







自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数HarmonyOS鸿蒙开发工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年HarmonyOS鸿蒙开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

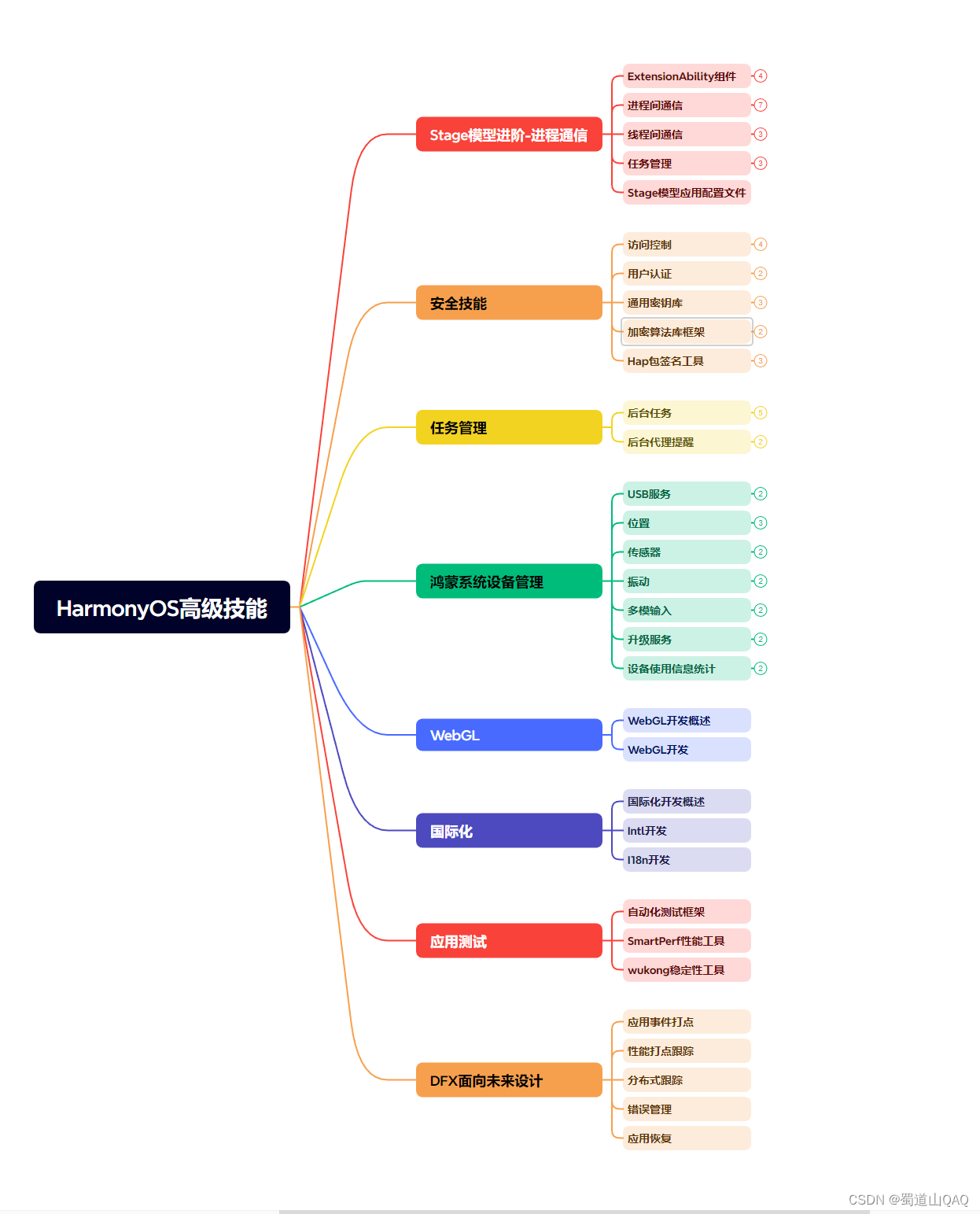


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上HarmonyOS鸿蒙开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注鸿蒙获取)

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
msg.markInUse();
return msg;
}
} else {
// No more messages.
nextPollTimeoutMillis = -1;
}
}
}
}
**奇怪,为什么取消息也是用的死循环呢?**
其实死循环就是为了保证一定要返回一条消息,如果没有可用消息,那么就阻塞在这里,一直到有新消息的到来。
其中,`nativePollOnce`方法就是阻塞方法,`nextPollTimeoutMillis`参数就是阻塞的时间。
那什么时候会阻塞呢?两种情况:
* 1、有消息,但是当前时间小于消息执行时间,也就是代码中的这一句:
if (now < msg.when) {
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
}
这时候阻塞时间就是消息时间减去当前时间,然后进入下一次循环,阻塞。
* 2、没有消息的时候,也就是上述代码的最后一句:
if (msg != null) {}
else {
// No more messages.
nextPollTimeoutMillis = -1;
}
`-1`就代表一直阻塞。
#### MessageQueue没有消息时候会怎样?阻塞之后怎么唤醒呢?说说pipe/epoll机制?
接着上文的逻辑,当消息不可用或者没有消息的时候就会阻塞在next方法,而阻塞的办法是通过pipe/epoll机制
`epoll机制`是一种IO多路复用的机制,具体逻辑就是一个进程可以监视多个描述符,当某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作,这个读写操作是阻塞的。在Android中,会创建一个`Linux管道(Pipe)`来处理阻塞和唤醒。
* 当消息队列为空,管道的读端等待管道中有新内容可读,就会通过`epoll`机制进入阻塞状态。
* 当有消息要处理,就会通过管道的写端写入内容,唤醒主线程。
#### 同步屏障和异步消息是怎么实现的?
其实在`Handler`机制中,有三种消息类型:
* `同步消息`。也就是普通的消息。
* `异步消息`。通过setAsynchronous(true)设置的消息。
* `同步屏障消息`。通过postSyncBarrier方法添加的消息,特点是target为空,也就是没有对应的handler。
**这三者之间的关系如何呢?**
* 正常情况下,同步消息和异步消息都是正常被处理,也就是根据时间when来取消息,处理消息。
* 当遇到同步屏障消息的时候,就开始从消息队列里面去找异步消息,找到了再根据时间决定阻塞还是返回消息。
也就是说同步屏障消息不会被返回,他只是一个标志,一个工具,遇到它就代表要去先行处理异步消息了。
所以同步屏障和异步消息的存在的意义就在于有些消息需要`“加急处理”`。
#### 同步屏障和异步消息有具体的使用场景吗?
使用场景就很多了,比如绘制方法`scheduleTraversals`。
void scheduleTraversals() {
if (!mTraversalScheduled) {
mTraversalScheduled = true;
// 同步屏障,阻塞所有的同步消息
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
// 通过 Choreographer 发送绘制任务
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
}
}
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_CALLBACK, action);
msg.arg1 = callbackType;
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, dueTime);
在该方法中加入了同步屏障,后续加入一个异步消息`MSG_DO_SCHEDULE_CALLBACK`,最后会执行到`FrameDisplayEventReceiver`,用于申请VSYNC信号。
#### Message消息被分发之后会怎么处理?消息怎么复用的?
再看看loop方法,在消息被分发之后,也就是执行了`dispatchMessage`方法之后,还偷偷做了一个操作——`recycleUnchecked`。
public static void loop() {
for (;😉 {
Message msg = queue.next(); // might block
try {
msg.target.dispatchMessage(msg);
}
msg.recycleUnchecked();
}
}
//Message.java
private static Message sPool;
private static final int MAX_POOL_SIZE = 50;
void recycleUnchecked() {
flags = FLAG_IN_USE;
what = 0;
arg1 = 0;
arg2 = 0;
obj = null;
replyTo = null;
sendingUid = UID_NONE;
workSourceUid = UID_NONE;
when = 0;
target = null;
callback = null;
data = null;
synchronized (sPoolSync) {
if (sPoolSize < MAX_POOL_SIZE) {
next = sPool;
sPool = this;
sPoolSize++;
}
}
}
在`recycleUnchecked`方法中,释放了所有资源,然后将当前的空消息插入到sPool表头。
这里的`sPool`就是一个消息对象池,它也是一个链表结构的消息,最大长度为50。
那么Message又是怎么复用的呢?在Message的实例化方法`obtain`中:
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
sPool = m.next;
m.next = null;
m.flags = 0; // clear in-use flag
sPoolSize–;
return m;
}
}
return new Message();
}
直接复用消息池`sPool`中的第一条消息,然后sPool指向下一个节点,消息池数量减一。
#### Looper是干嘛呢?怎么获取当前线程的Looper?为什么不直接用Map存储线程和对象呢?
在Handler发送消息之后,消息就被存储到`MessageQueue`中,而`Looper`就是一个管理消息队列的角色。Looper会从`MessageQueue`中不断的查找消息,也就是loop方法,并将消息交回给Handler进行处理。
而Looper的获取就是通过`ThreadLocal`机制:
static final ThreadLocal sThreadLocal = new ThreadLocal();
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
public static @Nullable Looper myLooper() {
return sThreadLocal.get();
}
通过`prepare`方法创建Looper并且加入到sThreadLocal中,通过`myLooper`方法从sThreadLocal中获取Looper。
#### ThreadLocal运行机制?这种机制设计的好处?
下面就具体说说`ThreadLocal`运行机制。
//ThreadLocal.java
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings(“unchecked”)
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
从`ThreadLocal`类中的get和set方法可以大致看出来,有一个`ThreadLocalMap`变量,这个变量存储着键值对形式的数据。
* `key`为this,也就是当前ThreadLocal变量。
* `value`为T,也就是要存储的值。
然后继续看看`ThreadLocalMap`哪来的,也就是getMap方法:
//ThreadLocal.java
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
//Thread.java
ThreadLocal.ThreadLocalMap threadLocals = null;
原来这个`ThreadLocalMap`变量是存储在线程类Thread中的。
所以`ThreadLocal`的基本机制就搞清楚了:
在每个线程中都有一个threadLocals变量,这个变量存储着ThreadLocal和对应的需要保存的对象。
这样带来的好处就是,在不同的线程,访问同一个ThreadLocal对象,但是能获取到的值却不一样。
挺神奇的是不是,其实就是其内部获取到的Map不同,Map和Thread绑定,所以虽然访问的是同一个`ThreadLocal`对象,但是访问的Map却不是同一个,所以取得值也不一样。
这样做有什么好处呢?为什么不直接用Map存储线程和对象呢?
打个比方:
* `ThreadLocal`就是老师。
* `Thread`就是同学。
* `Looper`(需要的值)就是铅笔。
现在老师买了一批铅笔,然后想把这些铅笔发给同学们,怎么发呢?两种办法:
>
> 1、老师把每个铅笔上写好每个同学的名字,放到一个大盒子里面去(map),用的时候就让同学们自己来找。
>
>
>
这种做法就是Map里面存储的是`同学和铅笔`,然后用的时候通过同学来从这个Map里找铅笔。
这种做法就有点像使用一个Map,存储所有的线程和对象,不好的地方就在于会很混乱,每个线程之间有了联系,也容易造成内存泄漏。
>
> 2、老师把每个铅笔直接发给每个同学,放到同学的口袋里(map),用的时候每个同学从口袋里面拿出铅笔就可以了。
>
>
>
这种做法就是Map里面存储的是`老师和铅笔`,然后用的时候老师说一声,同学只需要从口袋里拿出来就行了。
很明显这种做法更科学,这也就是`ThreadLocal`的做法,因为铅笔本身就是同学自己在用,所以一开始就把铅笔交给同学自己保管是最好的,每个同学之间进行隔离。
#### 还有哪些地方运用到了ThreadLocal机制?
比如:Choreographer。
public final class Choreographer {
// Thread local storage for the choreographer.
private static final ThreadLocal<Choreographer> sThreadInstance =
new ThreadLocal<Choreographer>() {
@Override
protected Choreographer initialValue() {
Looper looper = Looper.myLooper();
if (looper == null) {
throw new IllegalStateException("The current thread must have a looper!");
}
Choreographer choreographer = new Choreographer(looper, VSYNC_SOURCE_APP);
if (looper == Looper.getMainLooper()) {
mMainInstance = choreographer;
}
return choreographer;
}
};
private static volatile Choreographer mMainInstance;
`Choreographer`主要是主线程用的,用于配合 `VSYNC`中断信号。
所以这里使用`ThreadLocal`更多的意义在于完成线程单例的功能。
#### 可以多次创建Looper吗?
Looper的创建是通过`Looper.prepare`方法实现的,而在prepare方法中就判断了,当前线程是否存在Looper对象,如果有,就会直接抛出异常:
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException(“Only one Looper may be created per thread”);
}
sThreadLocal.set(new Looper(quitAllowed));
}
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
所以同一个线程,只能创建一个`Looper`,多次创建会报错。
#### Looper中的quitAllowed字段是啥?有什么用?
按照字面意思就是是否允许退出,我们看看他都在哪些地方用到了:
void quit(boolean safe) {
if (!mQuitAllowed) {
throw new IllegalStateException(“Main thread not allowed to quit.”);
}
synchronized (this) {
if (mQuitting) {
return;
}
mQuitting = true;
if (safe) {
removeAllFutureMessagesLocked();
} else {
removeAllMessagesLocked();
}
}
}
哦,就是这个`quit`方法用到了,如果这个字段为`false`,代表不允许退出,就会报错。
但是这个`quit`方法又是干嘛的呢?从来没用过呢。还有这个`safe`又是啥呢?
其实看名字就差不多能了解了,quit方法就是退出消息队列,终止消息循环。
* 首先设置了`mQuitting`字段为true。
* 然后判断是否安全退出,如果安全退出,就执行`removeAllFutureMessagesLocked`方法,它内部的逻辑是清空所有的延迟消息,之前没处理的非延迟消息还是需要取处理,然后设置非延迟消息的下一个节点为空(p.next=null)。
* 如果不是安全退出,就执行`removeAllMessagesLocked`方法,直接清空所有的消息,然后设置消息队列指向空(mMessages = null)
然后看看当调用quit方法之后,消息的发送和处理:
//消息发送
boolean enqueueMessage(Message msg, long when) {
synchronized (this) {
if (mQuitting) {
IllegalStateException e = new IllegalStateException(
msg.target + " sending message to a Handler on a dead thread");
Log.w(TAG, e.getMessage(), e);
msg.recycle();
return false;
}
}
当调用了quit方法之后,`mQuitting`为true,消息就发不出去了,会报错。
再看看消息的处理,loop和next方法:
Message next() {
for (;😉 {
synchronized (this) {
if (mQuitting) {
dispose();
return null;
}
}
}
}
public static void loop() {
for (;;) {
Message msg = queue.next();
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
}
}
很明显,当`mQuitting`为true的时候,next方法返回null,那么loop方法中就会退出死循环。
那么这个`quit`方法一般是什么时候使用呢?
* 主线程中,一般情况下肯定不能退出,因为退出后主线程就停止了。所以是当APP需要退出的时候,就会调用quit方法,涉及到的消息是EXIT\_APPLICATION,大家可以搜索下。
* 子线程中,如果消息都处理完了,就需要调用quit方法停止消息循环。
#### Looper.loop方法是死循环,为什么不会卡死(ANR)?
关于这个问题,强烈建议看看Gityuan的回答:[https://www.zhihu.com/question/34652589]( )
我大致总结下:
* 主线程本身就是需要一只运行的,因为要处理各个View,界面变化。所以需要这个死循环来保证主线程一直执行下去,不会被退出。
* 真正会卡死的操作是在某个消息处理的时候操作时间过长,导致掉帧、ANR,而不是loop方法本身。
* 在主线程以外,会有其他的线程来处理接受其他进程的事件,比如`Binder线程(ApplicationThread)`,会接受AMS发送来的事件
* 在收到跨进程消息后,会交给主线程的`Hanlder`再进行消息分发。所以Activity的生命周期都是依靠主线程的`Looper.loop`,当收到不同Message时则采用相应措施,比如收到`msg=H.LAUNCH_ACTIVITY`,则调用`ActivityThread.handleLaunchActivity()`方法,最终执行到onCreate方法。
* 当没有消息的时候,会阻塞在loop的`queue.next()`中的`nativePollOnce()`方法里,此时主线程会释放CPU资源进入休眠状态,直到下个消息到达或者有事务发生。所以死循环也不会特别消耗CPU资源。
#### Message是怎么找到它所属的Handler然后进行分发的?
在loop方法中,找到要处理的`Message`,然后调用了这么一句代码处理消息:
msg.target.dispatchMessage(msg);
所以是将消息交给了`msg.target`来处理,那么这个target是啥呢?
找找它的来头:
//Handler
private boolean enqueueMessage(MessageQueue queue,Message msg,long uptimeMillis) {
msg.target = this;
return queue.enqueueMessage(msg, uptimeMillis);
}
在使用Hanlder发送消息的时候,会设置`msg.target = this`,所以target就是当初把消息加到消息队列的那个Handler。
#### Handler 的 post(Runnable) 与 sendMessage 有什么区别
Hanlder中主要的发送消息可以分为两种:
* post(Runnable)
* sendMessage
public final boolean post(@NonNull Runnable r) {
return sendMessageDelayed(getPostMessage®, 0);
}
private static Message getPostMessage(Runnable r) {
Message m = Message.obtain();
m.callback = r;
return m;
}
通过post的源码可知,其实`post和sendMessage`的区别就在于:
post方法给Message设置了一个`callback`。
那么这个callback有什么用呢?我们再转到消息处理的方法`dispatchMessage`中看看:
public void dispatchMessage(@NonNull Message msg) {
if (msg.callback != null) {
handleCallback(msg);
} else {
if (mCallback != null) {
if (mCallback.handleMessage(msg)) {
return;
}
}
handleMessage(msg);
}
}
private static void handleCallback(Message message) {
message.callback.run();
}
这段代码可以分为三部分看:
* 如果`msg.callback`不为空,也就是通过post方法发送消息的时候,会把消息交给这个msg.callback进行处理,然后就没有后续了。
* 如果`msg.callback`为空,也就是通过sendMessage发送消息的时候,会判断Handler当前的mCallback是否为空,如果不为空就交给Handler.Callback.handleMessage处理。
* 如果`mCallback.handleMessage`返回true,则无后续了。
* 如果`mCallback.handleMessage`返回false,则调用handler类重写的handleMessage方法。
所以post(Runnable) 与 sendMessage的区别就在于后续消息的处理方式,是交给`msg.callback`还是 `Handler.Callback`或者`Handler.handleMessage`。
#### Handler.Callback.handleMessage 和 Handler.handleMessage 有什么不一样?为什么这么设计?
接着上面的代码说,这两个处理方法的区别在于`Handler.Callback.handleMessage`方法是否返回true:
* 如果为`true`,则不再执行Handler.handleMessage
* 如果为`false`,则两个方法都要执行。
那么什么时候有`Callback`,什么时候没有呢?这涉及到两种Hanlder的 创建方式:
val handler1= object : Handler(){
override fun handleMessage(msg: Message) {
super.handleMessage(msg)
}
}
val handler2 = Handler(object : Handler.Callback {
override fun handleMessage(msg: Message): Boolean {
return true
}
})
常用的方法就是第1种,派生一个Handler的子类并重写handleMessage方法。而第2种就是系统给我们提供了一种不需要派生子类的使用方法,只需要传入一个Callback即可。
#### Handler、Looper、MessageQueue、线程是一一对应关系吗?
* 一个线程只会有一个`Looper`对象,所以线程和Looper是一一对应的。
* `MessageQueue`对象是在new Looper的时候创建的,所以Looper和MessageQueue是一一对应的。
* `Handler`的作用只是将消息加到MessageQueue中,并后续取出消息后,根据消息的target字段分发给当初的那个handler,所以Handler对于Looper是可以多对一的,也就是多个Hanlder对象都可以用同一个线程、同一个Looper、同一个MessageQueue。
总结:Looper、MessageQueue、线程是一一对应关系,而他们与Handler是可以一对多的。
#### ActivityThread中做了哪些关于Handler的工作?(为什么主线程不需要单独创建Looper)
主要做了两件事:
**1、在main方法中,创建了主线程的`Looper`和`MessageQueue`,并且调用loop方法开启了主线程的消息循环。**
public static void main(String[] args) {
Looper.prepareMainLooper();
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}
**2、创建了一个Handler来进行四大组件的启动停止等事件处理**
final H mH = new H();
class H extends Handler {
public static final int BIND_APPLICATION = 110;
public static final int EXIT_APPLICATION = 111;
public static final int RECEIVER = 113;
public static final int CREATE_SERVICE = 114;
public static final int STOP_SERVICE = 116;
public static final int BIND_SERVICE = 121;
#### IdleHandler是啥?有什么使用场景?
之前说过,当`MessageQueue`没有消息的时候,就会阻塞在next方法中,其实在阻塞之前,`MessageQueue`还会做一件事,就是检查是否存在`IdleHandler`,如果有,就会去执行它的`queueIdle`方法。
private IdleHandler[] mPendingIdleHandlers;
Message next() {
int pendingIdleHandlerCount = -1;
for (;;) {
synchronized (this) {
//当消息执行完毕,就设置pendingIdleHandlerCount
if (pendingIdleHandlerCount < 0
&& (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
//初始化mPendingIdleHandlers
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
//mIdleHandlers转为数组
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
}
// 遍历数组,处理每个IdleHandler
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; // release the reference to the handler
boolean keep = false;
try {
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
//如果queueIdle方法返回false,则处理完就删除这个IdleHandler
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
// Reset the idle handler count to 0 so we do not run them again.
pendingIdleHandlerCount = 0;
}
}
当没有消息处理的时候,就会去处理这个`mIdleHandlers`集合里面的每个`IdleHandler`对象,并调用其`queueIdle`方法。最后根据`queueIdle`返回值判断是否用完删除当前的`IdleHandler`。
然后看看`IdleHandler`是怎么加进去的:
Looper.myQueue().addIdleHandler(new IdleHandler() {
@Override
public boolean queueIdle() {
//做事情
return false;
}
});
public void addIdleHandler(@NonNull IdleHandler handler) {
if (handler == null) {
throw new NullPointerException("Can't add a null IdleHandler");
}
synchronized (this) {
mIdleHandlers.add(handler);
}
}
ok,综上所述,`IdleHandler`就是当消息队列里面没有当前要处理的消息了,需要堵塞之前,可以做一些空闲任务的处理。
常见的使用场景有:**启动优化**。
我们一般会把一些事件(比如界面view的绘制、赋值)放到`onCreate`方法或者`onResume`方法中。但是这两个方法其实都是在界面绘制之前调用的,也就是说一定程度上这两个方法的耗时会影响到启动时间。
所以我们可以把一些操作放到`IdleHandler`中,也就是界面绘制完成之后才去调用,这样就能减少启动时间了。
**但是,这里需要注意下可能会有坑。**
如果使用不当,`IdleHandler`会一直不执行,比如在`View的onDraw方法`里面无限制的直接或者间接调用`View的invalidate方法`。
其原因就在于onDraw方法中执行`invalidate`,会添加一个同步屏障消息,在等到异步消息之前,会阻塞在next方法,而等到`FrameDisplayEventReceiver`异步任务之后又会执行onDraw方法,从而无限循环。
#### HandlerThread是啥?有什么使用场景?
直接看源码:
public class HandlerThread extends Thread {
@Override
public void run() {
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
}
哦,原来如此。`HandlerThread`就是一个封装了Looper的Thread类。
就是为了让我们在子线程里面更方便的使用Handler。
、赋值)放到`onCreate`方法或者`onResume`方法中。但是这两个方法其实都是在界面绘制之前调用的,也就是说一定程度上这两个方法的耗时会影响到启动时间。
所以我们可以把一些操作放到`IdleHandler`中,也就是界面绘制完成之后才去调用,这样就能减少启动时间了。
**但是,这里需要注意下可能会有坑。**
如果使用不当,`IdleHandler`会一直不执行,比如在`View的onDraw方法`里面无限制的直接或者间接调用`View的invalidate方法`。
其原因就在于onDraw方法中执行`invalidate`,会添加一个同步屏障消息,在等到异步消息之前,会阻塞在next方法,而等到`FrameDisplayEventReceiver`异步任务之后又会执行onDraw方法,从而无限循环。
#### HandlerThread是啥?有什么使用场景?
直接看源码:
public class HandlerThread extends Thread {
@Override
public void run() {
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
}
哦,原来如此。`HandlerThread`就是一个封装了Looper的Thread类。
就是为了让我们在子线程里面更方便的使用Handler。















 350
350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









