







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
前言
因为我做的项目需要一些疫情数据,因此在这里总结一下数据获取以及将其保存到数据库,对网络爬虫学习者还是有帮助的。
需求分析
我们需要获取的内容是某新闻报告官网的这个国内疫情数据,包含总体数据以及各省市数据以及每天的数据及变化!
目标网站如下:https://news.qq.com/zt2020/page/feiyan.htm#/
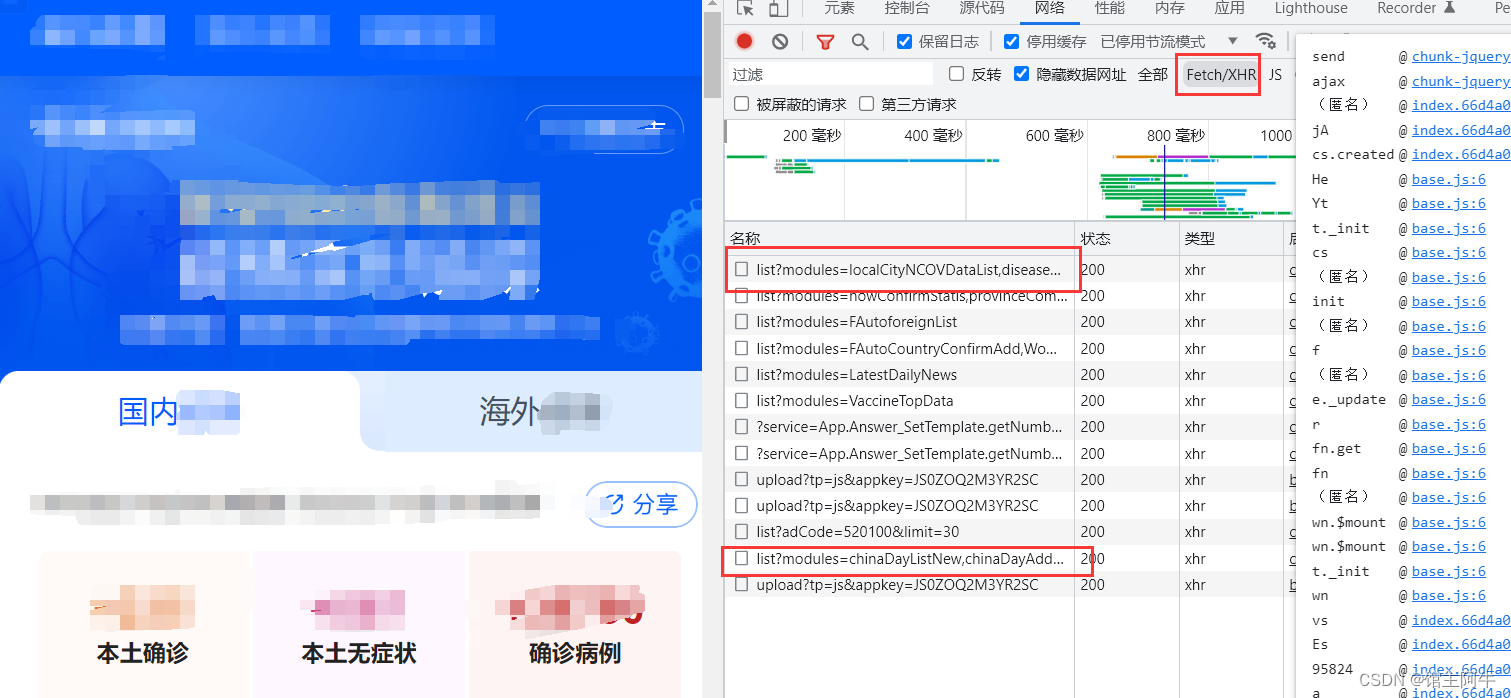
如图:要获取的api有两个,第一个链接是各省市的详情数据,第二个是近30天的历史数据。
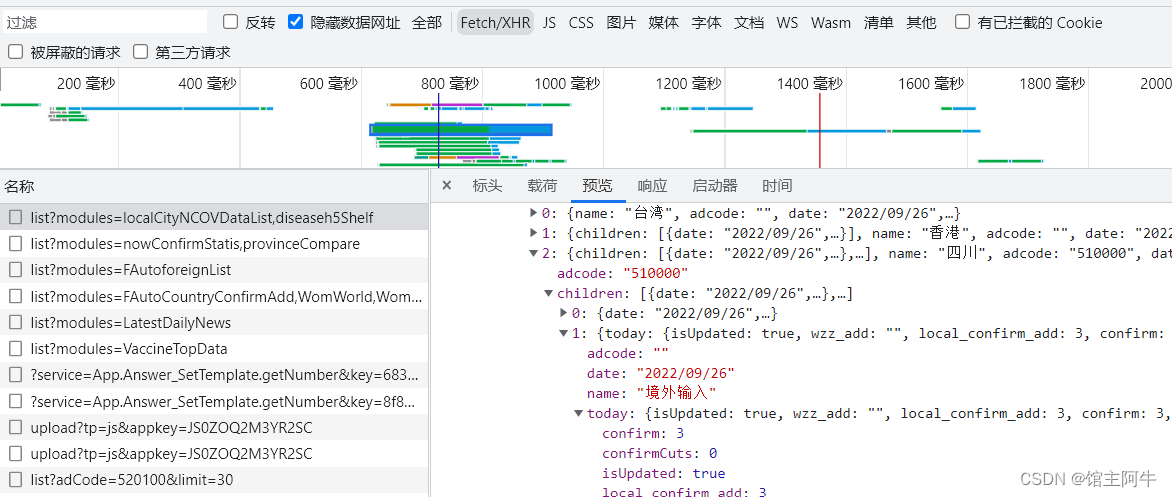
如图,数据是树状的,需要我们看好一层层提取,可借助json格式化工具!
最后将其保存到mysql数据库!
项目技术
爬虫-获取数据
pymysql - 连接数据库
mysql - 保存数据
数据库设计
ER图
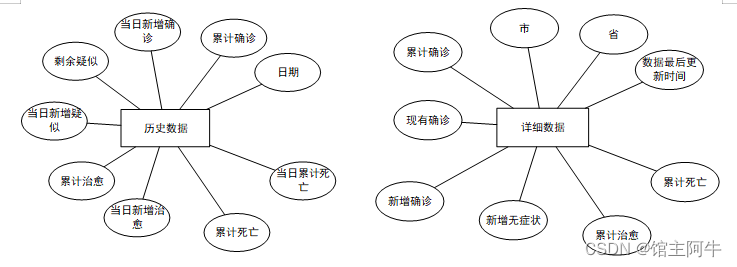
建表sql
详细数据表
CREATE TABLE `details` (
`id` int NOT NULL AUTO\_INCREMENT,
`update\_time` datetime DEFAULT NULL COMMENT '数据最后更新时间',
`province` varchar(50) DEFAULT NULL COMMENT '省',
`city` varchar(50) DEFAULT NULL COMMENT '市',
`confirm` int DEFAULT NULL COMMENT '累计确诊',
`now\_confirm` int DEFAULT NULL COMMENT '现有确诊',
`confirm\_add` int DEFAULT NULL COMMENT '新增确诊',
`wzz\_add` int DEFAULT NULL COMMENT '新增无症状',
`heal` int DEFAULT NULL COMMENT '累计治愈',
`dead` int DEFAULT NULL COMMENT '累计死亡',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO\_INCREMENT=528 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
历史数据表
CREATE TABLE `history` (
`ds` datetime NOT NULL COMMENT '日期',
`confirm` int DEFAULT NULL COMMENT '累计确诊',
`confirm\_add` int DEFAULT NULL COMMENT '当日新增确诊',
`local\_confirm` int DEFAULT NULL COMMENT '现有本土确诊',
`local\_confirm\_add` int DEFAULT NULL COMMENT '本土当日新增确诊',
`local\_no\_infect` int DEFAULT NULL COMMENT '现有本土无症状',
`local\_no\_infect\_add` int DEFAULT NULL COMMENT '本土当日新增无症状',
`heal` int DEFAULT NULL COMMENT '累计治愈',
`heal\_add` int DEFAULT NULL COMMENT '当日新增治愈',
`dead` int DEFAULT NULL COMMENT '累计死亡',
`dead\_add` int DEFAULT NULL COMMENT '当日新增死亡',
PRIMARY KEY (`ds`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
pymysql连接数据库
# mysql建立连接
def get\_con():
# 建立连接
con = pymysql.connect(host="127.0.0.1",
user="root",
password="",
db="",
charset="utf8")
# 创建游标
cursor = con.cursor()
return con, cursor
# mysql关闭连接
def close\_con(con, cursor):
if cursor:
cursor.close()
if con:
con.close()
password和db请配置成你的!
爬虫设计
爬虫需要模块
- requests
- json
- random
因为需要多次爬取,因此我搭建了ip代理池和ua池
# ip代理池
ips = [{"HTTP": "175.42.129.105"}, {"HTTP": "121.232.148.97"}, {"HTTP": "121.232.148.72"}]
proxy = random.choice(ips)
# headers池
headers = [
{
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
},
{
'user-agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36"
},
{
'user-agent': "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:22.0) Gecko/20130328 Firefox/22.0"
}
]
header = random.choice(headers)
爬取数据本身没有难度,数据提取比较费劲,请借助json格式化工具看清楚!
代码与展示
import traceback
import requests
import json
import time
import random
import pymysql
# ip代理池
ips = [{"HTTP": "175.42.129.105"}, {"HTTP": "121.232.148.97"}, {"HTTP": "121.232.148.72"}]
proxy = random.choice(ips)
# headers池
headers = [
{
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
},
{
'user-agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36"
},
{
'user-agent': "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:22.0) Gecko/20130328 Firefox/22.0"
}
]
header = random.choice(headers)
# 返回历史数据和当日详细数据
def get\_tencent\_data():
# 当日详情数据的url
url1 = "https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=localCityNCOVDataList,diseaseh5Shelf"
# 历史数据的url
url2 = "https://api.inews.qq.com/newsqa/v1/query/inner/publish/modules/list?modules=chinaDayListNew,chinaDayAddListNew&limit=30"
r1 = requests.get(url=url1, headers=header,proxies=proxy).text
r2 = requests.get(url=url2, headers=header,proxies=proxy).text
# json字符串转字典
data_all1 = json.loads(r1)['data']['diseaseh5Shelf']
data_all2 = json.loads(r2)['data']
# 历史数据
history = {}
for i in data_all2["chinaDayListNew"]:
# 时间
ds = i["y"] + '.' + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间 结果是时间元祖
ds = time.strftime("%Y-%m-%d", tup) # 改变时间输入格式,不然插入数据库会报错,数据库是datatime格式
confirm = i["confirm"]
local_confirm = i["localConfirm"]
local_no_infect = i["noInfectH5"]
heal = i["heal"]
dead = i["dead"]
history[ds] = {"confirm": confirm, "local\_confirm": local_confirm, "local\_no\_infect": local_no_infect ,"heal": heal, "dead": dead}
for i in data_all2["chinaDayAddListNew"]:
ds = i["y"] + '.' + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间
ds = time.strftime("%Y-%m-%d", tup) # 改变时间输入格式,不然插入数据库会报错,数据库是datatime格式
confirm_add = i["confirm"]
local_confirm_add = i["localConfirmadd"]
local_no_infect_add = i["localinfectionadd"]
heal_add = i["heal"]
dead_add = i["dead"]
history[ds].update({"confirm\_add": confirm_add, "local\_confirm\_add": local_confirm_add,"local\_no\_infect\_add":local_no_infect_add, "heal\_add": heal_add, "dead\_add": dead_add})
# 当日详细数据
details = []
update_time = data_all1["lastUpdateTime"]
data_country = data_all1["areaTree"][0]
data_province = data_country["children"] # 中国各省
for pro_infos in data_province:
province = pro_infos["name"] # 省名
for city_infos in pro_infos["children"]:
city = city_infos["name"]
# 累计确珍人数
confirm = city_infos["total"]["confirm"]
# 现有确诊人数
now_confime = city_infos["total"]["nowConfirm"]
# 新增确诊人数
confirm_add = city_infos["today"]["confirm"]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
nfirm"]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**
[外链图片转存中...(img-TfRyhKfh-1713415661133)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 1224
1224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









