









既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
| 方法名 | 说明 |
|---|---|
| sort() | 升序排序 |
| sort(reverse = True) | 降序排序 |
| reverse() | 反转列表 |
需要注意的是,升序排序对于数字而言是从小到大;对于字符串和字符而言,是字典顺序,比如 a 比 z 小
🐯 参考示例代码:
words = ["abc", "Abc", "z", "dbff"]
nums = [9, 8, 4, 2, 2, 3]
# 升序排序
words.sort()
nums.sort()
print(words) # ['Abc', 'abc', 'dbff', 'z']
print(nums) # [2, 2, 3, 4, 8, 9]
# 降序排序
words.sort(reverse=True)
nums.sort(reverse=True)
print(words) # ['z', 'dbff', 'abc', 'Abc']
print(nums) # [9, 8, 4, 3, 2, 2]
# 反转
nums.reverse()
print(nums) # [2, 2, 3, 4, 8, 9]
🐔 结果: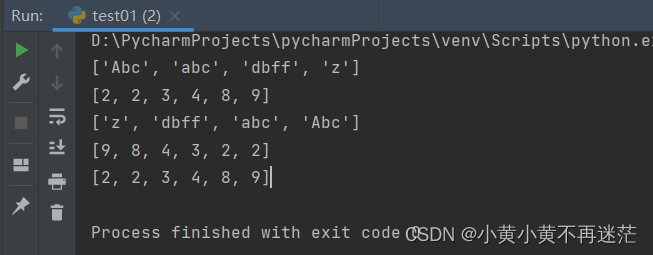
1.3 列表的迭代遍历
🆔 遍历是指从头到尾依次从列表中获取数据,使用 for 循环就很容易实现,语法基础格式如下:
# for 循环内部使用的变量 in 列表
for name in name_list:
# 循环内部对列表进行的操作
print(name) # 比如打印
🐱 示例代码与结果:
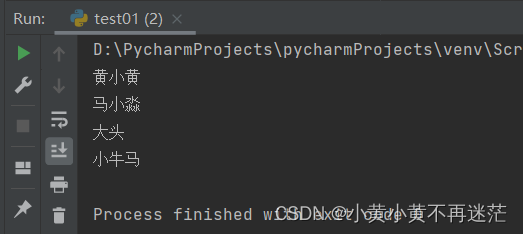
student_list = ["黄小黄", "马小淼", "大头", "小牛马"]
# 迭代遍历
for student in student_list:
print(student)
2 元组
2.1 元组说明
Tuple元组与列表类似,最大的区别是元组的 元素不能修改- 元组表示多个元素组成的序列,用于存储一串信息,数据之间使用
,分隔; - 元组使用
( )定义,索引从0开始。
示例1️⃣ 创建一个空元组
tuple = ()
示例2️⃣ 创建一个元组
tuple = ("黄小黄", "路飞", "娜美")
元组只包含一个元素时,需要在元素后面加 ,
2.2 元组的常用操作
由于元组中的元素是不可变的,因此 python 提供的元组方法通常为只读,常用的有
index()和count()
👂 示例代码与结果:
my_tuple = ("黄小黄", "马小淼", "草帽路飞", "黄小黄")
# 读取索引
print(my_tuple.index("马小淼")) # 1
# 统计出现次数
print(my_tuple.count("黄小黄")) # 2
2.3 元组的迭代遍历
🐒 与列表的遍历类似,但是在实际开发中,我们并不常常遍历元组,除非能够确认 元组中元素的数据类型。
# for 循环内部使用的变量 in 元组
for name in name_touple:
# 循环内部对元组进行的操作
print(name) # 比如打印
🐴小结: 在 Python 中可以使用 for 循环遍历所有非数字类型的变量:列表、元组、字符串以及字典
2.4 元组与列表的相互转化
- 元组转化为列表,通过
list函数实现 - 列表转化为元组,通过
tuple函数实现
🐴 参考代码:
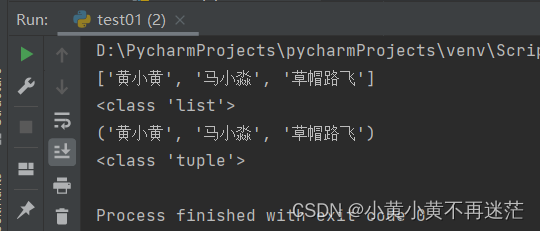
temp_tuple = ("黄小黄", "马小淼", "草帽路飞")
my_list = list(temp_tuple)
print(my_list)
print(type(my_list))
my_tuple = tuple(my_list)
print(my_tuple)
print(type(my_tuple))
🏠 结果:
3 字典
3.1 字典说明
- 字典使用
{}定义,是 无序的对象集合; - 字典使用 键值对 存储数据,其间使用
,分隔; - 键
key是索引,值value是数据; - 键值之间使用
:分隔; - 键必须是唯一的,且必须为字符串、数字或元组,值可以为任何数据类型。
🐇 下面我们来简单定义一个字典,代码如下:
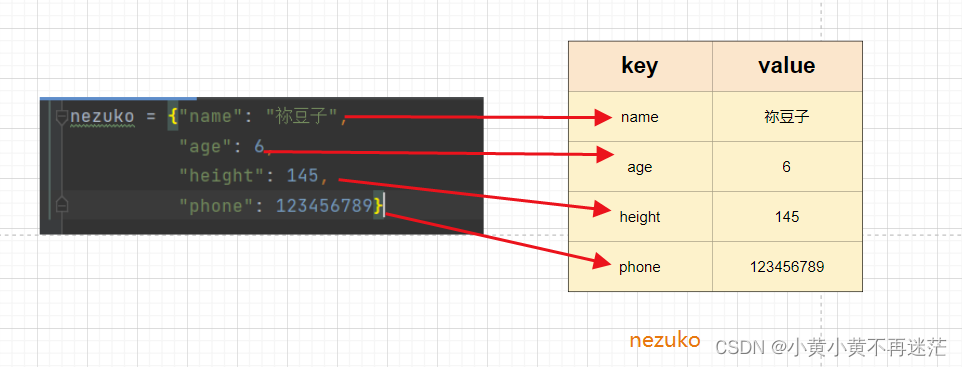
nezuko = {"name": "祢豆子",
"age": 6,
"height": 145,
"phone": 123456789}
通过图示,详细了解字典的存储结构:
3.2 字典的常用操作
3.2.1 字典的查找与增删改
⭕️ 通过对列表和元组的学习,想必已经对索引取值已经增添删除数据有了一定的认识,这里直接上代码举例:
🐘 1. 查找值
字典的取值同样通过索引的方式来取值,只不过,字典的索引是key。需要注意的是,进行取值操作时,如果指定的key不存在,程序会报错!
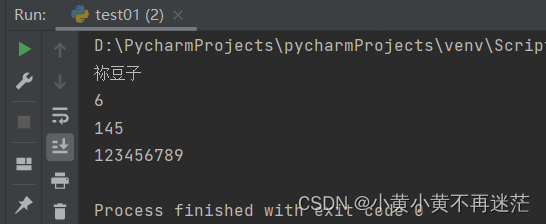
nezuko = {"name": "祢豆子",
"age": 6,
"height": 145,
"phone": 123456789}
# 查找值,取值
print(nezuko["name"])
print(nezuko["age"])
print(nezuko["height"])
print(nezuko["phone"])
🐖 2. 增添及修改值
在 python 中增添与修改值很简单,只需要使用索引添加或修改。如果key存在,则会修改数据;如果key不存在,则会新增键值对。
nezuko = {"name": "祢豆子",
"age": 6,
"height": 145,
"phone": 123456789}
# 添加
nezuko["性别"] = "女"
# 修改
nezuko["age"] = 3
# 打印
print(nezuko)

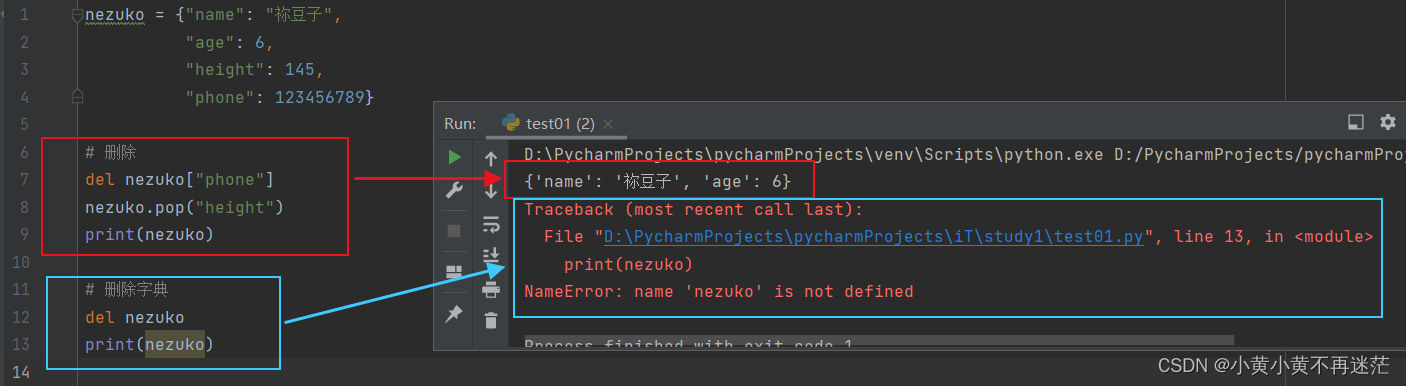
🐻 3. 删除值与字典
删除有两种方式,使用 pop() 方法指定 key 删除或者使用关键字 del 并指定 key 删除。当然,也可以通过 del 关键字删除字典。
nezuko = {"name": "祢豆子",
"age": 6,
"height": 145,
"phone": 123456789}
# 删除
del nezuko["phone"]
nezuko.pop("height")
print(nezuko)
# 删除字典
del nezuko
print(nezuko)
3.2.2 字典的统计、合并与清空
🍊 涉及到的方法一览表:
| 方法名 | 说明 |
|---|---|
| len(dict) | 统计字典键值对的数量 |
| update(temp_dict) | 将 update_dict 字典与原字典合并,如果被合并的字典包含已经存在的键值对,会覆盖原有的键值对 |
| clear() | 清空字典中的所有元素 |
🐴 示例代码:
nezuko = {"name": "祢豆子",
"age": 6,
"height": 145,
"phone": 123456789}
# 统计键值对个数
nezuko_count = len(nezuko)
print("字典 nezuko 键值对个数为: %d" % nezuko_count)
# 合并两个字典
nezuko_new = {"性别": "女",
"爱好": "咬竹筒",
"age": 10}
nezuko.update(nezuko_new)
print("合并后" + str(nezuko))
# 清空列表元素
nezuko.clear()
print("清空后: " + str(nezuko))
🍎 结果:

3.3 字典的迭代遍历
🐒 在实际开发中,字典的遍历需求并不多,因为我们无法确定字典中的每一个键值对保存的数据类型。
🆔 遍历语法:
# for 循环内部使用的 key 变量 in 字典名
for k in dict:
# 具体操作
print("%s: %s" % (k, dict[k]))
🐱 示例代码及结果:
commodities = {"商品名称": "洗发水",
"价格": "$8.99"}
# 遍历
for k in commodities:
print("%s \t: %s" % (k, commodities[k]))

3.4 字典与列表综合应用场景
- 使用 多个键值对,描述一个物品的相关信息;
- 将 多个字典放在一个列表中,在循环体内部针对每一个字典进行相同的处理
🐈 示例代码与结果:
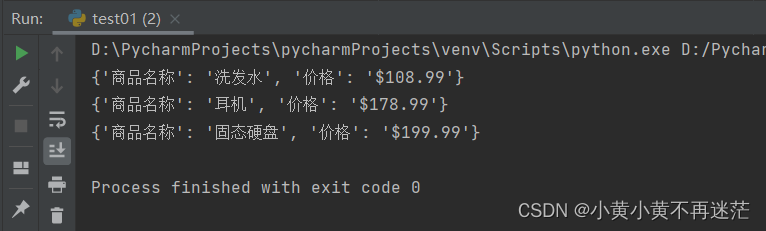
尝试将物品信息存储为字典,并将所有物品存储到列表中进行遍历修改
commodities_list = [
{"商品名称": "洗发水", "价格": "$8.99"},
{"商品名称": "耳机", "价格": "$78.99"},
{"商品名称": "固态硬盘", "价格": "$99.99"},
]
# 遍历 给所有商品价格增加100 并打印
for commodity in commodities_list:
# 这里使用了 lstrip 对字符串进行了首字符删除 后面会讲 先忽略
commodity["价格"] = "$" + str(float(commodity["价格"].lstrip("$")) + 100)
print(commodity)
写在最后
🌟以上便是本文的全部内容啦,后续内容将会持续免费更新,如果文章对你有所帮助,麻烦动动小手点个赞 + 关注,非常感谢 ❤️ ❤️ ❤️ !
如果有问题,欢迎私信或者评论区!

共勉:“你间歇性的努力和蒙混过日子,都是对之前努力的清零。”




既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
(https://img-blog.csdnimg.cn/a1397a96b231496891ed9550209c5de9.gif#pic_center)
[外链图片转存中…(img-BoO5zis9-1715500332605)]
[外链图片转存中…(img-fntO8cSl-1715500332606)]
[外链图片转存中…(img-XGFVbm89-1715500332606)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









