








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
+ [05:Avro建表语法](#05Avro_349)
ODS层及DWD层构建
01:课程回顾
-
一站制造项目的数仓设计为几层以及每一层的功能是什么?
- ODS:原始数据层:存放从Oracle中同步采集的所有原始数据
- DW:数据仓库层
- DWD:明细数据层:存储ODS层进行ETL以后的数据
- DWB:轻度汇总层:对DWD层的数据进行轻度聚合:关联和聚合
- 基于每个主题构建主题事务事实表
- DWS:维度数据层:对DWD层的数据进行维度抽取
- 基于每个主题的维度需求抽取所有维度表
- ST:数据应用层
- 基于DWB和DWS的结果进行维度的聚合
- DM:数据集市层
- 用于归档存储公司所有部门需要的shuju
-
一站制造项目的数据来源是什么,核心的数据表有哪些?
- 数据来源:业务系统
- ERP:公司资产管理系统、财务数据
- 工程师信息、零部件仓储信息
- CISS:客户服务管理系统
- 工单信息、站点信息、客户信息
- 呼叫中心系统
- 来电受理信息、回访信息
-
一站制造项目中在数据采集时遇到了什么问题,以及如何解决这个问题?
- 技术选型:Sqoop
- 问题:发现采集以后生成在HDFS上文件的行数与实际Oracle表中的数据行数不一样,多了
- 原因:Sqoop默认将数据写入HDFS以普通文本格式存储,一旦遇到数据中如果包含了特殊字符\n,将一行的数据解析为多行
- 解决
- 方案一:Sqoop删除特殊字段、替换特殊字符【一般不用】
- 方案二:更换其他数据文件存储类型:AVRO
- 数据存储:Hive
- 数据计算:SparkSQL
-
什么是Avro格式,有什么特点?
- 二进制文本:读写性能更快
- 独立的Schema:生成文件每一行所有列的信息
- 对列的扩展非常友好
- Spark与Hive都支持的类型
-
如何实现对多张表自动采集到HDFS?
-
需求
- 读取表名
- 执行Sqoop命令
-
效果:将所有增量和全量表的数据采集到HDFS上
- 全量表路径:维度表:数据量、很少发生变化
/data/dw/ods/one_make/ full_imp /表名/分区/数据- 增量表路径:事实表:数据量不断新增,整体相对较大
/data/dw/ods/one_make/ incr_imp /表名/分区/数据- Schema文件的存储目录
/data/dw/ods/one_make/avsc -
Shell:业务简单,Linux命令支持
-
Python:业务复杂,是否Python开发接口
- 调用了LinuxShell来运行
-
-
Python面向对象的基本应用
-
语法
- 定义类
class 类名: # 属性:变量 # 方法:函数- 定义变量
key = value- 定义方法
def funName(参数): 方法逻辑 return -
面向对象:将所有事物以对象的形式进行编程,万物皆对象
- 对象:是类的实例
-
对象类:专门用于构造对象的,一般称为Bean,代表某一种实体Entity
- 类的组成
class 类名: # 属性:变量 # 方法:函数-
业务:实现人购买商品
- 人
class Person: # 属性 id = 1 name = zhangsan age = 18 gender = 1 …… # 方法 def eat(self,something): print(f"{self.name} eating {something}") def buy(self,something) print(f"{self.name} buy {something}")* 每个人都是一个Person类的对象- 商品
class Product: # 属性 id = 001 price = 1000.00 size = middle color = blue …… # 方法 def changePrice(self,newPrice): self.price = newPirce
-
工具类:专门用于封装一些工具方法的,utils,代表某种操作的集合
- 类的组成:一般只有方法
class 类名: # 方法:函数- 字符串处理工具类:拼接、裁剪、反转、长度、转大写、转小写、替换、查找
class StringUtils: def concat(split,args\*): split.join(args) def reverse(sourceString) return reverse(sourceString) ……- 日期处理工具类:计算、转换
class TimeUitls: def computeTime(time1,time2): return time1-time2 def transTimestamp(timestamp): return newDateyyyy-MM-dd HH:mm:ss) def tranfData(date) return timestamp -
常量类:专门用于定义一些不会发生改变的变量的类
- 类的组成:一般只有属性
class 类名: # 属性:不发生变化的属性- 定义一个常量类
class Common: ODS_DB_NAME = "one_make_ods" ……- file1.py:创建数据库 ``` create database if not exists Common.ODS_DB_NAME; ``` * file2.py:创建表 ``` ``` create table if not exists Common.ODS_DB_NAME.tbname ``` ``` + file3.py:插入数据到表中 ``` insert into table Common.ODS_DB_NAME.tbname ``` + 问题1:容易写错 + 问题2:不好修改
-
02:课程目标
- 目标:自动化的ODS层与DWD层构建
- 实现
- 掌握Hive以及Spark中建表的语法规则
- 实现项目开发环境的构建
- 自己要实现所有代码注释
- ODS层与DWD层整体运行测试成功
03:数仓分层回顾
- 目标:回顾一站制造项目分层设计
- 实施
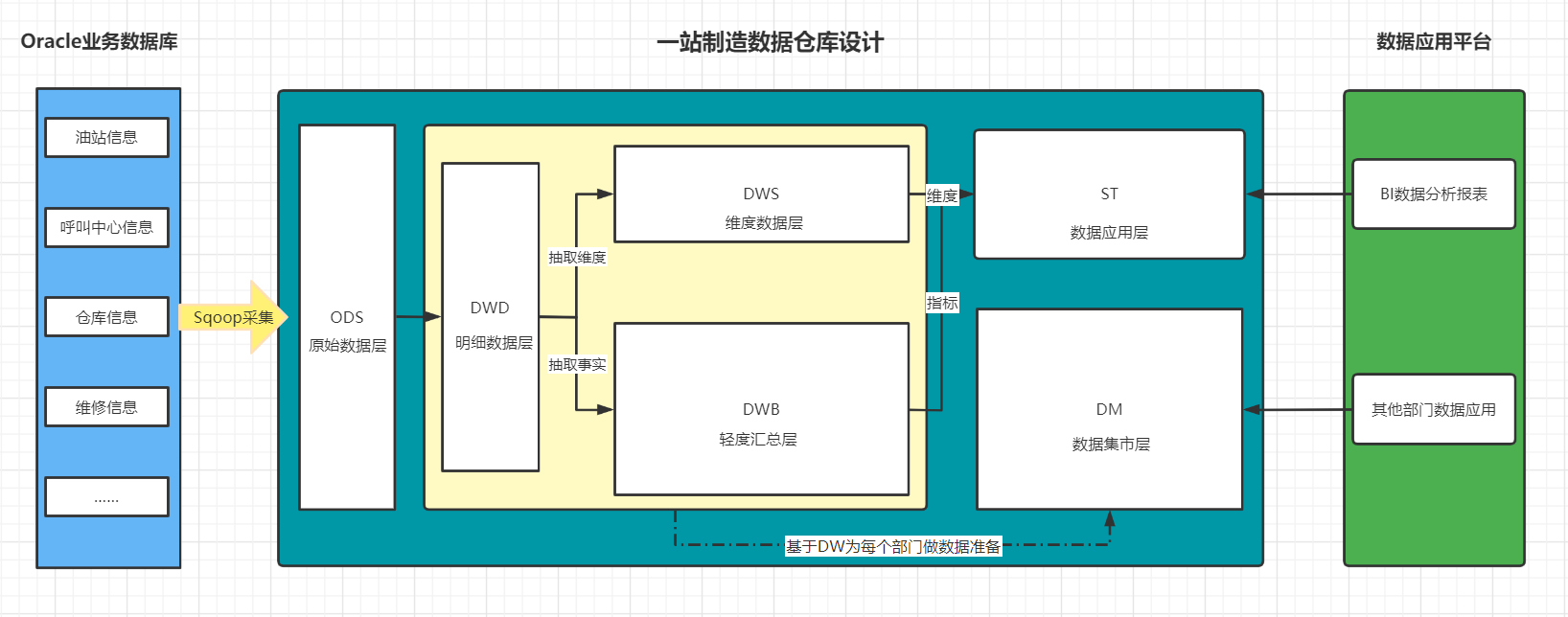
+ ODS层 :原始数据层
- 来自于Oracle中数据的采集
- 数据存储格式:AVRO
- ODS区分全量和增量
- 实现
* 数据已经采集完成
```
/data/dw/ods/one_make/full_imp
/data/dw/ods/one_make/incr_imp
```
* step1:创建ODS层数据库:one\_make\_ods
* step2:根据表在HDFS上的数据目录来创建分区表
* step3:申明分区
+ DWD层
- 来自于ODS层数据
- 数据存储格式:ORC
- 不区分全量和增量的
- 实现
* step1:创建DWD层数据库:one\_make\_dwd
* step2:创建DWD层的每一张表
* step3:从ODS层抽取每一张表的数据写入DWD层对应的表中
- 小结
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
应的表中
- 小结
[外链图片转存中…(img-RQ4qaQ2a-1715731048217)]
[外链图片转存中…(img-PtM54cYv-1715731048217)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 7687
7687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









