







接下来,我们就来看看数据同步的流程是怎样的。
二、数据同步
在介绍数据同步流程中,我们使用Learner代表所有非Leader服务器。
在集群服务器启动过程中,当整个集群完成Leader选举之后,Learner服务器会向Leader服务器进行注册,当所有服务器都注册完之后,就进入到了数据同步环节。数据同步过程就是Leader服务器将那些没有在Learner服务器上提交过的事务请求同步给Learner服务器。
大体过程如下:
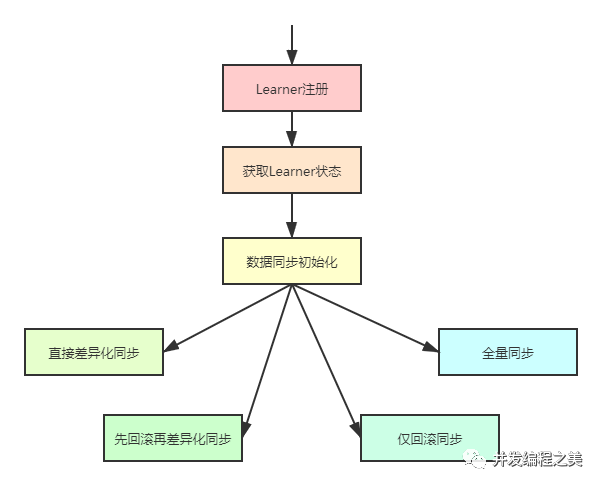
获取Learner状态
在注册Learner的最后阶段,Learner服务器会发送给Leader服务器一个ACKEPOCH数据包,Leader会从这个数据包中解析出该LearnerDE currentEpoch和lastZxid。
数据同步初始化
在开始数据同步之前,Leader服务器会进行数据同步初始化,首先会从Zookeeper的内存数据库中提取出事务请求对应的提议缓存队列proposals,同时完成以下三个ZXID值的初始化:
- peerLastZxid:该Learner服务器最后处理的ZXID
- minCommittedLog:Leader服务器提议缓存队列committedLog中的最小ZXID
- maxCommittedLog:Leader服务器提议缓存队列committedLog中的最大ZXID
Zookeeper集群数据同步分四类:直接差异化同步(DIFF同步)、先回滚再差异化同步(TRUNC+DIFF同步)、仅回滚同步(TRUNC同步)和全量同步(SNAP同步)。java培训在初始化节点,Leader服务器会优先初始化以全量同步方式来同步数据,但不是最终的同步方式,最终的同步方式会根据Leader和Learner服务器之间的数据差异情况来决定。
直接差异化同步(DIFF同步)
场景:peerLastZxid介于minCommittedLog和maxCommittedLog之间。
对于这种场景,直接使用直接差异化同步方式即可。Leader服务器会首先向这个Learner发送一个DIFF指令,用于通知Learner进入差异化数据同步阶段。在实际Proposal同步过程中,针对每个Proposal,Leader服务器都会通过发送两个数据包来完成,分别是PROPOSAL内容数据包和COMMIT指令数据包。
举例说明:假如某个时刻Leader服务器的提议缓存队列对应的ZXID依次是:
0x500000001、0x500000002、0x500000003、0x500000004、0x500000005
而Learner服务器最后处理的ZXID为0x500000003,于是Leader服务器就会依次将0x500000004和0x500000005两个提议同步给Learner服务器,同步过程中的数据包发送顺序如下:
| 发送顺序 | 数据包类型 | 对应的ZXID |
| 1 | PROPOSAL | 0x500000004 |
| 2 | COMMIT | 0x500000004 |
| 3 | PROPOSAL | 0x500000005 |
| 4 | COMMIT | 0x500000005 |
通过以上四个数据包的发送,Learner服务器就可以接收到自己和Leader服务器的所有差异数据,Leader服务器在发送完差异数据之后,就会将该Learner加入到forwardingFollowers或observingLearners队列中。随后Leader还会立即发送一个NEWLEADER指令,用于通知Learner已经将提议缓存队列中的Proposal都同步给你自己了。
接下来,我们看看Learner对Leader发送过来的数据包是如何处理的?
Learner首先会接收到一个DIFF指令,于是便确定了进入DIFF同步阶段。然后依次收到上述四个数据包,Learner会依次将其应用到内存数据库中,然后在接收到Leader的NEWLEADER指令后,Learner会反馈给Leader一个ACK消息,表明自己也完成了对提议缓存队列中Proposal的同步。
Leader在接收到来自Learner的这个ACK消息后,就认为当前Learner已经完成了数据同步,同时进入过半策略等待阶段,直到集群中有过半的Learner机器响应了Leader这个ACK消息。一旦满足过半策略后,Leader服务器就会向所有已经完成数据同步的Learner发送一个UPTODATE指令,用来通知Learner集群中已经有过半的机器完成了数据同步,集群已经具备了对外服务的能力了。
Learner在接收到这个来自Leader的UPTODATE指令后,会终止数据同步流程,然后向Leader再次反馈一个ACK消息。整个直接差异化同步过程中涉及的Leader和Learner之间的数据包通信如下图所示:

先回****滚再差异化同步(TRUNC+DIFF同步)
在上述场景中有一个罕见的特殊场景:假如有A、B、C三台机器,B是Leader,此时的Leader_epoch为5,当前已经被集群中大部分机器都提交的ZXID包括:0x500000001和0x500000002。此时,Leader正要处理0x500000003,并且已经将该事务写入到了Leader本地的事务日志中,就在Leader要将该Proposal发送给其他Follower机器进行投票的时候,Leader服务器挂了,开始新一轮选举,同时Leader_epoch变更为6,之后A和C继续对外进行服务,又提交了0x600000001和0x600000002两个事务,此时B再次启动,并开始数据同步。
简单来说,上面这个场景就是Leader服务器已经将事务记录到了本地事务日志中,但是没有成功发起Proposal流程的时候就挂了,在这个特殊场景汇总,我们看到peerLastZxid和minCommittedLog和maxCommittedLog的值分别是0x500000003、0x500000001和0x600000002,显然,peerLastZxid介于minCommittedLog和maxCommittedLog之间。
对于这种特殊场景,就是用先回滚再差异化同步的方式。当Leader服务器发现某个Learner包含了一条自己没有的事务记录,那么就需要让该Learner进行事务回滚,回滚到Leader服务器上存在的,同时也是最接近于peerLastZxid的ZXID。在上述示例中,Leader需要Learner回滚到ZXID为0x500000002的事务记录。
先回滚再差异化同步的数据同步方式在具体实现上和差异化同步是一样的,都会将差异化的Proposal发送给Learner,同步过程中的数据包发送顺序如下:
| 发送顺序 | 数据包类型 | 对应的ZXID |
| 1 | TRUNC | 0x500000002 |
| 2 | PROPOSAL | 0x600000001 |
| 3 | COMMIT | 0x600000001 |
| 4 | PROPOSAL | 0x600000002 |
| 5 | COMMIT | 0x600000002 |
仅回滚同步(TRUNC同步)
场景:peerLastZxid大于maxCommittedLog。
这种场景其实就是上述先回滚再差异化同步的简化模式,Leader会要求Learner回滚到ZXID值为maxCommitedLog对应的事务操作。
全量同步(SNAP同步)
场景1:peerLastZxid小于maxCommittedLog。
场景2:Leader上没有提议缓存队列,peerLastZxid不等于maxCommittedLog。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









