







-
目标:掌握一站制造的项目的业务流程和数据来源
-
路径
- step1:业务流程
- step2:数据来源
-
实施
- 业务流程

- step1:加油站服务商联系呼叫中心,**申请服务**:安装/巡检/维修/改造加油机 * 呼叫中心会记录这个申请信息:来电受理事务事实表 - step2:呼叫中心联系对应服务站点,**分派工单**:联系站点主管,站点主管分配服务人员 * 工单信息记录在:服务单信息表、工单信息表 - step3:服务人员**确认工单**和加油站点信息 * 具体工单信息表:安装单、维修单 - step4:服务人员在指定日期到达加油站,进行**设备检修** - step5:如果为安装或者巡检服务,安装或者巡检成功,则服务完成 - step6:如果为维修或者改造服务,需要向服务站点**申请物料**,物料到达,实施结束,则**服务完成** - step7:服务完成,与加油站站点服务商确认服务结束,完成**订单核验** - step8:工程师**报销**过程中产生的费用 * 所有报销费用记录:差旅费用信息表,费用明细表 - step9:呼叫中心会定期对该工单中的工程师的服务做**回访** * 回访信息表- 数据来源

- ERP系统:企业资源管理系统,存储整个公司所有资源的信息* 所有的工程师、物品、设备产品供应链、生产、销售、财务的信息都在ERP系统中 - **CISS系统**:客户服务管理系统,存储所有用户、运营数据 * 工单信息、用户信息 - **呼叫中心系统**:负责实现所有客户的需求申请、调度、回访等 * 呼叫信息、分配信息、回访信息 - **核心数据表** 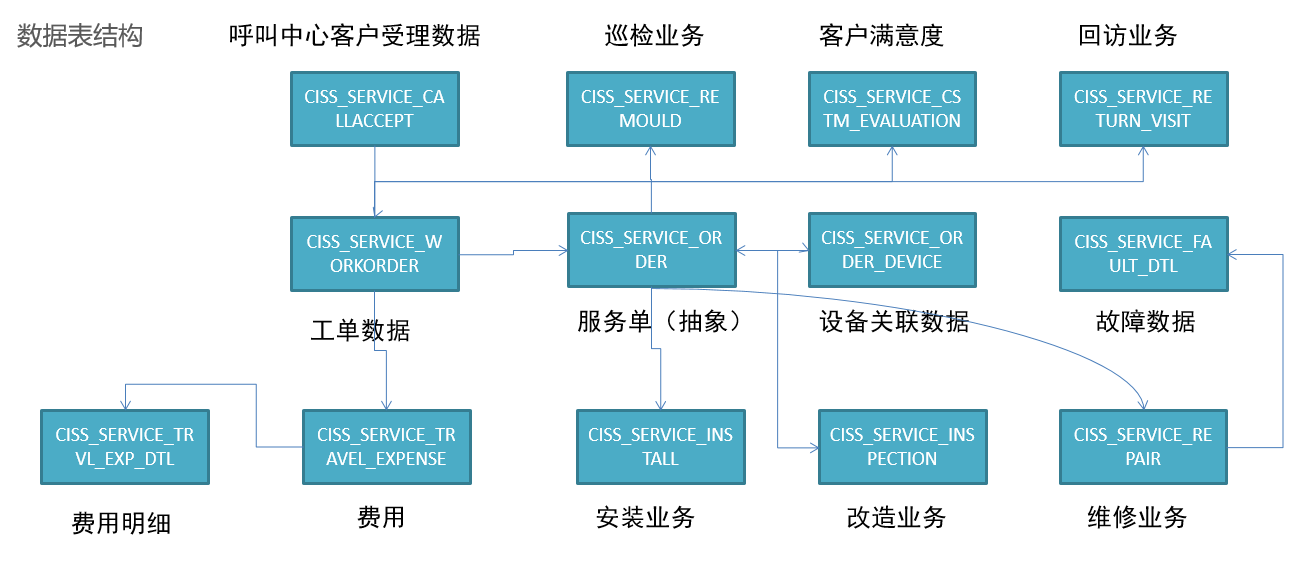 * 运营分析 + 工单分析、安装分析、维修分析、巡检分析、改造分析、来电受理分析 * 提高服务质量 + 回访分析 * 运营成本核算 + 收入、支持分析 -
小结
- 掌握一站制造的项目的业务流程和数据来源
14:项目总结:主题划分
-
目标:掌握一站制造的项目的主题划分
-
实施
- 服务域
- 安装主题:安装方式、支付费用、安装类型
- 工单主题:派工方式、工单总数、派工类型、完工总数、
- 维修主题:支付费用、零部件费用、故障类型
- 派单主题:派单数、派单平均值、派单响应时间
- 费用主题:差旅费、安装费、报销人员统计
- 回访主题:回访人员数、回访工单状态
- 油站主题:油站总数量、油站新增数量
- 客户域
- 客户主题:安装数量、维修数量、巡检数量、回访数量
- 仓储域
- 保内良品核销主题:核销数量、配件金额
- 保内不良品核销主题:核销配件数、核销配件金额
- 送修主题:送修申请、送修物料数量、送修类型
- 调拨主题:调拨状态、调拨数量、调拨设备类型
- 消耗品核销:核销总数、核销设备类型
- 服务商域
- 工单主题:派工方式、工单总数、工单类型、客户类型
- 服务商油站主题:油站数量、油站新增数量
- 运营域
- 运营主题:服务人员工时、维修站分析、平均工单、网点分布
- 市场域
- 市场主题:工单统计、完工明细、订单统计
- 服务域
-
小结
- 掌握一站制造的项目的主题划分
15:项目总结:技术架构
-
目标:掌握一站制造的项目的技术架构
-
实施
-
数据生成:业务数据库系统
- Oracle:工单数据、物料数据、服务商数据、报销数据等
-
数据采集
- Sqoop:离线数据库采集
- Sqoop怎么采集Oracle数据
- Sqoop:离线数据库采集
-
数据存储
- Hive【HDFS】:离线数据仓库【表】
-
数据计算
- SparkSQL:类HiveSQL开发方式:对数据仓库中的结构化数据做处理分析
- Python | Java :SparkSQLDSL开发:使用spark-submit来提交运行
- SparkSQL SQL + ThriftServer:提交SQL开发
- SparkSQL:类HiveSQL开发方式:对数据仓库中的结构化数据做处理分析
-
数据应用
- MySQL:结果存储
- FineBI / Tableau:可视化工具
-
监控工具
- Prometheus:服务器性能指标监控工具
- Grafana:监控可视化工具
-
调度工具
- AirFlow:任务流调度工具
-
技术架构

-
-
小结
- 掌握一站制造的项目的技术架构
16:项目总结:数仓设计
-
目标:掌握一站制造的项目的分层设计与建模设计
-
路径
- step1:分层设计
- step2:建模设计
-
实施
- 分层设计

- **ODS**:原始数据层:最接近于原始数据的层次,直接采集写入层次:**原始事务事实表** * 数据内容:存储所有原始业务数据,基本与Oracle数据库中的业务数据保持一致 * 数据来源:使用Sqoop从Oracle中同步采集 * 存储设计:Hive分区表,avro文件格式存储,保留3个月 - **DWD**:明细数据层:对ODS层的数据根据业务需求实现ETL以后的结果:ETL以后事务事实表 * 数据内容:存储所有业务数据的明细数据 * 数据来源:对ODS层的数据进行ETL扁平化处理得到 * 存储设计:Hive分区表,orc文件格式存储,保留所有数据 - **DWB**:基础数据层:类似于以前讲解的DWM,轻度聚合 * 关联:将主题事实的表进行关联,所有与这个主题相关的字段合并到一张表 * 聚合:基于主题的事务事实构建基础指标 * **主题事务事实表** * 数据内容:存储所有事实与维度的基本关联、基本事实指标等数据 * 数据来源:对DWD层的数据进行清洗过滤、轻度聚合以后的数据 * 存储设计:Hive分区表,orc文件格式存储,保留所有数据 - **ST**:数据应用层:类似于以前讲解的APP,存储每个主题基于维度分析聚合的结果:**周期快照事实表** * 供数据分析的报表 * 数据内容:存储所有报表分析的事实数据 * 数据来源:基于DWB和DWS层,通过对不同维度的统计聚合得到所有报表事实的指标 - **DM**:数据集市:按照不同部门的数据需求,将暂时没有实际主题需求的数据存储 * 做部门数据归档,方便以后新的业务需求的迭代开发 * 数据内容:存储不同部门所需要的不同主题的数据 * 数据来源:对DW层的数据进行聚合统计按照不同部门划分 - **DWS**:维度数据层:类似于以前讲解的DIM:存储**维度数据表** * 数据内容:存储所有业务的维度数据:日期、地区、油站、呼叫中心、仓库等维度表 * 数据来源:对DWD的明细数据中抽取维度数据 * 存储设计:Hive普通表,orc文件 + Snappy压缩 * 特点:数量小、很少发生变化、全量采集 - 数据仓库设计方案 * 从上到下:在线教育:先明确需求和主题,然后基于主题的需求采集数据,处理数据 + 场景:数据应用比较少,需求比较简单 * **从下到上**:一站制造:将整个公司所有数据统一化在数据仓库中存储准备,根据以后的需求,动态直接获取数据 + 场景:数据应用比较多,业务比较复杂-
建模设计
-
建模方法:维度建模
-
维度设计:星型模型
-
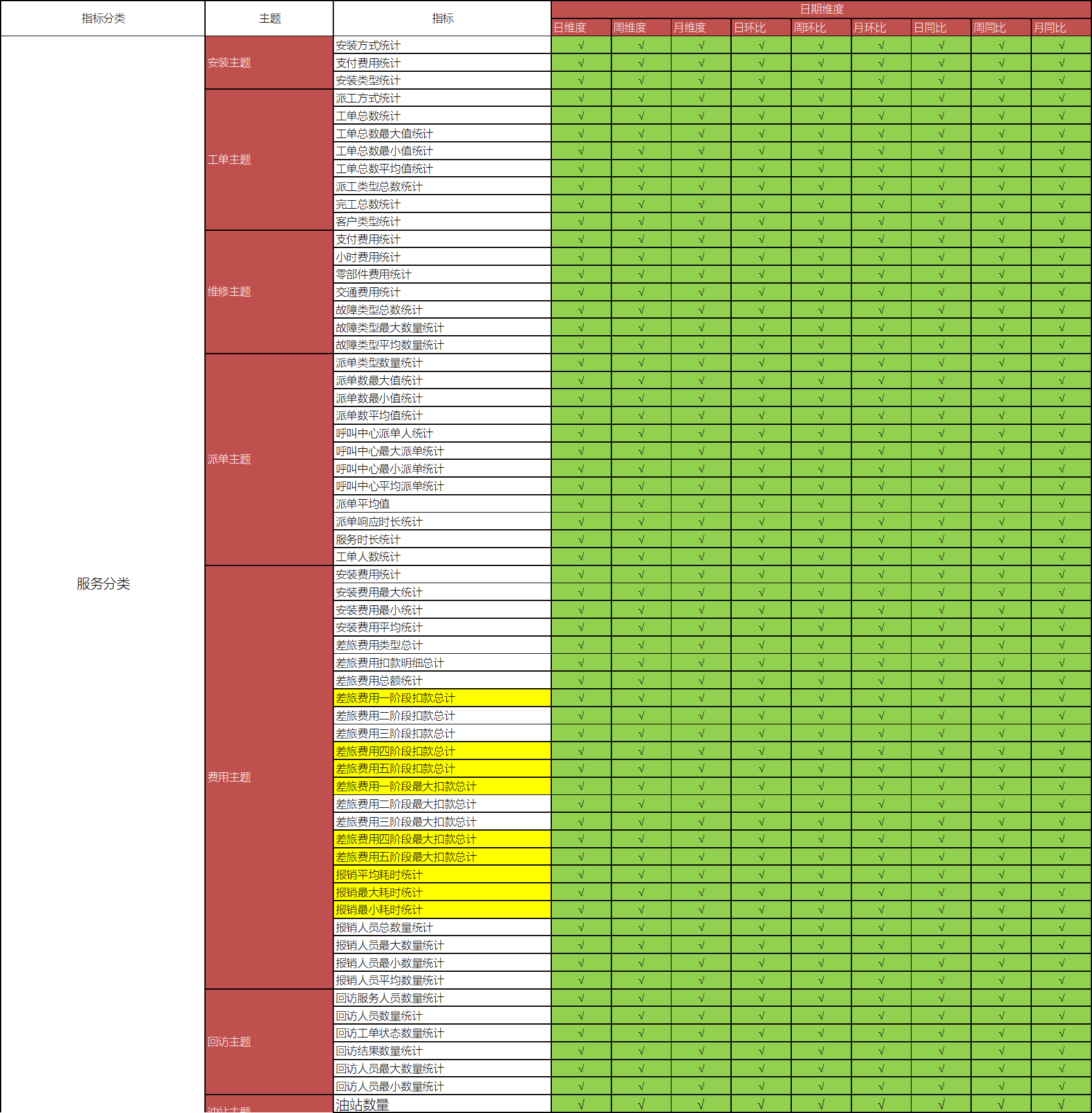
常用维度
- 日期时间维度
- 年维度、季度维度、月维度、周维度、日维度
- 日环比、周环比、月环比、日同比、周同比、月同比
- 环比:同一个周期内的比较
- 同比:上个个周期的比较
- 行政地区维度
- 地区级别:国家维度、省份维度、城市维度、县区维度、乡镇维度
- 服务网点维度
- 网点名称、网点编号、省份、城市、县区、所属机构
- 油站维度
- 油站类型、油站名称、油站编号、客户编号、客户名称、省份、城市、县区、油站状态、所属公司
- 组织机构维度
- 人员编号、人员名称、岗位编号、岗位名称、部门编号、部门名称
- 服务类型维度
- 类型编号、类型名称
- 设备维度
- 设备类型、设备编号、设备名称、油枪数量、泵类型、软件类型
- 故障类型维度
- 一级故障编号、一级故障名称、二级故障编号、二级故障名称
- 物流公司维度
- 物流公司编号、物流公司名称
- 日期时间维度
-
主题维度矩阵
-
- 小结
- 掌握一站制造的项目的分层设计与建模设计
17:项目总结:优化及新特性
-
目标:掌握一站制造项目中的优化方案
-
实施
-
优化:参考FTP中:《就业面试》中的优化文档
-
资源优化:开启属性分配更多的资源,内存合理分配
-
开发优化:谓词下推:尽量将不需要的数据提前过滤掉【join】
- 尽量选用有Map端聚合的算子:先分区内聚合,再分区间聚合
- 尽量将不需要join的数据过滤,或者实现Broadcast Join
-
结构优化:文件存储类型、分区结构化
- 分区表:静态分区裁剪
select count(*) from table1 where daystr = '2021-10-15'; --走分区裁剪过滤查询--spark2中先join后过滤 select * from table1 join table2 on table1.id = table2.id and table1.daystr = '2021-10-15' and table2.daystr='2021-10-15';
-
-
新特性:Spark3.0
-
动态分区裁剪(Dynamic Partition Pruning)
- 默认的分区裁剪只有在单表查询过滤时才有效
- 开启动态分区裁剪:自动在Join时对两边表的数据根据条件进行查询过滤,将过滤后的结果再进行join
-
-

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
转存中…(img-LF3fU9yw-1714638078005)]
[外链图片转存中…(img-dqKkTgfJ-1714638078005)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









