







文章目录
🌲小逼叨
其实昨天发了一篇文章👉【感恩系列】:说点事儿 以及 我把所有的粉丝放到了中国地图上啦~
这篇文章是自己的第一篇“情感类”文章,里面讲述了自己的一些经历和感受,其实感觉写这类文章还是有点困难的,因为总有很多想表达的情绪,但又怕文章过于冗长无聊,而自己写这类文章没有太多经验(请大家见谅),本应该是纯纯情感,结果贴了代码上去,然后还没说清楚代码的编写思路和过程。
于是,今儿,我重新写了一篇,纯纯教学。教你们如何获取所有粉丝的IP所属地,并将他们放在中国地图上显示。
详细步骤,请各位兄弟姐妹们往下看👇
🌲爬取所有粉丝的IP所属地
🌴爬者基本素养:网页分析
网页分析网页分析,没有网页,何来分析,所以我们需要找到我们的目标网页,也就是个人博客的粉丝页。
网页分析分三步走战略
-
第一步,以鄙人为例,鼠标悬浮在博客头像,点击粉丝。
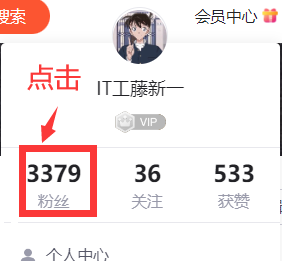
-
第二步,进入粉丝页后点击键盘的F12(或者点击鼠标右键,点击网页检查)后会弹出一个进行网页分析的窗口,点击窗口上的网络,然后在筛选输入框中输入:get-fans,接着刷新一下页面,即可看到装有粉丝数据的数据包。
- 注意:如果不出意外的话那就出意外了😜,这时我们可能只看到一个数据包,出现这种情况别慌,鼠标放在页面上滚动即可,这时就会看到有多个数据包冒出。(拿捏了老铁们儿😎)
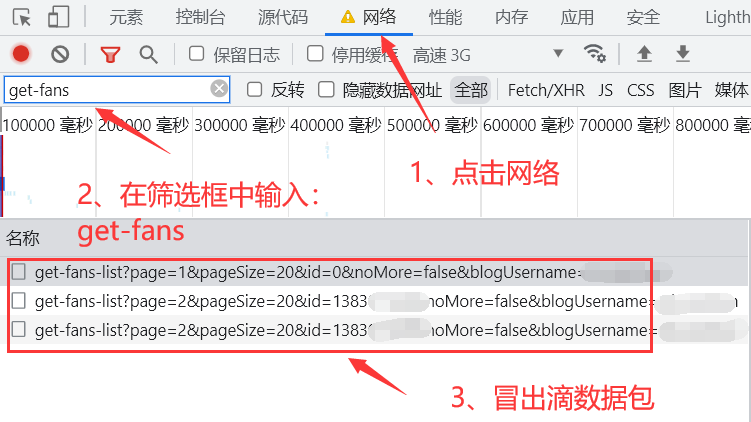
- 注意:如果不出意外的话那就出意外了😜,这时我们可能只看到一个数据包,出现这种情况别慌,鼠标放在页面上滚动即可,这时就会看到有多个数据包冒出。(拿捏了老铁们儿😎)
-
第三步,点击数据包,点击预览,即可看到粉丝的相关数据,关键来了,这些数据中没有我们想要的IP所属地,你说,这咋整。我说,先别急,先分析分析里面有啥。
- 经过哥的一整套稀里哗啦的分析,真相只有一……(先别逼叨了)其实发现数据包中有两个主要信息:粉丝博客链接、粉丝的id,这些信息有什么用呢?
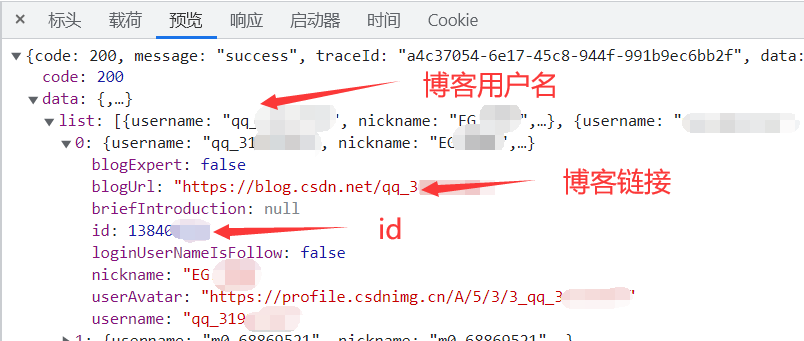
- 经过哥的一整套稀里哗啦的分析,真相只有一……(先别逼叨了)其实发现数据包中有两个主要信息:粉丝博客链接、粉丝的id,这些信息有什么用呢?
-
第四步(哈哈哈,被虚晃了吧),又经过哥的一套叽叽喳喳的分析,发现粉丝博客链接中,也就是粉丝的博客主页有我们想要的IP所属地
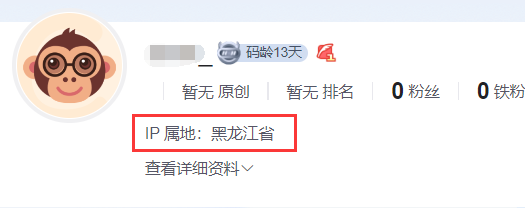
-
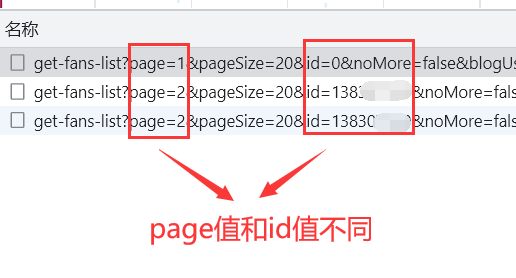
而id呢,id的作用就是获取下一个数据包的所有粉丝信息。通过分析数据包的链接可以发现,数据包中只有两个地方不同:page值和id值,于是再回到数据包本身,每个粉丝都有id,那么哪一个id是下个数据包链接中的id呢?答案是:最后一个粉丝的id(这时候我应该听到掌声雷动了)
🌴源代码
根据以上稀里哗啦叽叽喳喳的操作,我们来编写代码。
代码编写思路:
- 先对网页分析抓到的第一个数据包发送请求,获取到我们想要的博客链接和id值,然后设置一个page值,它的值自增加一,获取到的id值我们只需要最后一个粉丝的id值,最后拼接链接,重新发送请求,再重复以上步骤。
- 等获取了所有的博客链接,我们使用多线程的方式对所有博客链接发送请求,获取IP所属地,最后保存在json文件中。
注意两点:
- https://blog.csdn.net/community/home-api/v2/get-fans-list?page=1&pageSize=20&id={id}&noMore=false&blogUsername=,最后的等号后面写上自己的博客名
- ‘User-Agent’: ‘’,使用自己的User-Agent哈
源码如下👇
(如有错误,请在评论区中指出哦~😁)
import requests
import json
import threading
from jsonpath import jsonpath
import re
import time
# 博客名和博客链接
def fans\_data():
li_name = [] # 存储博客名
blogUrl = [] # 存储博客链接
id = 0
i = 0
while True:
if i == 0: # 如果是第一页的粉丝数据
url = f'https://blog.csdn.net/community/home-api/v2/get-fans-list?page=1&pageSize=20&id={id}&noMore=false&blogUsername='
else:
url = f'https://blog.csdn.net/community/home-api/v2/get-fans-list?page={i+1}&pageSize=20&id={id}&noMore=false&blogUsername='
try:
res = requests.get(url, headers=headers)
json_data = json.loads(res.text)
# 获取粉丝博客名
li_name += jsonpath(json_data, '$..username')
# 获取粉丝博客链接
blogUrl += jsonpath(json_data, '$..blogUrl')
# 获取粉丝博客id
id = jsonpath(json_data, '$..id')[-1]
print(id)
except:
break
i += 1
print(f'第{i}页粉丝数据获取成功!')
return li_name, blogUrl
# 获取粉丝的ip所属地
def fans\_area(url):
res = requests.get(url, headers=headers)
try:
area = re.findall('"region":"IP 属地:(.\*?)","msg"', res.text)[0]
except:
area = ''
li_area.append(area)
print('IP所属地获取成功!')
# 将粉丝的所属地和博客名保存到json文件中
def save\_json():
with open('CSDN粉丝信息.json', 'a', newline="", encoding='utf-8') as f:
for i in range(len(li_name)):
data = {'name':li_name[i], 'area':li_area[i]}
# 将字典转换成json数据
data_str = json.dumps(data, ensure_ascii=False)
f.write(data_str + ',' + '\n')
print('CSDN粉丝信息.json 文件保存成功!')
if __name__ == '\_\_main\_\_':
headers = {
'User-Agent': ''
}
li_area = [] # 存储所有粉丝的所属地
threads = []
li_name, blogUrl = fans_data() # 接收粉丝名和博客链接
print('-----开始获取粉丝所属地-----')
for i in blogUrl:
threads.append(threading.Thread(target=fans_area(i)))
for t in threads:
t.start()
save_json()
print(len(li_name))
效果展示👇
🌲数据清洗和保存
我们主要的目的就是获取所有粉丝的IP所属地并统计各个省份中的所有粉丝数量,然后在中国地图上展示出来。
于是我们需要对爬取到的信息进行清洗。
具体思路:使用强大的数据分析工具——pandas,通过它统计各个省份中的所有粉丝数量,然后将爬取的IP所属地信息进行清洗,将省、区、市这些词从IP所属地中删除,比如:将广西省清洗为广西。最后将所有统计和清洗的结果保存在json文件中。
🌴源代码
源码如下👇
(如有错误,请在评论区中指出哦~😁)
import pandas as pd
import json
from jsonpath import jsonpath
# 读取CSDN粉丝信息.json的内容
def read\_file():
li_area = []
with open('CSDN粉丝信息.json', 'r', encoding='utf-8') as f:
# 获取信息库中的json数据,并转换为Python字符串
data = json.load(f)
# 获取粉丝名字
fans_name = jsonpath(data, '$..name')
# 获取粉丝所属IP地址
fans_area = jsonpath(data, '$..area')
# 清洗数据
for i in fans_area:
if '省' in i or '市' in i:
li_area.append(i[:-1])



**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
7443)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**















 428
428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









