







- 防误删:宕机自动释放临时节点,不需要设置过期时间,也就不存在误删问题。
- 加锁/解锁要具备原子性
- 单点问题:使用Zookeeper可以有效的解决单点问题,ZK一般是集群部署的。
- 集群问题:zookeeper集群是强一致性的,只要集群中有半数以上的机器存活,就可以对外提供服务。
基本实现
实现思路:
- 多个请求同时添加一个相同的临时节点,只有一个可以添加成功。添加成功的获取到锁
- 执行业务逻辑
- 完成业务流程后,删除节点释放锁。
初始化链接
由于zookeeper获取链接是一个耗时过程,这里可以在项目启动时,初始化链接,并且只初始化一次。借助于spring特性,代码实现如下:
@Component
public class zkClient {
private static final String connectString = "192.168.107.135";
private static final String ROOT_PATH = "/distributed";
private ZooKeeper zooKeeper;
@PostConstruct
public void init() throws IOException {
this.zooKeeper = new ZooKeeper(connectString, 30000, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
System.out.println("zookeeper 获取链接成功");
}
});
//创建分布式锁根节点
try {
if (this.zooKeeper.exists(ROOT_PATH, false) == null) {
this.zooKeeper.create(ROOT_PATH, null,
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@PreDestroy
public void destroy() {
if (zooKeeper != null) {
try {
zooKeeper.close();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
* 初始化分布式对象方法
*/
public ZkDistributedLock getZkDistributedLock(String lockname){
return new ZkDistributedLock(zooKeeper,lockname);
}
}
代码落地
public class ZkDistributedLock {
public static final String ROOT_PATH = "/distribute";
private String path;
private ZooKeeper zooKeeper;
public ZkDistributedLock(ZooKeeper zooKeeper, String lockname) {
this.zooKeeper = zooKeeper;
this.path = ROOT_PATH + "/" + lockname;
}
public void lock() {
try {
zooKeeper.create(path, null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
Thread.sleep(200);
lock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void unlock(){
try {
this.zooKeeper.delete(path,0);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
}
改造StockService的checkAndLock方法:
@Autowired
private zkClient client;
public void checkAndLock() {
// 加锁,获取锁失败重试
ZkDistributedLock lock = this.client.getZkDistributedLock("lock");
lock.lock();
// 先查询库存是否充足
Stock stock = this.stockMapper.selectById(1L);
// 再减库存
if (stock != null && stock.getCount() > 0) {
stock.setCount(stock.getCount() - 1);
this.stockMapper.updateById(stock);
}
lock.unlock();
}
Jmeter压力测试:
 性能一般,mysql数据库的库存余量为0(注意:所有测试之前都要先修改库存量为5000)
性能一般,mysql数据库的库存余量为0(注意:所有测试之前都要先修改库存量为5000)
基本实现存在的问题:
1. 性能一般(比mysql略好)
2. 不可重入
接下来首先来提高性能
优化:性能优化
基本实现中由于无限自旋影响性能:
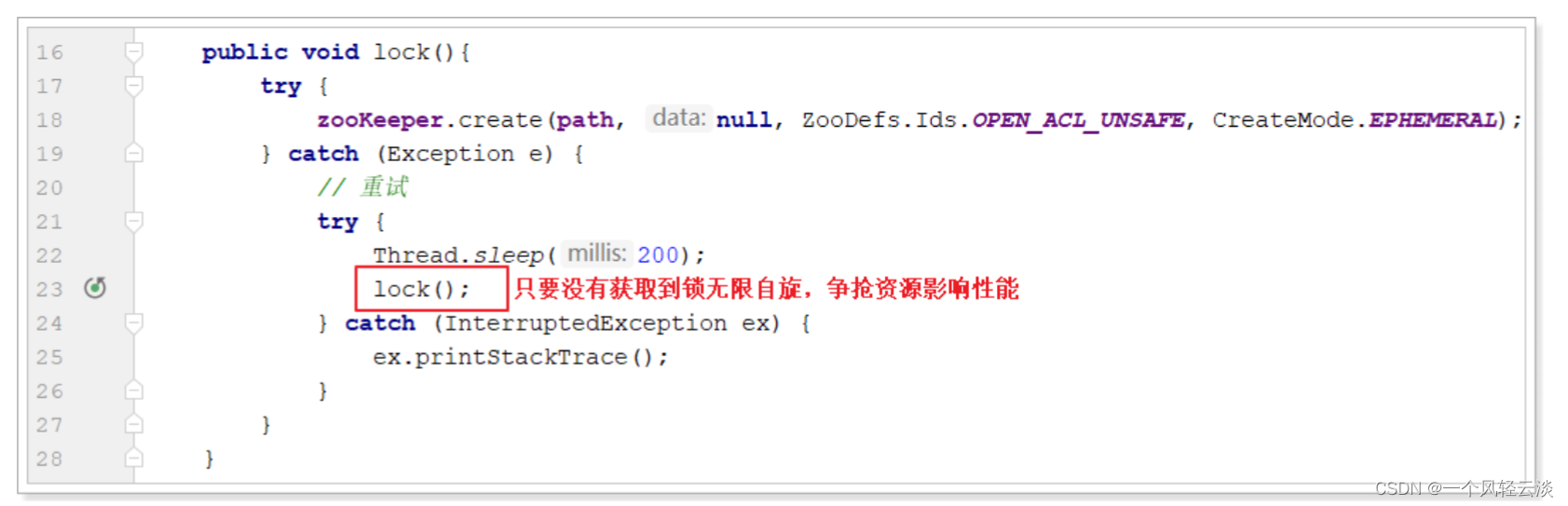
试想:每个请求要想正常的执行完成,最终都是要创建节点,如果能够避免争抢必然可以提高性能。这里借助于zk的临时序列化节点,实现分布式锁:

实现阻塞锁
代码实现:
public class ZkDistributedLock {
public static final String ROOT_PATH = "/distribute";
private String path;
private ZooKeeper zooKeeper;
public ZkDistributedLock(ZooKeeper zooKeeper, String lockname) {
this.zooKeeper = zooKeeper;
try {
this.path = zooKeeper.create(ROOT_PATH + "/" + lockname + "_",
null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void lock() {
String preNode = getpreNode(path);
//如果该节点没有前一个节点,说明该节点是最小的节点
if (StringUtils.isEmpty(preNode)) {
return;
}
//重新检查是否获取到锁
try {
Thread.sleep(20);
lock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/**
* 获取指定节点的前节点
*
* @param path
* @return
*/
private String getpreNode(String path) {
//获取当前节点的序列化序号
Long curSerial = Long.valueOf(StringUtil.substringAfter(path, '_'));
//获取根路径下的所有序列化子节点
try {
List<String> nodes = this.zooKeeper.getChildren(ROOT_PATH, false);
//判空处理
if (CollectionUtils.isEmpty(nodes)) {
return null;
}
//获取前一个节点
Long flag = 0L;
String preNode = null;
for (String node : nodes) {
//获取每个节点的序列化号
Long serial = Long.valueOf(StringUtil.substringAfter(path, '_'));
if (serial < curSerial && serial > flag) {
flag = serial;
preNode = node;
}
}
return preNode;
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
return null;
}
public void unlock() {
try {
this.zooKeeper.delete(path, 0);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
}
主要修改了构造方法和lock方法:
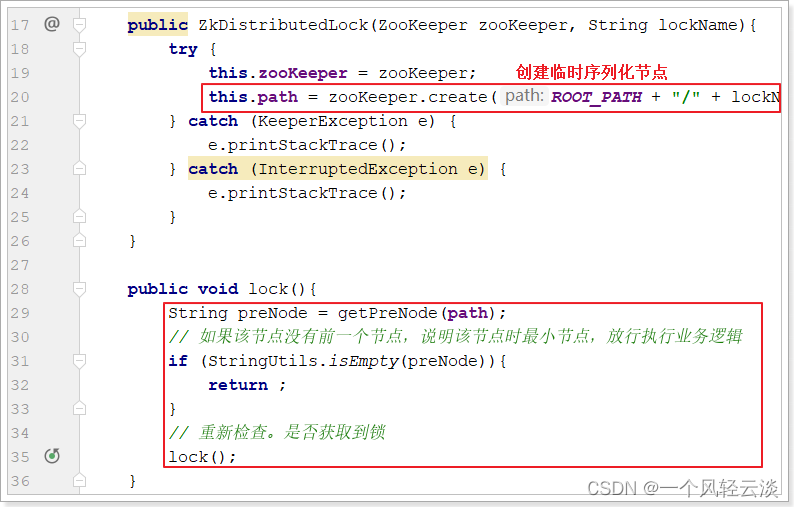
并添加了getPreNode获取前置节点的方法。
测试结果如下:

性能反而更弱了。
原因:虽然不用反复争抢创建节点了,但是会自选判断自己是最小的节点,这个判断逻辑反而更复杂更 耗时。
解决方案:监听实现阻塞锁
监听实现阻塞锁
对于这个算法有个极大的优化点:假如当前有1000个节点在等待锁,如果获得锁的客户端释放锁时,这1000个客户端都会被唤醒,这种情况称为“羊群效应”;在这种羊群效应中,zookeeper需要通知1000个 客户端,这会阻塞其他的操作,最好的情况应该只唤醒新的最小节点对应的客户端。应该怎么做呢?在 设置事件监听时,每个客户端应该对刚好在它之前的子节点设置事件监听,例如子节点列表 为/lock/lock-0000000000、/lock/lock-0000000001、/lock/lock-0000000002,序号为1的客户端监听 序号为0的子节点删除消息,序号为2的监听序号为1的子节点删除消息。
所以调整后的分布式锁算法流程如下:
- 客户端连接zookeeper,并在/lock下创建临时的且有序的子节点,第一个客户端对应的子节点 为/lock/lock-0000000000,第二个为/lock/lock-0000000001,以此类推;
- 客户端获取/lock下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子 节点,如果是则认为获得锁,否则监听刚好在自己之前一位的子节点删除消息,获得子节点变更通 知后重复此步骤直至获得锁;
- 执行业务代码;
- 完成业务流程后,删除对应的子节点释放锁。
改造ZkDistributedLock的lock方法:
public void lock() {
String preNode = getpreNode(path);
//如果该节点没有前一个节点,说明该节点是最小的节点
if (StringUtils.isEmpty(preNode)) {
return;
} else {
CountDownLatch countDownLatch = new CountDownLatch(1);
try {
if (this.zooKeeper.exists(ROOT_PATH + "/" + preNode, watchedEvent -> {
countDownLatch.countDown();
}) == null) {
return;
}
countDownLatch.await();
return;
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock();
}
}
压力测试效果如下:

由此可见性能提高不少仅次于redis的分布式锁
优化:可重入锁
引入ThreadLocal线程局部变量保证zk分布式锁的可重入性。
在对应的线程的存储数据
public class ZkDistributedLock {
public static final String ROOT_PATH = "/distribute";
private String path;
private ZooKeeper zooKeeper;
private static final ThreadLocal<Integer> THREAD_LOCAL = new ThreadLocal<>();
public ZkDistributedLock(ZooKeeper zooKeeper, String lockname) {
this.zooKeeper = zooKeeper;
try {
this.path = zooKeeper.create(ROOT_PATH + "/" + lockname + "_",
null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void lock() {
Integer flag = THREAD_LOCAL.get();
if (flag != null && flag > 0) {
THREAD_LOCAL.set(flag + 1);
return;
}
String preNode = getpreNode(path);
//如果该节点没有前一个节点,说明该节点是最小的节点
if (StringUtils.isEmpty(preNode)) {
return;
} else {
CountDownLatch countDownLatch = new CountDownLatch(1);
try {
if (this.zooKeeper.exists(ROOT_PATH + "/" + preNode, watchedEvent -> {
countDownLatch.countDown();
}) == null) {
return;
}
countDownLatch.await();
THREAD_LOCAL.set(1);
return;
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock();
}
}
/**
* 获取指定节点的前节点
*
* @param path
* @return
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**

**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)**

**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
)]
[外链图片转存中...(img-aRXafzZs-1713018319463)]
[外链图片转存中...(img-ejTLyXSk-1713018319463)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)**
[外链图片转存中...(img-BPXYjWbv-1713018319464)]
**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 2507
2507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









