when == 0 || when < p.when) {
// New head, wake up the event queue if blocked.
msg.next = p;
mMessages = msg;
needWake = mBlocked;
} else {
// Inserted within the middle of the queue. Usually we don’t have to wake
// up the event queue unless there is a barrier at the head of the queue
// and the message is the earliest asynchronous message in the queue.
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
for (;😉 {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
msg.next = p; // invariant: p == prev.next
prev.next = msg;
}
…
可以看到,此时就是先创建一个prev对象,用来记录当前消息的上一个消息对象的,让它等于p(也就是第三条消息对象),然后p等于p(第三条消息对象)的下一个消息对象(此时是为第二条消息),所以现在p就为第二条消息对象,之后就判断当前对象(第四条消息对象)的时间when是否小于第二条消息对象的when,如果成立,则不用再循环,走msg.next = p;和prev.next = msg这两行代码,这两行代码的意思就是:当前消息对象msg(第四个消息对象)的下一个指向对象为p(此时为第二个消息),然后prev(此时为第三个消息对象)的下一个指向为msg当前消息对象,所以此时单链表的顺序是第三条消息对象指向第四条消息对象,第四条消息对象则指向第二条消息对象,因为第四条消息对象的时间是小于第二条的时间,大于第三条的时间:


那如果刚刚在for循环那里,此时第四条消息它的时间比第二条消息还要大,那循环就继续,prev等于第二条消息对象,而p等于 第二条消息对象的下一个对象即第一条消息对象,然后此时判断条件第四条消息对象时间比第一条消息对象时间要小,成立,则跳出循环,执行msg.next = p;和prev.next = msg这两行代码,所以此时第四条消息对象的下一个对象则指向第一条消息对象,而第二条消息对象则执行第四条消息对象,所以此时链的顺序是:第三条消息对象指向第二条消息对象,第二条消息对象则指向第四条消息对象,而第四条消息对象则指向第一条消息对象:


所以,handler的消息排序机制也就是靠这个时间when来决定谁先谁后,小的那个排在大的后面,借由单链表的插入特性来进行插入。因此,handler发送的消息其实是发送到MessageQueue里的链表Message里存储。
Handler请求在哪里被处理
那就要在ActivityThread里找到main()方法,也就是当应用启动时的方法,在里面可以看到:
public static void main(String[] args) {
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, “ActivityThreadMain”);
// CloseGuard defaults to true and can be quite spammy. We
// disable it here, but selectively enable it later (via
// StrictMode) on debug builds, but using DropBox, not logs.
CloseGuard.setEnabled(false);
…
Looper.prepareMainLooper();
…
if (false) {
Looper.myLooper().setMessageLogging(new
LogPrinter(Log.DEBUG, “ActivityThread”));
}
// End of event ActivityThreadMain.
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
Looper.loop();
throw new RuntimeException(“Main thread loop unexpectedly exited”);
}
Looper.prepareMainLooper()方法就是创建Looper对象,而Looper.loop()方法则开启轮询消息,不断去取消息,然后进行分发,所以看看它是怎么处理消息的:
public static void loop() {
final Looper me = myLooper();
…
for (;😉 {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
…
try {
msg.target.dispatchMessage(msg);
dispatchEnd = needEndTime ? SystemClock.uptimeMillis() : 0;
} finally {
if (traceTag != 0) {
Trace.traceEnd(traceTag);
}
}
…
}
}
可以看到是遍历MessageQueue队列,然后去取它里面的消息对象Message,调用queue的next()方法:
Message next() {
// Return here if the message loop has already quit and been disposed.
// This can happen if the application tries to restart a looper after quit
// which is not supported.
final long ptr = mPtr;
if (ptr == 0) {
return null;
}
int pendingIdleHandlerCount = -1; // -1 only during first iteration
int nextPollTimeoutMillis = 0;
for (;😉 {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
nativePollOnce(ptr, nextPollTimeoutMillis);
…
…
取之前,有个nativePollOnce()方法,是用来判断是否唤醒请求方法,使用了epoll机制,防止loop()方法一直轮询会卡死程序。然后接下来取消息的代码块里又加了synchronized同步锁,也就意味着多个消息不会出现并发的问题(即使多个handler同时发送消息):
…
for (;😉 {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
nativePollOnce(ptr, nextPollTimeoutMillis);
synchronized (this) {
// Try to retrieve the next message. Return if found.
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
if (msg != null && msg.target == null) {
// Stalled by a barrier. Find the next asynchronous message in the queue.
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
…
…
取出消息对象后,再次回到loop()方法中,最后调用这个方法来处理消息:
public static void loop() {
…
try {
msg.target.dispatchMessage(msg);
dispatchEnd = needEndTime ? SystemClock.uptimeMillis() : 0;
} finally {
if (traceTag != 0) {
Trace.traceEnd(traceTag);
}
}
…
}
调用了msg消息对象的target的dispatchMessage()方法去分发消息,这里的target其实就是handler对象:
public final class Message implements Parcelable {
public int what;
…
/package/ int flags;
/package/ long when;
/package/ Bundle data;
/package/ Handler target;
/package/ Runnable callback;
// sometimes we store linked lists of these things
/package/ Message next;
…
}
Handler、Looper、MessageQueue和Message四者关系
首先Handler可以在任意Activity里创建的,而Looper则是在ActivityThread的main()方法里创建的,接下里回到main()方法里往下看prepareMainLooper()方法:
public static void prepareMainLooper() {
prepare(false);
synchronized (Looper.class) {
if (sMainLooper != null) {
throw new IllegalStateException(“The main Looper has already been prepared.”);
}
sMainLooper = myLooper();
}
}
点进去看prepare()方法:
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException(“Only one Looper may be created per thread”);
}
sThreadLocal.set(new Looper(quitAllowed));
}
可以看到这里new了Looper对象,然后把它传到sThreadLocal的set()方法里,那么先来看看looper的构造方法:
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
好,那到现在为止,我们可以知道Looper是在ActivityThread的main()方法里调用Looper.prepareMainLooper()方法创建的,而Looper调用构造方法的同时,它也把MessageQueue给创建出来,创建的方法有直接new的方法,也有obtain()方法:
Message message = new Message();
Message message2 = Message.obtain();
官方建议使用obtain()方法来创建Message对象,因为obtain()方法采用了缓存池方式,定义了一个缓存池来构造了消息对象,然后要创建消息对象,就直接从池里取就行(没有缓存对象才去重新new一个新的消息对象),这样能避免了每次都要构造与销毁对象造成的性能消耗以及可能引发的内存抖动现象。
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
sPool = m.next;
m.next = null;
m.flags = 0; // clear in-use flag
sPoolSize–;
return m;
}
}
return new Message();
}
给它上锁,防止并发问题,然后定义m对象,让它等于sPool,也就是此时最后那个消息对象,然后sPool等于最后一个消息对象的下一个消息对象,那此时假设它为第一个消息对象,接着继续,此时m的下一个对象要指向null了,因为要把它取出来,然后容量要自减1,这段逻辑就是一个链表的常规取元素的逻辑,很容易理解。可以看到该池默认的容量是50:

不过这里有一点要补充的,就是这里的容量是50可能会有些歧义,让人觉得MessageQueue就真的只能缓存50个消息对象,但上面已经分析过Message结构是链表,理论上来说数量是没有限制的,而这里规定了50是处于性能的考虑以及方便我们去管理MessageQueue,如果实在是要突破这个容量去构造Message对象也是可以的,因为源码里也没有超出50之后抛异常的逻辑,所以当超出50之后,就重新new消息对象,直到本身内存不够报错。
为什么要用缓存池的方式来处理消息对象,因为除了我们用户之外,安卓底层其实很多地方都使用到了handler来发送和处理消息(比如ActivityThread和ApplicationThread通信),因此消息对象会频繁地被使用到,为了避免刚才说的频繁构造与销毁对象造成的性能消耗以及可能引发的内存抖动现象,就定义池来管理消息对象,一旦你要构造消息对象,就使用池里事先缓存好的消息对象,直到缓存池里的消息对象用完了,这时才去new新的消息对象。
ThreadLocal跟Handler的关联
在主线程中可以直接new我们的Handler对象,而在子线程中则要创建looper对象和开启looper轮询消息方法:
public class PingredActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
new Thread(new Runnable() {
@Override
public void run() {
Looper.prepare();
Handler handler = new Handler(){
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
}
};
handler.sendEmptyMessage(1);
Looper.loop();
}
}).start();
}
}
刚刚在看源码的时候可以看到主线程在activityThread中这两步已经帮我们写好了,因此直接创建Handler对象就可以。
还有一点要注意的是,每个线程的Looper都是不一样的,主线程中的Looper是属于主线程的,而子线程中Looper则属于子线程的,在创建Looper对象时,别忘了,它最后是作为参数传给了threadLocal对象里:
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException(“Only one Looper may be created per thread”);
}
sThreadLocal.set(new Looper(quitAllowed));
}
而ThreadLocal是一个用来存储每个线程自己独有的一些副本数据的对象,用线程自己的id作为key值可以从ThreadLocal对象里取它对应的线程里存的数据,比如Looper对象,所以为什么说一个线程里可以有多个handler对象,而looper对象以及messageQueue只能是一个,就是因为它们都被set()方法存进ThreadLocal里。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注鸿蒙)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
而ThreadLocal是一个用来存储每个线程自己独有的一些副本数据的对象,用线程自己的id作为key值可以从ThreadLocal对象里取它对应的线程里存的数据,比如Looper对象,所以为什么说一个线程里可以有多个handler对象,而looper对象以及messageQueue只能是一个,就是因为它们都被set()方法存进ThreadLocal里。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注鸿蒙)
[外链图片转存中…(img-Du1No7YH-1713638006404)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 670
670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









