







 本文介绍了网易云音乐机器学习平台在支持大规模图神经网络和模型升级方面的实践。面对业务挑战,平台升级到TF2.6,提升了训练速度和推理性能,支持CUDA11和Nvidia TF1.15。通过MIG技术,提高了整体吞吐率。同时,为解决大规模图数据处理,平台采用PGL和k8s组件,实现图存储、采样与分布式训练。功能层方面,平台提供了端到端的机器学习支持,包括数据样本服务、特征算子开发、模型训练和部署,显著提升了开发效率和模型服务质量。
本文介绍了网易云音乐机器学习平台在支持大规模图神经网络和模型升级方面的实践。面对业务挑战,平台升级到TF2.6,提升了训练速度和推理性能,支持CUDA11和Nvidia TF1.15。通过MIG技术,提高了整体吞吐率。同时,为解决大规模图数据处理,平台采用PGL和k8s组件,实现图存储、采样与分布式训练。功能层方面,平台提供了端到端的机器学习支持,包括数据样本服务、特征算子开发、模型训练和部署,显著提升了开发效率和模型服务质量。
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新HarmonyOS鸿蒙全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

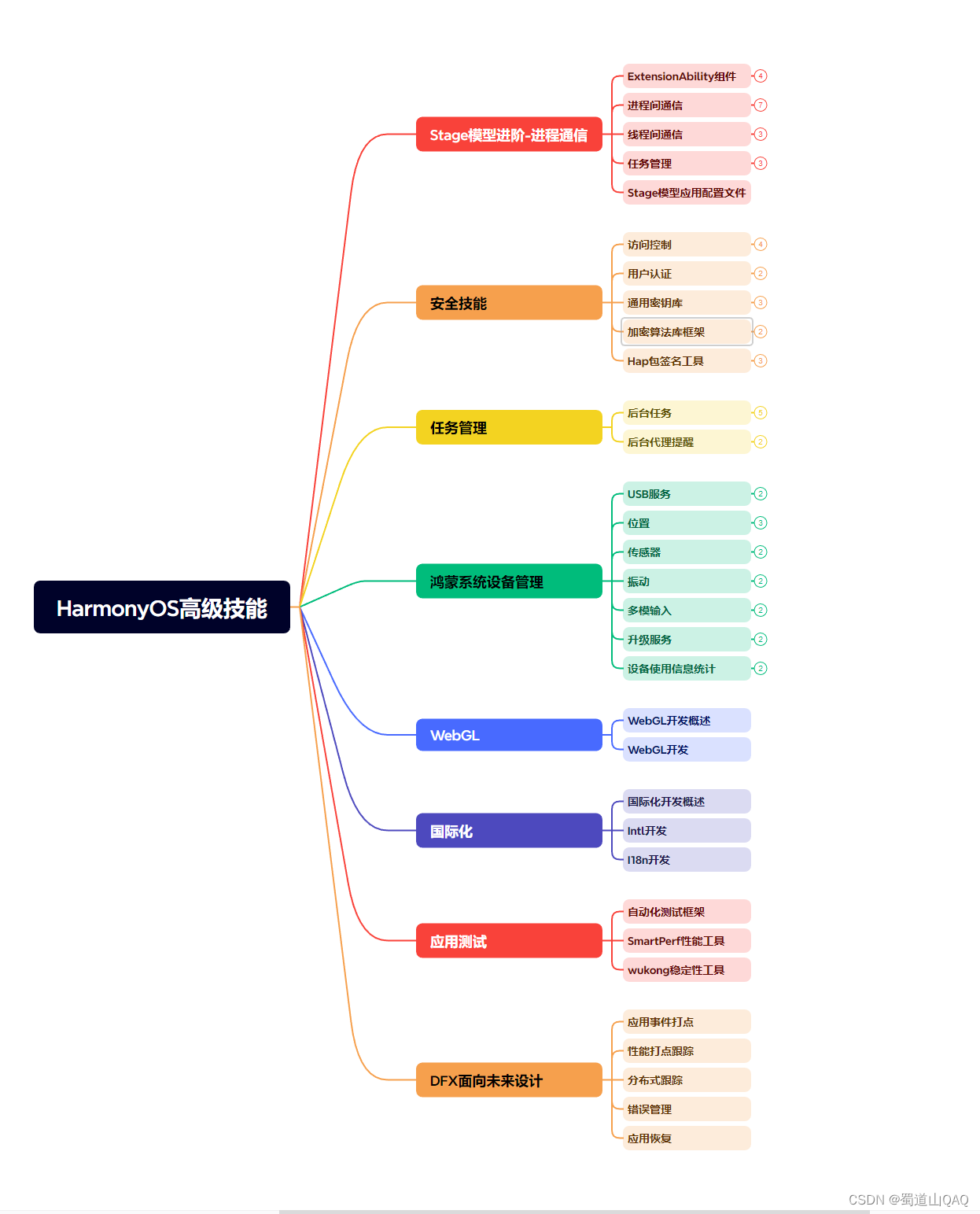


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上鸿蒙开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注鸿蒙)

正文
- 针对目前各个业务组内维护的Java jni 模型推理的情况,如果需要使用新硬件进行模型训练,需要支持至少CUDA11的对应的TF版本(2.4以上);
- 模型训练侧代码, 目前版本为TF1.12-TF1.14之间;
基于这样的背景, 我们完成机器学习平台TF2.6版本的全流程支持,从样本读写、模型训练、模型线上推理,全面支持TF2.6,具体的事项包括:
- 机器学习平台支持TF2.6以及Nvidia TF1.15两套框架来适配Cuda11;
- 考虑到单A100性能极强,在大部分业务的模型训练中无法充分发挥其性能。因而,我们选择将一张A100切分成更小的算力单元,需要详细了解的可以关注nvidia mig 介绍,可以大大提升平台整体的吞吐率;
- mig的好处,能够大大地提升平台整体的吞吐率,但是A100经过虚拟化之后,显卡实例的调度以及相关的监控也是平台比较复杂的工作;
- 离线训练升级到较高版本之后,推理框架也需要升级,保证兼容TF1.x与TF2.x的框架产生的模型;
通过完成上述事项, 在完成A100 MIG能力的支持之后, 整体从训练速度、推理改造后的数据来看,大大超出预期,离线任务我们使用新显卡1/3的算力可以在常规的任务老版本算力上平均有40%以上的训练速度提升,最高有170%以上的提升,而线上推理性能,通过适配2.6的TensorFlow版本,在保证完全兼容TF1.X的线上版本的同时,获得20%以上的推理性能提升。在A100切分实例上,我们目前提供2g-10gb、3g-20gb、4g-40gb三类显卡实例,覆盖平台日常的任务类型,其他指标如稳定性均大大超过老版本算力。
大规模图神经网络
随着从传统音乐工具软件到音乐内容社区的转变,云音乐依托音乐主站业务,衍生大量创新业务,如直播、播客、K歌等。创新业务既是机遇也为推荐算法同学带来了挑战:用户在创新业务中的行为稀疏,冷启动现象明显;即使是老业务也面临着如下问题:
- 如何为新用户有效分发内容;
- 将新内容有效分发给用户;
我们基于飞桨图学习框架PGL,使用全站用户行为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2324
2324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









