







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
4.3 配置文件准备
由于篇幅原因,这里不展示配置文件的具体内容,但是却是非常重要,重中之重,大家可以私信我获取!这是搭建HA高可用中的关键,是减少我们遇到 报错风暴 的必由之路。
这里要用到的配置文件有:core-site.xml,hdfs-site.xml,hadoop-env.sh,workers,yarn-site.xml,mapred-site.xml(都在hadoop/etc/hadoop目录下)zoo.cfg(zookeeper/conf/目录下),my_env.sh(/etc/profile.d/目录下),共8个文件。
这8个配置文件均已上传百度网盘!点我获取资料。
至此,我们的资料也准备好了!
五、解压与修改文件🍉
5.1 解压软件包
将上述我们准备好的Zookeeper、Hadoop、JDK软件包通过Xshell+Xftp上传到 /opt/software 目录下,并解压到 /opt/module/HA 目录下。

上传文件过程请大家自己完成哦!下面是解压过程:(该过程只需要在一台节点上完成即可,我这里使用的hadoop102,其他的节点后面使用克隆)。
- 创建HA目录
mkdir /opt/module/HA
- 解压JDK
tar -xzvf /opt/software/jdk-8u202-linux-x64.tar.gz -C /opt/module/HA/
- 解压Hadoop
tar -xzvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/HA/
- 解压Zookeeper
tar -xzvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/HA/
- 重命名Zookeeper
mv apache-zookeeper-3.5.7-bin/ zookeeper
- 重命名JDK
mv jdk1.8.0_202/ jdk1.8
5.2 修改配置文件
hadoop目录下的文件共六个,在资料中已经给出,下面仅展示一部分要特别注意的配置文件。
- 1.core-site.xml
- 2.hdfs-site.xml
- 3.hadoop-env.sh
- 4.workers
hadoop103
hadoop104
hadoop105
- 5.yarn-site.xml
- 6.mapre-site.xml
zookeeper目录下的文件
- 1.zoo.cfg
server.1=hadoop103:2888:3888
server.2=hadoop104:2888:3888
server.3=hadoop105:2888:3888
- 2.myid
这个节点上没有使用Zookeeper,所以未使用myid文件。
/etc/profile.d目录下的文件
- my_env.sh
# JAVA\_HOME
# 只需修改java\_home 因人而异 是自己的jdk安装目录
export JAVA\_HOME=/opt/module/jdk1.8
export PATH=$PATH:$JAVA\_HOME/bin
# HADOOP\_HOME
# 同理 这里只需修改Hadoop\_home,是Hadoop安装目录
export HADOOP\_HOME=/opt/module/HA/hadoop-3.1.3
export PATH=$PATH:$HADOOP\_HOME/bin
export PATH=$PATH:$HADOOP\_HOME/sbin
export HDFS\_NAMENODE\_USER=sky
export HDFS\_DATANODE\_USER=sky
export HDFS\_SECONDARYNAMENODE\_USER=sky
export YARN\_RESOURCEMANAGER\_USER=sky
export YARN\_NODEMANAGER\_USER=sky
# ZOOKEEPER\_HOME
export ZOOKEEPER\_HOME=/opt/module/HA/zookeeper
export PATH=$PATH:$ZOOKEEPER\_HOME/bin
之后记得刷新环境变量:
source /etc/profile.d/my_env.sh
5.3 创建目录
创建Hadoop数据临时目录:
mkdir /opt/module/HA/tmp
创建JournalNode日志目录:
mkdir /opt/module/HA/logs
创建Zookeeper数据目录:
mkdir /opt/module/HA/zookeeper/zkData
5.4 分发HA目录
分发HA目录下的所有内容到hadoop103,hadoop104,hadoop105上。
xsync /opt/module/HA/
六、启动HA集群🎈
6.1 Zookeeper启动测试
分别在hadoop103,hadoop104,hadoop105三个节点上启动Zookeeper,因为这三个节点在集群规划中有ZK。
zkServer.sh start



三个节点上的Zookeeper均启动成功!
6.2 启动JournalNode
分别在hadoop102,hadoop103,hadoop104三个节点上启动Zookeeper,因为这三个节点在集群规划中有JNN。
并且,JournalNode只需要手动启动一次,以后启动Hadoop HA高可用集群均不需要再次手动启动。
hdfs --daemon start journalnode
现在,我们通过jps来查看进程,ZK和JNN是否按照集群规划启动好了?




可以看到,目前集群规划正确,下面我们就可以进行下一步操作啦。
6.3 初始化NameNode
在是NameNode节点上的任意一个节点上初始化NameNode,并且只需要初始化一遍,这里我的集群中,hadoop102和hadoop103上都有NameNode,但是因为hadoop103上有DataNode,所以我 选择使用hadoop102作为初始化节点 。
hdfs namenode -format

6.4 初始化Zookeeper
在具有Zookeeper节点上的任意一个节点上初始化Zookeeper,并且只需要初始化一遍。这里我选择在hadoop103上进行初始化。
hdfs zkfc -formatZK

判断是否初始化成功:(在三台都查看一下)
zkCli.sh
ls \

6.5 启动集群
分别在hadoop102,hadoop103上启动NameNode。
hadoop102上执行:(只需执行一次)
hdfs --daemon start namenode
hadoop103上执行:(只需执行一次)
hdfs namenode -bootstrapStandby

在hadoop102上启动集群:
start-dfs.sh

至此,集群中的NameNode,DataNode,Zookeeper,ZKFC,JournalNode都已经启动好了。下面,让我们一起来看看,我们的集群能否经得住检验吧!
七、检验集群✨
7.1 jps检查
使用jpsall脚本分别查看四个节点上的jps进程信息,是否和集群规划相符,集群规划图再放一遍:
jpsall


和集群规划完全一致!
7.2 网页检查
分别访问NameNode1和NameNode2的两个Web页面,网址是http://hadoop102:9870,http://hadoop103:9870,结果如下:


网站访问中hadoop102的NameNode是active状态,hadoop103中的NameNode是standby状态。
7.3 自动故障转移检查
使用如下命令kill掉hadoop102上的NameNode进程:



这里,我们遇到了将NameNode-1的进程kill掉之后,另外一个NameNode没有变成active状态的问题,也就是说并没有实现自动故障转转移!
让我们一起来解决吧!
7.4 解决NameNode无法自动故障转移问题
这里引入一个 “脑裂” 的概念。
active namenode工作不正常后,zkfc在zookeeper中写入一些数据,表明异常,这时standby namenode中的zkfc读到异常信息,并将standby节点置为active。
但是,如果之前的active namenode并没有真的死掉,出现了假死(死了一会儿后又正常了),这样,就有两台namenode同时工作了。这种现象称为 脑裂 。
这里提供两种解决方案:
- 法一:改变kill方式——安装psmisc插件
上述中,我们使用kill掉NameNode进程的方法是:
kill -9 进程号
但是这种方式不一定能够完全 kill 掉NameNode的状态,可能就会出现残余从而出现“脑裂”现象,所以我们采用 psmisc插件 的方式来彻底结束进程。
更加神奇的是,这个插件安装好了,并不需要我们手动使用,而是系统自己调用的!

在hadoop102、hadoop103上按照psmisc插件:
sudo yum install -y psmisc
- 感受psmisc插件的威力
这里,我们先手动将hadoop102的NameNode启动起来,它目前是standby状态:
hdfs --daemon start namenode
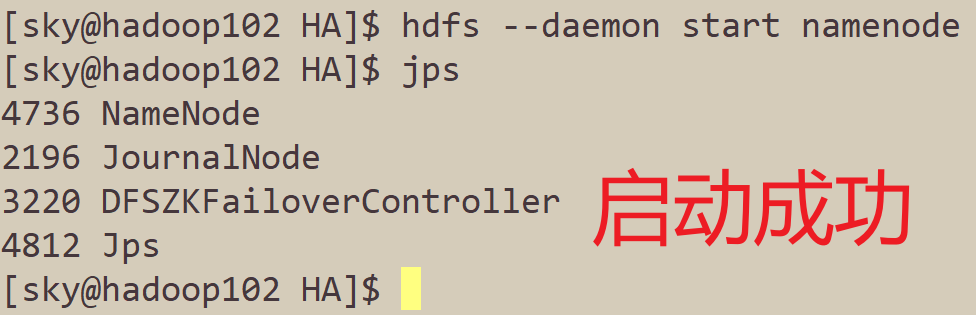
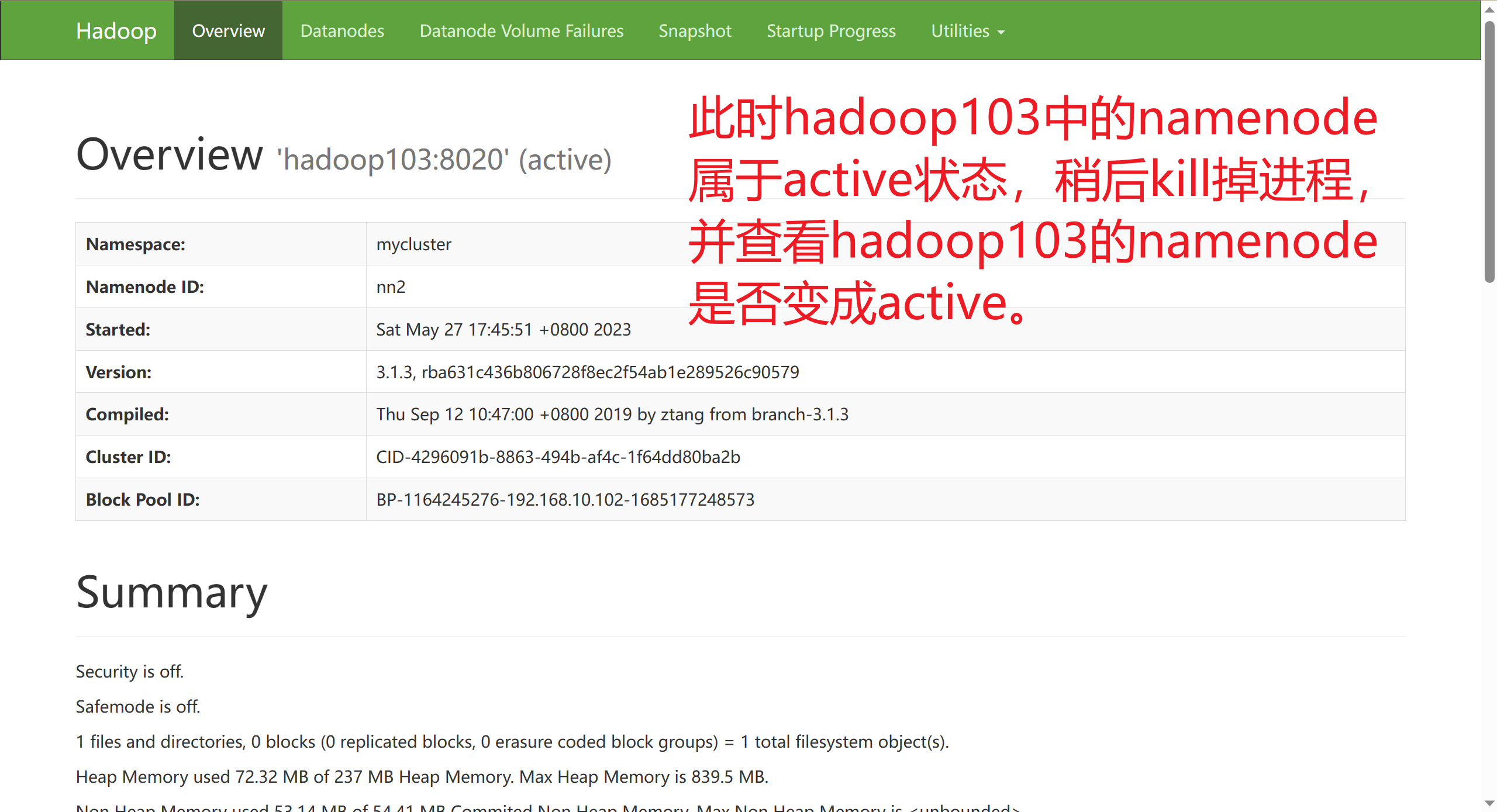
Kill掉Hadoop103的NameNode进程:

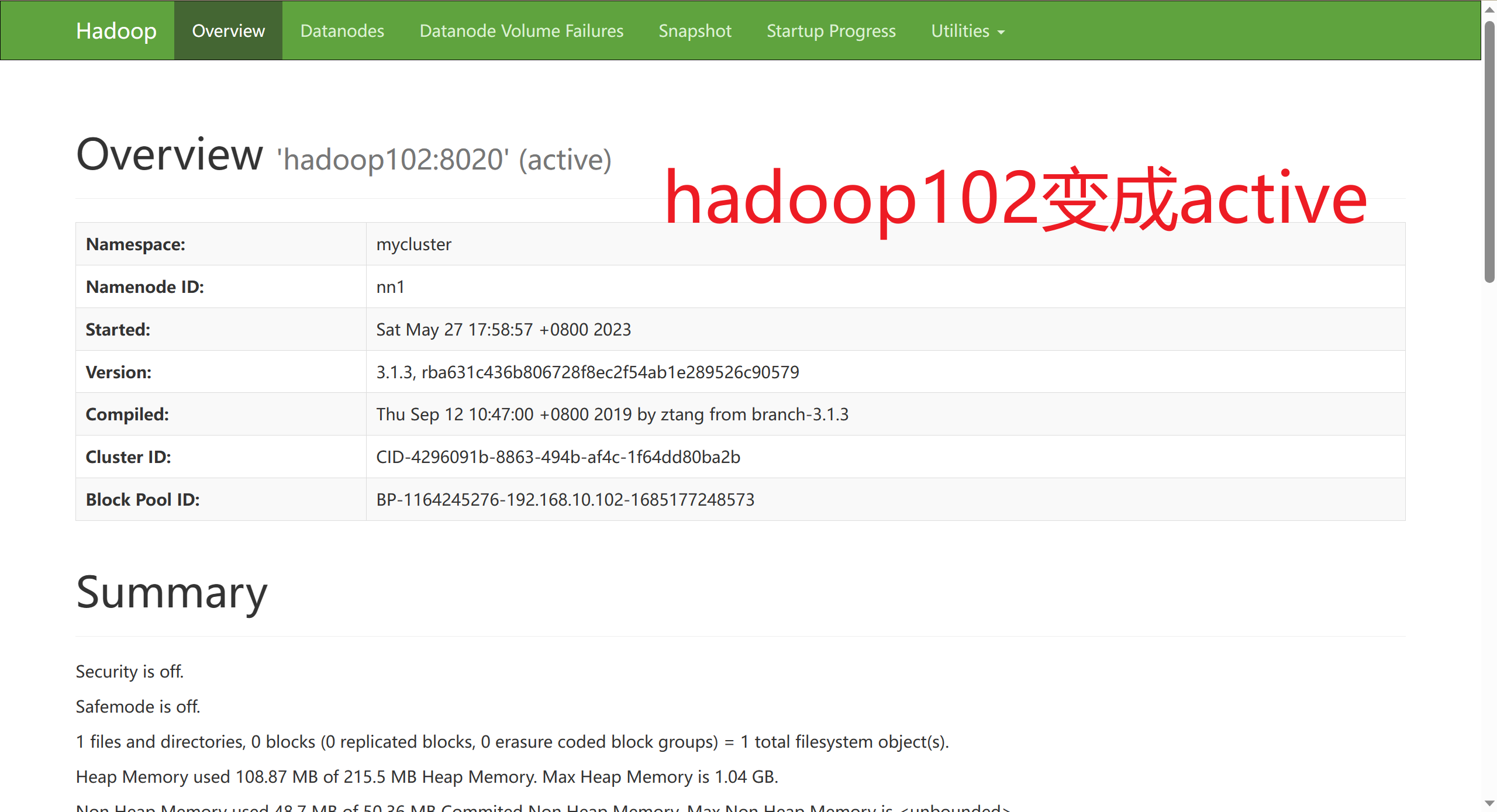
成功完成了NameNode的自动故障转移!
原理 :在备机准备上位的时候,它不管现在的主节点是不是真的挂机了,他都会使用远程登录技术ssh登录到主机上, 使用 killall namenode (这个killall就是psmisc插件的命令) 杀死它的namenode进程确保它真的结束了,有效的防止了出现“脑裂”的问题。
- 法二:修改hdfs-site.xml文件
ZFKC的机制中,HealthMonitor定期去检查namenode的健康状态,如果我们杀掉namenode的服务,该namenode及其端口都关闭了。
推测因为无法正常通信所以保守确定namenode是否真的失效的等等时间大大延长。
那么如何解决这个问题呢?
就是在hdfs-site.xml文件配置隔离机制的地方加上一行shell(/bin/true),改为:
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
这里不再演示效果,大家可以自行尝试哦!
八、日后HA启动方式🐮
之后即可使用 myHA 脚本进行启停了!



网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
这里不再演示效果,大家可以自行尝试哦!
## 八、日后HA启动方式🐮
之后即可使用 myHA 脚本进行启停了!



**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**
[外链图片转存中...(img-zRmJmY0Y-1713162300391)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1707
1707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









