







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
#只有字段是Text时,字段后面才加“.ketword”
searchSourceBuilder.sort(“createTime.keyword”, SortOrder.DESC);
### 范围查询
#范围查询
boolQuery.must(QueryBuilders
.rangeQuery(“createTime.keyword”)
.gt(queryVO.getCreateTimeStart())
.lt(queryVO.getCreateTimeEnd()));
### ES分页查询
#### #查询前传入分页参数
#查询前传入分页参数
searchSourceBuilder.from((queryVO.getPageIndex() - 1) * queryVO.getPageSize()).size(queryVO.getPageSize());
#### #分页后拿到总记录数
searchHits.getTotalHits()
### ES倒排索引
把文档D对应到关键词的映射转换为关键词到文档ID的映射,每个关键词都对应着一系列的文档,这些文档中都出现这个关键词。
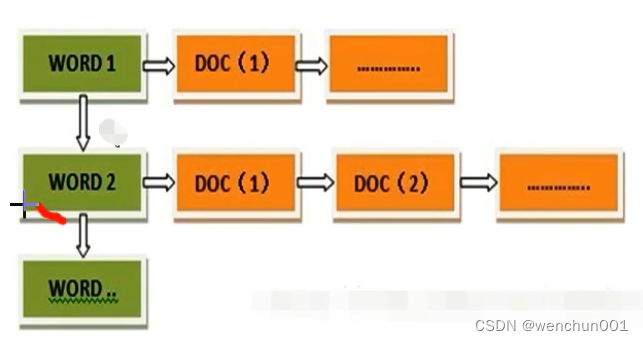
带有单词频率、文档频率和出现位置信息的倒排索引

#### 倒排表的压缩算法-FOR(Frame Of Reference)
#####
##### **倒排索引中采取的方案**
(1)无损压缩,文档编号重排序后用压缩算法进行压缩:确保在倒排表中相邻的两个文档的文档编号也相邻,这样D-Gap值也较小。希望内容越相似的文档其文档编号也越相似。 例子:包含“百度”的文档冲排序为文档编号相邻的文档,则创建“百度”倒排表时候,相邻的差值(D-Gap)则较小。百度-----D-Gap{1,4,9} 转化为 百度------D-Gap{1,1,1}, 要压缩的原始数据值变小,则获得较高的压缩率。 文档编号重新排序,可以依靠按照某些主题词来聚类,将同一个类的文档编号排成相邻的。
(2)有损压缩,静态索引裁剪:将不重要的索引项从倒排索引中清除,只保留重要的索引项。静态索引裁剪分为:
a、以单词为中心的索引裁剪 根据默认返回数目,设定每个单词的倒排表的项至少为k个,设计相似性函数,计算单词和文档的相似性得分,把分数小于设定阈值的文档信息从倒排表中裁剪掉。
b、以文档为中心的索引裁剪 在建立索引之前,把文档中不重要的词语删除掉。这样的话可能导致通用词或者停用词的倒排表为空。
\*\*\*\*\*\*\*故以单词为中心的索引裁剪是更加常用的方法。
#### 优缺点:
1)查询时能够一次得到查询关键字对应的所有文档,查间效率高于正向索引
2)每个字或词对应的文档数量都在动态变化。倒排表的建立和维护较复杂
#### 正向索引(如MySQL)
以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。

#### 优缺点:
1)索引建立和维护都比较容易
2)文本检索效率低
### 常见考点
#### 海量数据查询时为什么使用倒排索引会比较快?
在海量数据查询时,搜关键词,假设只存在正向索引(tnwrad index),那么就需要扫描索引库中的所有文档,找出所有包含关键j架构的文档;再根据打分模型进行打分,排出名次后呈现给用户。因为互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。
### ES版本演进
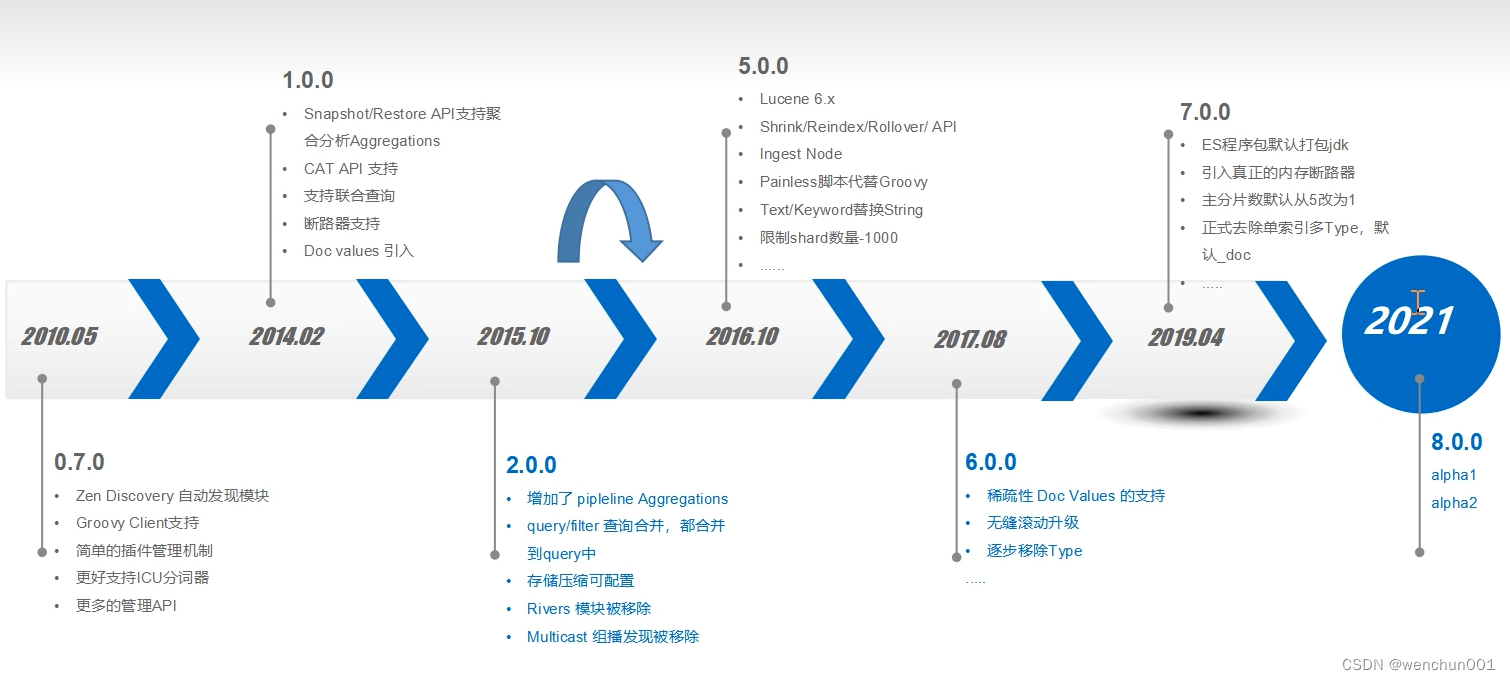
#### 0.7.0
* ##### Zen Discovery自动发现模块
* ##### Groovy Client支持
* ##### 简单的插件管理机制
* ##### 更好支持ICU分词器
* ##### 更多的管理API
#### 1.0.0
* ##### Snapshot/Restore API支持聚合分析Aggregations
* ##### CAT API支持
* ##### 支持联合查询
* ##### 断路器支持
* ##### Doc values 引入
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
料的朋友,可以添加V获取:vip204888 (备注大数据)**
[外链图片转存中...(img-alrCIweU-1713341051300)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 214
214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









