








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
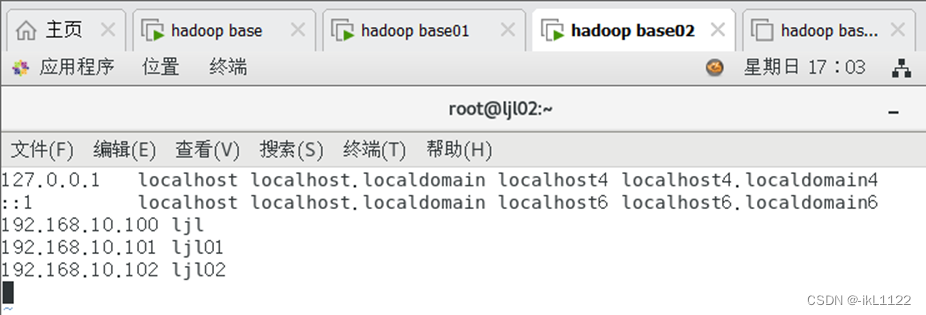
2.从机ip设置
启动两台从机,打开终端,修改主机名称分别为ljl01,ljl02。设置静态ip,与主节点ljl的hosts文件保持一致,设置成功重启网络。
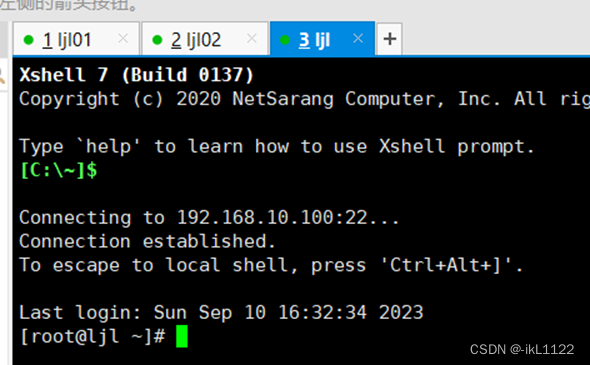
3.Xshell连接
打开Xshell7,左上角新建文件,在弹出框设置两个从节点的名称和ip地址,然后连接,随后输入root账号密码完成连接。
4.配置免密登录
回到主节点ljl,执行ssh-keygen -t rsa命令
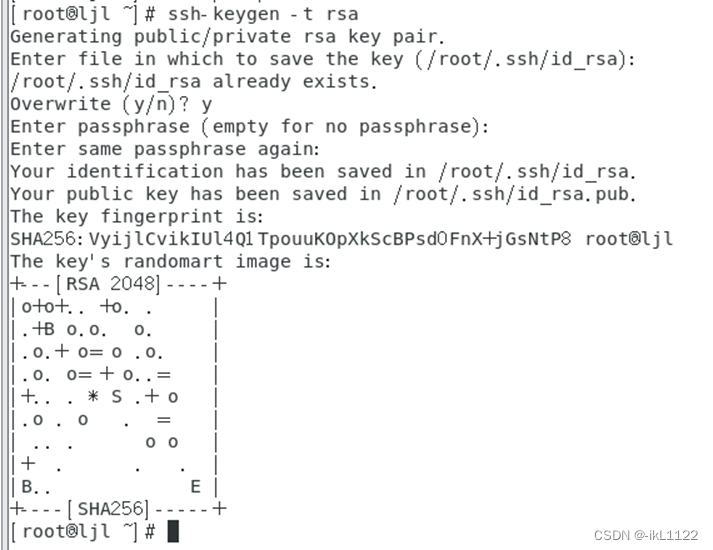
把公钥复制到各个节点,第一次登陆会让你输入密码
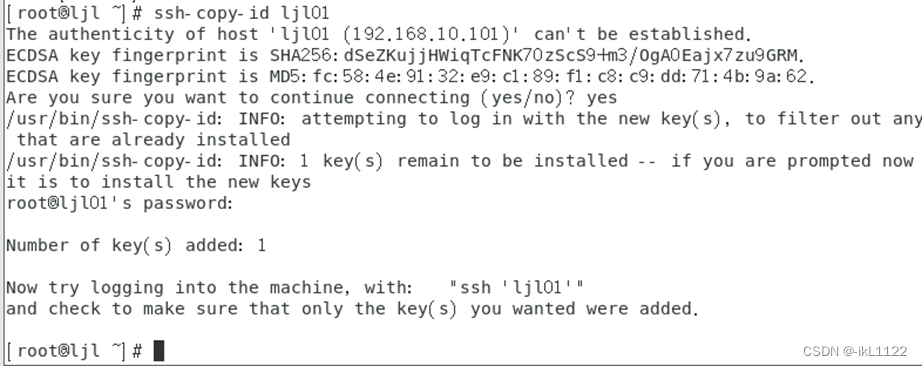
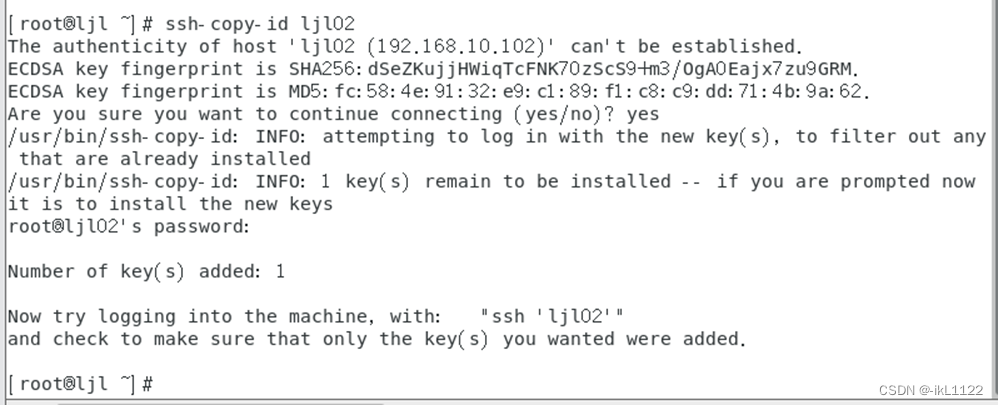
对自己也需要设置免密登录

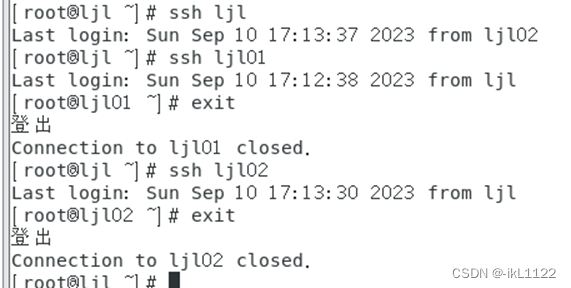
测试免密登录是否配置成功
测试成功之后,exit回到ljl节点
5.配置环境变量
在上一节,jdk和hadoop的环境变量都以配置好

6.配置hadoop-env.sh文件及其他重要文件
首先进入hadoop所在配置文件目录/usr/local/src/Hadoop-3.3.6/etc/hadoop,在此目录打开终端。
vim Hadoop-env.sh
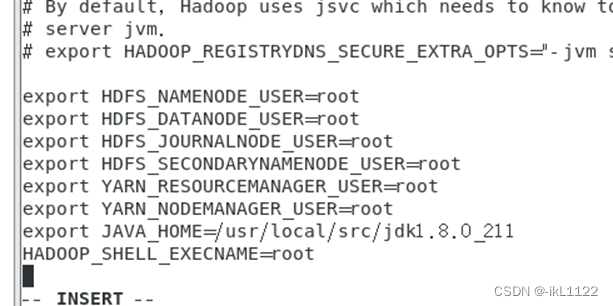
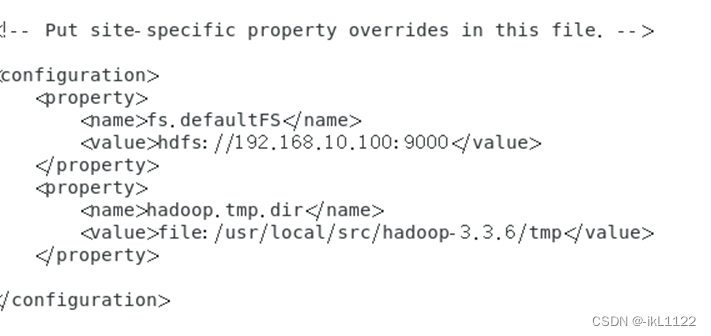
修改core-site.xml, vim core-site.xml
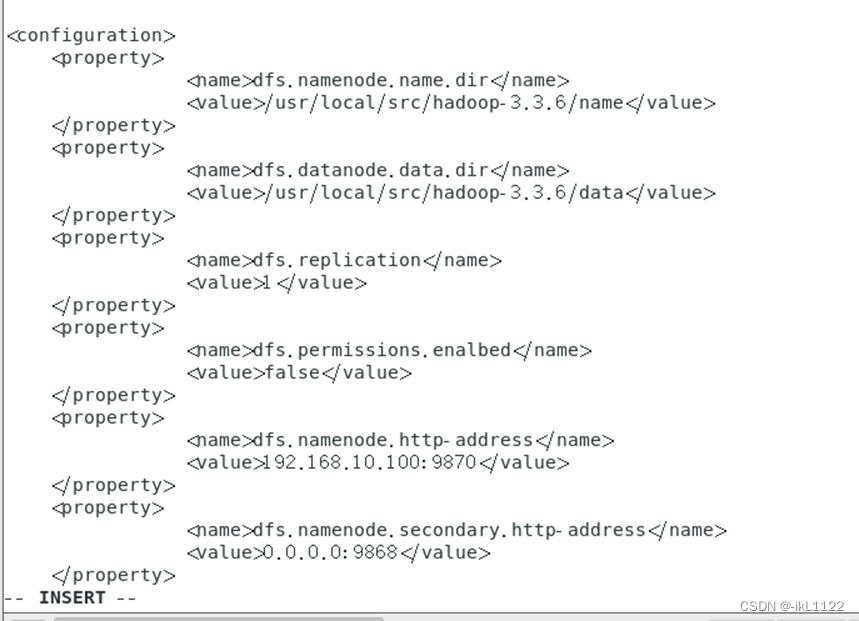
修改hdfs-site.xml文件
修改yarn-site.xml文件

修改mapred-site.xml文件

修改workers

7.分发文件
cd /usr/local/src# 分发jdk,$PWD:获取当前所在目录的绝对路径 scp -r jdk1.8.0_211 root@ljl01:$PWD scp -r jdk1.8.0_211 root@ljl02:$PWD # 分发hadoop scp -r hadoop-3.3.6 root@ljl01:$PWD scp -r hadoop-3.3.6 root@ljl02:$PWD # 分发/etc/hosts scp /etc/hosts root@ ljl01:/etc/ scp /etc/hosts root@ ljl02:/etc/ # 分发/etc/profile scp /etc/profile root@ ljl01:/etc/ scp /etc/profile root@ ljl02:/etc/

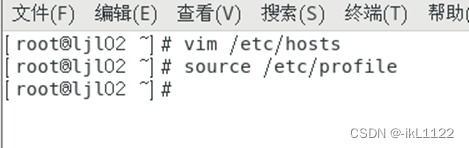
然后在两个从节点上执行 source /etc/profile

8.启动hadoop集群并测试
启动hdfs

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
转存中…(img-nz7j6zJ2-1715630821722)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 990
990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









