







对 service 访问异常,coreDNS 已经被排除了,那先绕过 service,直接使用 ClusterIP 访问呢? 测试后现象依旧。另外关注公号“终码一生”,回复关键词“资料”,获取视频教程和最新的面试资料!
那再绕过 ClusterIP,直接使用 PodIP 呢? Bingo,之前会出问题的访问都是正常的了。
那么问题就出在 CluterIP – > PodIP 上, 那么又有以下可能:
ClusterIP 没有正确转发到 PodIP 上可能导致超时
- 如果正确转发,响应没有返回也可能导致超时
第一种可能性很容易排查,之前已经确认了 ipvs 规则、iptables 规则都是没有问题的,且通过 ClusterIP 发起的请求可以到达 PodIP 上, 基本就排除了可能性一
另外,对比正常跟异常请求会发现,异常的请求原 Pod 跟目标 pod 都是在同一个 Node 上,而正常的请求则处于不同的 Node,会是这个影响吗?
上面的可能性二,只能祭出抓包神器了tcpdump, 通过抓包发现(抓包过程见文未)会发现请求中出现了Reset
那么问题转换一下: 为什么相同 Node 上 podA 通过 service/ClusterIP 访问 PodB 响应会不返回呢,而通过 PodIP 访问就没问题?
补充一句就是,相同 Node 上的 pod 相互访问是不需要经过 Flannel 的,因此 Flannel 可以排除嫌疑
so, 问题在哪?
回到 tcpdump 的抓包数据, 可以发现,响应的数据没有按照请求的路径返回,嗯,Interesting
3、罪魁祸首
不管是 iptables 还是 ipvs 模式,Kubernetes 中访问 service 都会进行 DNAT,将原本访问 ClusterIP:Port 的数据包 DNAT 成 service 的某个 Endpoint (PodIP:Port),然后内核将连接信息插入 conntrack 表以记录连接,目的端回包的时候内核从 conntrack 表匹配连接并SNAT,这样原路返回形成一个完整的连接链路.
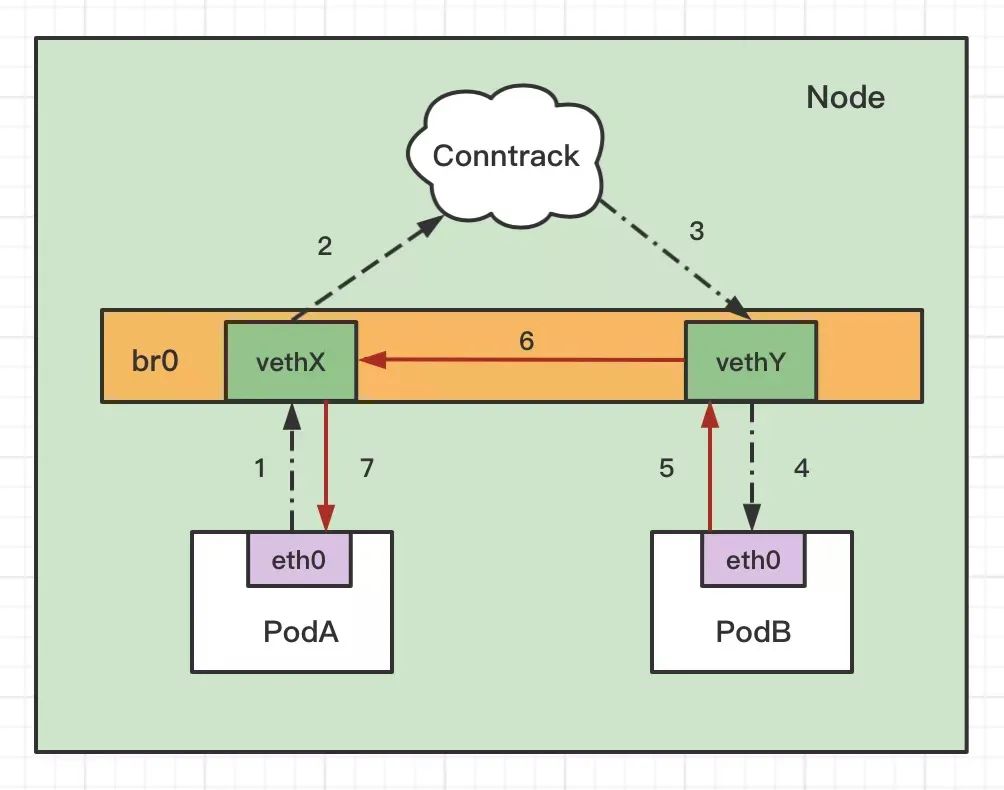
从 tcpdump 看到请求被 reset 了, 没错, bridge-nf-call-iptables(如果是 ipv6 的话则是net.bridg
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









