








网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
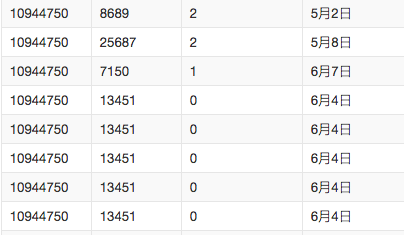
字段名含义类型描述user_id用户编号string购物的用户IDitem_id物品编号string被购买物品的编号active_type购物行为string0表示点击,1表示购买,2表示收藏,3表示购物车active_date购物时间string购物发生的时间
数据截图:
三、数据探索流程
本次实验选用的是PAI-Studio作为实验平台,仅通过拖拽组件就可以快速实现一套基于协同过滤的推荐系统。
实验流程图:
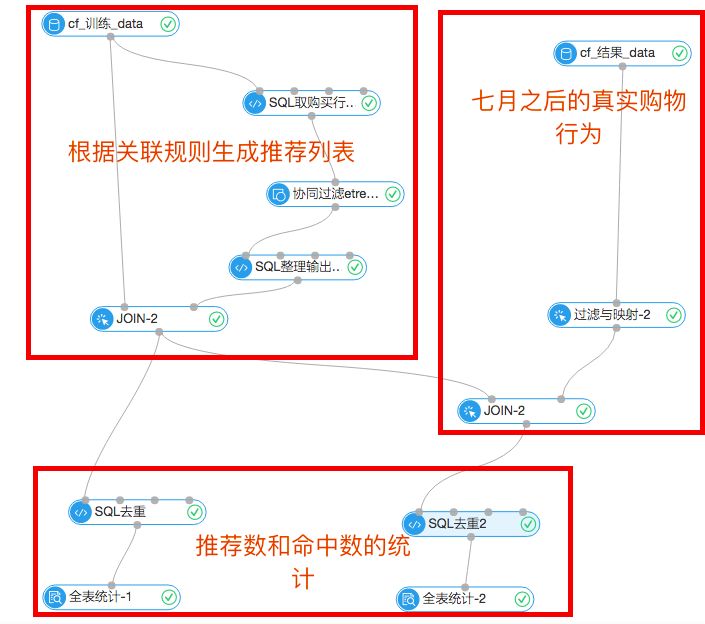
1.协同过滤推荐流程
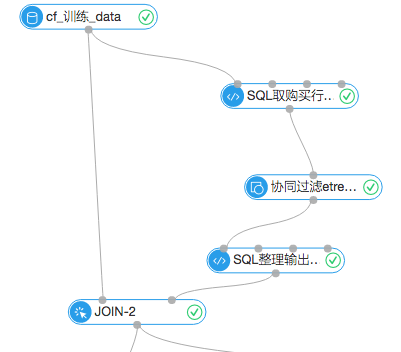
首先输入的数据源是7月份之前的购物行为数据,通过SQL脚本取出用户的购买行为数据,进入协同过滤组件,这么做的目的是简化流程,因为购买行为对这次实验分析是最有价值的。协同过滤的组件设置中把TopN设置成1,表示每个item返回最相近的item和它的权重。通过购买行为,分析出哪些商品被同一个user购买的可能性最大。设置图如下:

协同过滤结果,表示的是商品的关联性,itemid表示目标商品,similarity字段的冒号左侧表示与目标关联性高的商品,右边表示概率:

比如上图的第一条,itemid1000和item15584的相似度为0.2747133918,相似度越高表示两个物品被同时选择的概率越大。
2.推荐
上述步骤介绍了如何生成强关联商品的对应列表,这里使用了比较简单的推荐规则,比如用户甲某在7月份之前买了商品A,商品A与B强相关,我们就在7月份之后推荐了商品B,并探查这次推荐是否命中。这个步骤是通过下图实现的:

3.结果统计
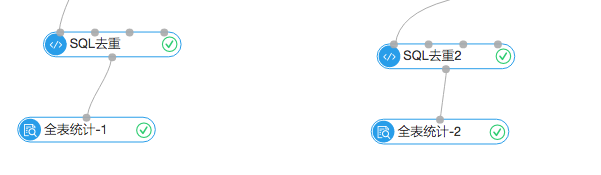
上面是统计模块,左边的全表统计展示的是根据7月份之前的购物行为生成的推荐列表,去重后一共18065条。右边的统计组件显示一共命中了90条,命中率0.4%左右。
根据上文的统计结果可以看出,本次试验的推荐效果比较一般,原因在如下几方面:
1)首先本文只是针对了业务场景大致介绍了协同过滤推荐的用法。很多针对于购物行为推荐的关键点都没有处理,比如说时间序列,购物行为一定要注意对于时效性的分析,跨度达到几个月的推荐不会有好的效果。其次没有注意推荐商品的属性,本文只考虑了商品的关联性,没有考虑商品是否为高频或者是低频商品,比如说用户A上个月买了个手机,A下个月就不大会继续购买手机,因为手机是低频消费品。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









