








1.概述
转载:今天面试问到一个 Elasticsearch 问题,给我问懵逼了…
真实面试问题

2.思考
面试官在问 Elasticsearch range 过滤时,他内心在想什么?
最基础的:看你了不了解 range 查询?
其次:看你了不了解 range 查询 支持哪些数据类型?
再次:看你了不了解对应数据类型底层存储数据结构或算法?
最后:看你了不了解对应数据结构的 range 查询原理?
最根本的,想看你的底层原理扎不扎实?
我们在被面试官面试的时候,实际上也是我们自己面试“面试官”。
站在面试官的角度考虑问题,多问几个问什么?基本就能揣摩出他内心的想法。
至少,能问这个问题,面试官不是简单的 CRUD 业务面试官,还是看重底层原理的,侧面印证了面试官所在的团队的技术有一定技术含量。
3.问题拆解
Elasticsearch range 过滤 问题拆解
3.1 range 查询 介绍
脑海里想一下:自己用过的 range 查询。
查询给定时间段的数据(date);
查询给定区间范围的数值类型数据(integer,long等);
查询给定区间范围的字符串类型数据(text/keyword)。
因为是复盘总结讲解,我会列个Demo解读一下:
数据准备
DELETE my_index_0002
PUT my_index_0002
{
"mappings": {
"properties": {
"post_date": {
"type": "date"
},
"user": {
"type": "keyword"
},
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
PUT my_index_0002/_bulk
{"index":{"_id":1}}
{"post_date":"2019-08-05T15:03:02", "user":"lucy", "name":"lucy", "age":18}
{"index":{"_id":2}}
{"post_date":"2017-03-02T01:08:35", "user":"haimeimei", "name":"hanmeimei", "age":25}
{"index":{"_id":3}}
{"post_date":"2020-08-05T15:03:02", "user":"hank", "name":"hank", "age":7}
时间范围查询
POST my_index_0002/_search
{
"profile": "true",
"query": {
"range": {
"post_date": {
"gte": "2017-01-01T00:00:00",
"lte": "2019-12-31T23:59:59"
}
}
}
}
查询结果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "my_index_0002",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"post_date" : "2019-08-05T15:03:02",
"user" : "lucy",
"name" : "lucy",
"age" : 18
}
},
{
"_index" : "my_index_0002",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"post_date" : "2017-03-02T01:08:35",
"user" : "haimeimei",
"name" : "hanmeimei",
"age" : 25
}
}
]
},
"profile" : {
"shards" : [
{
"id" : "[ZiR6PjzPSX6NI99Awisr2g][my_index_0002][0]",
"searches" : [
{
"query" : [
{
"type" : "IndexOrDocValuesQuery",
"description" : "post_date:[1483228800000 TO 1577836799999]",
"time_in_nanos" : 107428,
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 0,
"shallow_advance_count" : 0,
"set_min_competitive_score" : 0,
"next_doc" : 2674,
"match" : 0,
"next_doc_count" : 2,
"score_count" : 2,
"compute_max_score_count" : 0,
"compute_max_score" : 0,
"advance" : 1912,
"advance_count" : 1,
"score" : 1069,
"build_scorer_count" : 2,
"create_weight" : 9375,
"shallow_advance" : 0,
"create_weight_count" : 1,
"build_scorer" : 92390
}
}
],
"rewrite_time" : 2216,
"collector" : [
{
"name" : "SimpleTopScoreDocCollector",
"reason" : "search_top_hits",
"time_in_nanos" : 11713
}
]
}
],
"aggregations" : [ ]
}
]
}
}
其他查询
POST my_index_0002/_search
{ "profile": "true",
"query": {
"range": {
"user": {
"gte": "aaaa",
"lte": "zzzz"
}
}
}
}
POST my_index_0002/_search
{
"profile": "true",
"query": {
"range": {
"age": {
"gte": 1,
"lte": 20
}
}
}
}
POST my_index_0002/_search
{
"profile": "true",
"query": {
"range": {
"name": {
"gte": "aaaa",
"lte": "zzzz"
}
}
}
}
实战中用过 Elasticsearch 的,都会用过上面的 range 查询。
但,面试官想听到的不是这些初级内容。
3.2 range 查询支持的数据类型
如上举例已经列举了。
数值类型 举例:integer、long 等
日期类型 举例:date 等
字符串类型 举例:keyword、 text 等
3.3 range 查询对应数据类型底层存储数据结构
以最典型的两种类型拆解。
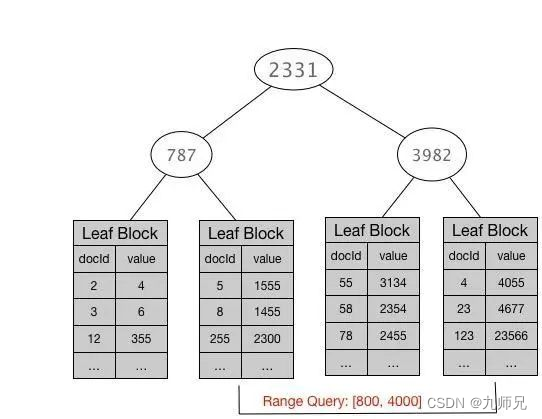
3.3.1 数值类型对应数据结构—— Block K-d Tree
Wood 大叔的相关文章有详细解读:
Elasticsearch 从5.0开始引入Block K-d Tree这种新数值类型索引数据结构,不再采用倒排索引,该结构更适合范围查找。
Block K-d Tree 基本思想:
将一个N维的数值空间,不断选定包含值最多的维度做2分切割,
反复迭代,直到切分出来的空间单元(cell)包含的值数量小于某个数值。
对于单维度的数据,实际上就是简单的对所有值做一个排序,然后
反复从中间做切分,生成一个类似于 B-tree 这样的结构。
和传统的 B-tree 不同的是,他的叶子结点存储的不是单值,而是
一组值的集合,也就是是所谓的一个 Block 。每个 Block 内部
包含的值数量控制在512- 1024个,保证值的数量在block之间尽量
均匀分布。
https://elasticsearch.cn/article/446
其数据结构如下图所示(大致):
3.3.2 字符串类型 text 对应数据结构——LSM 树
Elasticsearch,HBase, Cassandra, RockDB 等都是基于 LSM Tree 来构建索引。
LSM tree 是一种分层、有序、面向磁盘的数据结构,其核心思想是其充分的利用了磁盘批量的顺序写要远比随机写性能高出很多的特点。
LSM tree的核心特点:
-
第一:将索引分为内存和磁盘两部分,并在内存达到阈值时启动树合并(Merge Trees);
-
第二:用批量写入代替随机写入,并且用预写日志 WAL 技术(Elasticsearch 中为 translog 事务日志)保证内存数据,在系统崩溃后可以被恢复;
-
第三:数据采取类似日志追加写的方式写入(Log Structured)磁盘,以顺序写的方式提高写入效率。
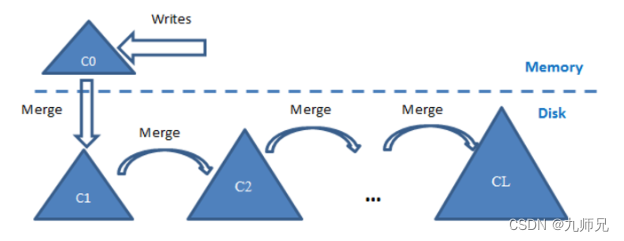
你来到了知识融合点:【算法】LSM-tree 基本原理及应
3.4 range 原理
针对 3.1 demo 中的几种 range 查询,加 profile: true 能看到底层逻辑:
整形 age 以及 日期类型 post_date 的 range 查询 后台使用的 Lucene 的 IndexOrDocValuesQuery 。
post_date date 类型实际会转换成时间戳:
"description" : "post_date:[1483228800000 TO 1577836799999]",
Elasticsearch 5.4 版本新增的 indexOrDocValuesQuery 将 Range 查询过程中的顺序访问任务扔给 Block k-d Tree 索引,将随机访任务交给 doc values 。
字符串类型 user 及 name 的 range 查询 后台使用的是 Lucene 的 MultiTermQueryConstantScoreWrapper。
MultiTermQueryConstantScoreWrapper 本质是:多个 term query 的组合。
3.4.1 数值类型的 range 原理
Lucene 将单维度数据反复从中间做切分后, B-tree的非叶子结点部分放在内存里,而叶子结点紧紧相邻存放在磁盘上。
当做 range 查询的时候,内存里的 B-tree 可以帮助快速定位到满足查询条件的叶子结点块在磁盘上的位置,之后对叶子结点块的读取几乎都是顺序的。
上面这句话其实就是面试官最想听到的。
这个就和 B+ 树(Mysql 索引数据结构)很类似了,B+树的索引和数据分离的机制使得其适合做范围查询。
如果要基于 B+ 树做 Range 查询,举例查询(a,b)之间的所有元素, 实际操作如下:
-
步骤1:通过二分查找找到 a 元素;
-
步骤2:依次向后遍历叶子节点对应的链表元素,直到数值 > b 停止。
这样就能得到(a, b) 之间的所有元素值。
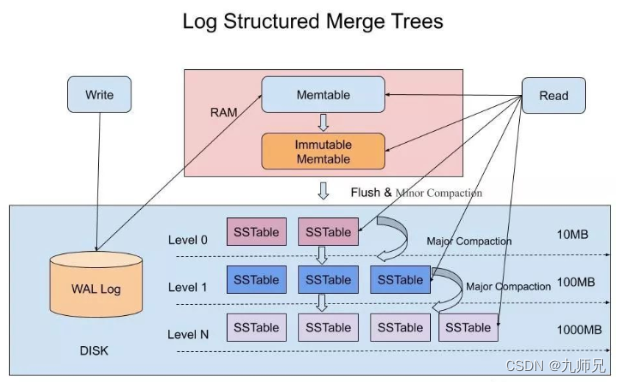
3.4.2 字符串类型text 的range原理
针对 LSM-Tree ,核心的数据结构就是 SSTable ,全称是 Sorted String Table ,SSTable 的概念其实也是来自于 Google 的 Bigtable 论文。
SSTable 是一种拥有持久化,有序且不可变的的键值存储结构,它的 key 和 value 都是任意的字节数组,并且了提供了按指定key查找和指定范围的key区间迭代遍历的功能。

SSTable 内部包含了一系列可配置大小的 Block 块,典型的大小是 64 KB,关于这些Block块的索引存储在 SSTable 的尾部,用于帮助快速查找特定的 Block。
查询的原理:当一个SSTable被打开的时候,索引会被加载到内存,然后根据key在内存索引里面进行一个二分查找,查到该 key 对应的磁盘的 offset 之后,然后去磁盘把响应的块数据读取出来。
range 的原理:在查询基础上,基于 SStable 文件(已有序)向后遍历找到直到找到大于右区间值停止遍历。
当然如果内存足够大的话,可以直接把 SSTable 直接通过 MMap 的技术映射到内存中,从而提供更快的查找。
4.小结
小问题,大道理。“底层的技术永远不过时“。
涉及到算法的底层逻辑,任何一个知识点的背后都是行业的顶级期刊的顶级论文,要了解更多细节需要查看更多资料。
本文未深究算法细节,难免会有纰漏,欢迎大家指正交流反馈。















 1159
1159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









