










既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

[root@hadoop101 ~]# scp /etc/hosts hadoop102:/etc/
[root@hadoop101 ~]# scp /etc/hosts hadoop103:/etc/
因为集群都是HA模式,所以需要在apache集群上配置CDH集群,让distcp能识别出CDH的nameservice
[root@hadoop101 hadoop]# vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
dfs.nameservices
mycluster,nameservice1
dfs.internal.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2,nn3
dfs.namenode.rpc-address.mycluster.nn1
hadoop101:8020
dfs.namenode.rpc-address.mycluster.nn2
hadoop102:8020
dfs.namenode.rpc-address.mycluster.nn3
hadoop103:8020
dfs.ha.namenodes.nameservice1
namenode30,namenode37
dfs.namenode.rpc-address.nameservice1.namenode30
hadoop104:8020
dfs.namenode.rpc-address.nameservice1.namenode37
hadoop106:8020
dfs.namenode.http-address.nameservice1.namenode30
hadoop104:9870
dfs.namenode.http-address.nameservice1.namenode37
hadoop106:9870
dfs.client.failover.proxy.provider.nameservice1
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.namenode.http-address.mycluster.nn1
hadoop101:9870
dfs.namenode.http-address.mycluster.nn2
hadoop102:9870
dfs.namenode.http-address.mycluster.nn3
hadoop103:9870
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
修改CDH hosts
[root@hadoop101 ~]# vim /etc/hosts

进行分发,这里的hadoop104,hadoop105,hadoop106,分别对应apache的hadoop101,hadoop102,hadoop103
[root@hadoop101 ~]# scp /etc/hosts hadoop102:/etc/
[root@hadoop101 ~]# scp /etc/hosts hadoop103:/etc/
同样修改CDH集群配置,在所有hdfs-site.xml文件里修改配置

dfs.nameservices
mycluster,nameservice1
dfs.internal.nameservices
nameservice1
dfs.ha.namenodes.mycluster
nn1,nn2,nn3
dfs.namenode.rpc-address.mycluster.nn1
hadoop104:8020
dfs.namenode.rpc-address.mycluster.nn2
hadoop105:8020
dfs.namenode.rpc-address.mycluster.nn3
hadoop106:8020
dfs.namenode.http-address.mycluster.nn1
hadoop104:9870
dfs.namenode.http-address.mycluster.nn2
hadoop105:9870
dfs.namenode.http-address.mycluster.nn3
hadoop106:9870
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
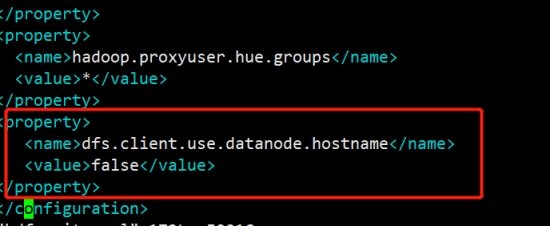
最后注意:重点由于我的Apahce集群和CDH集群3台集群都是hadoop101,hadoop102,hadoop103,所以要关闭域名访问,使用ip访问
CDH把钩去了

apache设置为false
再使用hadoop distcp命令进行迁移,-Dmapred.job.queue.name指定队列,默认是default队列。上面配置集群都配了的话,那么在CDH和apache集群下都可以执行这个命令
[root@hadoop101 hadoop]# hadoop distcp -Dmapred.job.queue.name=hive webhdfs://mycluster:9070/user/hive/warehouse/dwd.db/ hdfs://nameservice1/user/hive/warehouse

会启动一个mr任务,正在迁移

查看cdh 9870 http地址




既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
)]
[外链图片转存中…(img-FYnwBcVm-1714917951123)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









