







debug elasticsearch-6.8.20.tar.gz kernels
//解压安装包
[root@localhost src]# tar xf elasticsearch-6.8.20.tar.gz -C /usr/local/es/
[root@localhost src]# cd /usr/local/es/
[root@localhost es]# chown -Rf es:es /usr/local/es/elasticsearch-6.8.20/
### 2.5 修改配置文件
//编辑配置文件
[root@localhost es]# vim /usr/local/es/elasticsearch-6.8.20/config/elasticsearch.yml
//取消cluster.name前的#号注释,改成自己起的名字。(注意前面的数字代表行号)
17 cluster.name: my-application
//node.name取消#号
23 node.name: node-1
//设置path.data,取消#号,改为如下的
33 path.data: /var/es/data
//设置path.logs,取消#号,改为如下的
37 path.logs: /var/es/log
//network.host取消#号,改为0.0.0.0(允许所有ip访问)
55 network.host: 0.0.0.0
//取消http.port#
59 http.port: 9200
//在文件的最后添加以下配置
89 bootstrap.memory_lock: false
90 bootstrap.system_call_filter: false
### 2.6 系统优化
//修改文件1
[root@localhost es]# vi /etc/security/limits.conf
末尾添加
62 es soft nofile 65536
63 es hard nofile 65536
64 es soft nproc 4096
65 es hard nproc 4096
//修改文件2
[root@localhost es]# vim /etc/sysctl.conf
末尾添加
11 vm.max_map_count = 655360
[root@localhost es]# sysctl -p
vm.max_map_count = 655360
### 2.7 安装jdk环境
//上传jdk安装包
[root@localhost src]# ls
debug elasticsearch-6.8.20.tar.gz jdk-8u131-linux-x64.tar.gz kernels
//解压安装包
[root@localhost src]# tar xf jdk-8u131-linux-x64.tar.gz -C /usr/local/
//添加环境变量
[root@localhost src]# vim /etc/profile
末尾添加
78 #JAVA_HOME
79 export JAVA_HOME=/usr/local/java
80 #JRE_HOME
81 export JRE_HOME=/usr/local/java/jre
82 #CALSSPATH
83 export CLASSPATH=
C
L
A
S
S
P
A
T
H
:
CLASSPATH:
CLASSPATH:{JAVA_HOME}/lib:KaTeX parse error: Expected 'EOF', got '#' at position 21: …_HOME}/lib 84 #̲PATH 85 export…PATH:
J
A
V
A
_
H
O
M
E
/
b
i
n
:
{JAVA\_HOME}/bin:
JAVA_HOME/bin:{JRE_HOME}/bin
//重命名
[root@localhost ~]# mv /usr/local/jdk1.8.0_131/ /usr/local/java
[root@localhost ~]# source /etc/profile
[root@localhost ~]# java -version
java version “1.8.0_131”
Java™ SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot™ 64-Bit Server VM (build 25.131-b11, mixed mode)
### 2.8 切换es用户启动数据库
[root@localhost ~]# su es
[es@localhost root]$ /usr/local/es/elasticsearch-6.8.20/bin/elasticsearch &
### 2.9 systemctl管理
### 2.10 访问
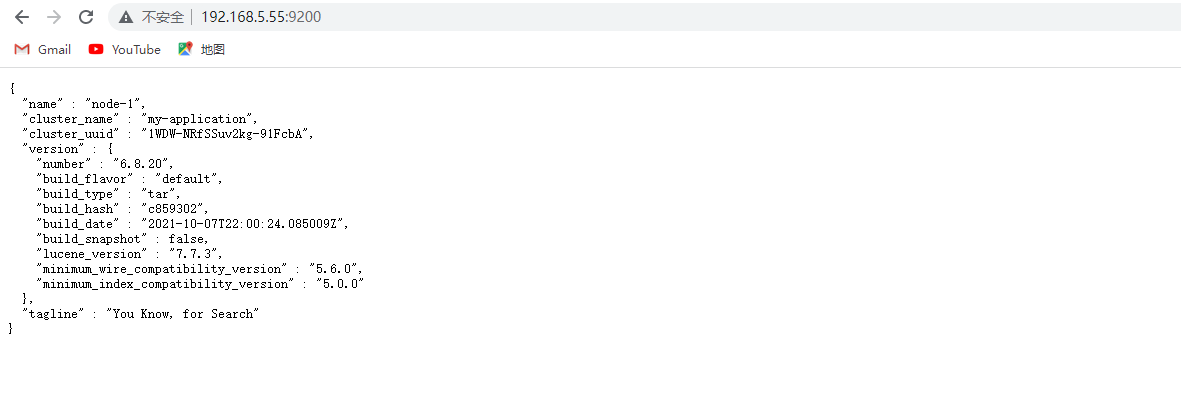
用浏览器访问ip:9200(安装的设备9200端口),看到如下的说明安装成功:
## 3. kibana
### 3.1 kibana介绍
`Kibana`是一个开源的分析与可视化平台,设计出来用于和`Elasticsearch`一起使用的。你可以用`kibana`搜索、查看存放在`Elasticsearch`中的数据。`Kibana`与`Elasticsearch`的交互方式是各种不同的图表、表格、地图等,直观的展示数据,从而达到高级的数据分析与可视化的目的。
`Elasticsearch`、`Logstash`和`Kibana`这三个技术就是我们常说的ELK技术栈,可以说这三个技术的组合是大数据领域中一个很巧妙的设计。一种很典型的MVC思想,模型持久层,视图层和控制层。Logstash担任控制层的角色,负责搜集和过滤数据。`Elasticsearch`担任数据持久层的角色,负责储存数据。而我们这章的主题`Kibana`担任视图层角色,拥有各种维度的查询和分析,并使用图形化的界面展示存放在Elasticsearch中的数据。
### 3.2 安装kibana
官网下载地址:
<https://www.elastic.co/cn/downloads/past-releases#kibana>
### 3.3 上传安装包
//使用rz命令或者xftp上传
[root@localhost src]# ls
debug elasticsearch-6.8.20.tar.gz jdk-8u131-linux-x64.tar.gz kernels kibana-6.8.20-linux-x86_64.tar.gz
### 3.4 解压文件
[root@localhost src]# tar xf kibana-6.8.20-linux-x86_64.tar.gz -C /usr/local/
### 3.5 修改配置文件
//下列的序号为行号
[root@localhost src]# vim /usr/local/kibana-6.8.20-linux-x86_64/config/kibana.yml
7 server.host: “192.168.5.55” //ES服务器主机地址
28 elasticsearch.hosts: [“http://192.168.5.55:9200”] //ES服务器地址
### 3.6 启动
[root@localhost src]# cd /usr/local/kibana-6.8.20-linux-x86_64/
[root@localhost kibana-6.8.20-linux-x86_64]# ./bin/kibana &
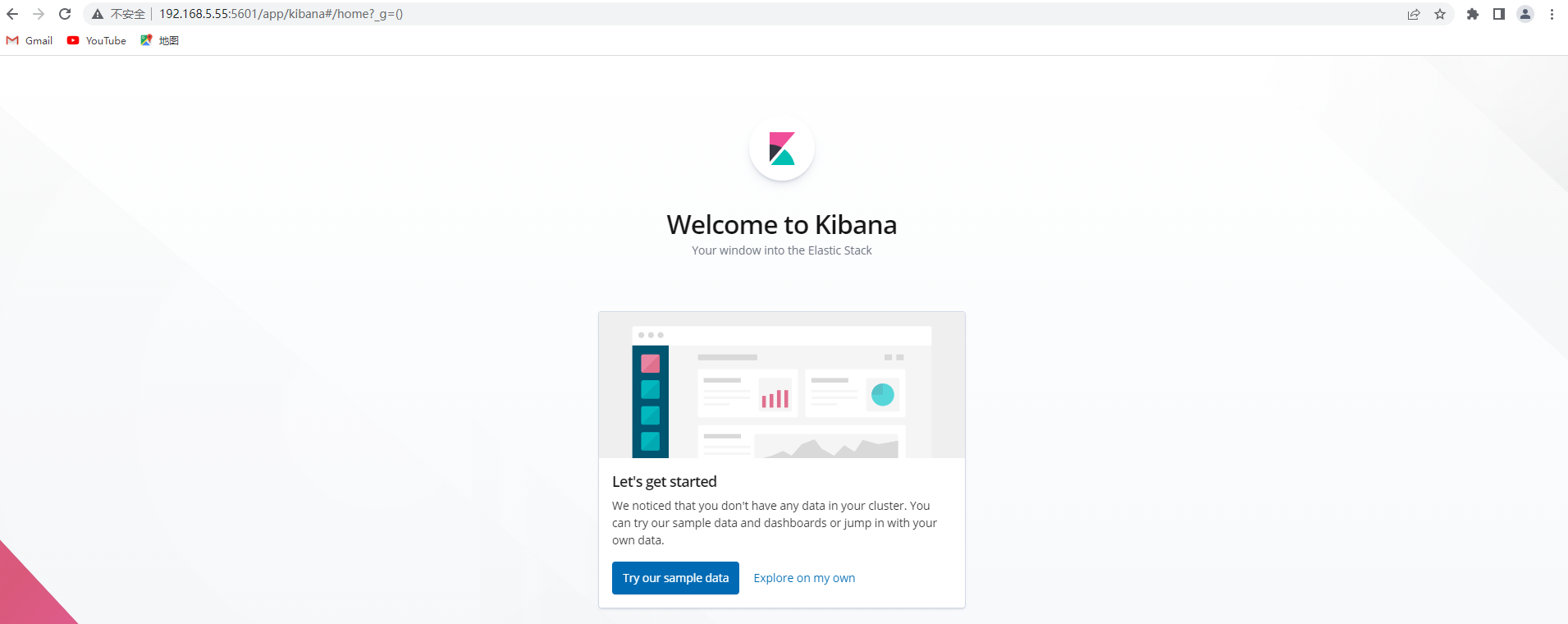
### 3.7 浏览器访问
**http://192.168.5.55:5601/app/kibana**
## 4. Elasticsearch高可用集群
### 4.1 ES是如何解决高并发
>
> ES是一个分布式全文检索框架,隐藏了复杂的处理机制,核心内容 分片机制、集群发现、分片负载请求路由。
>
>
>
### 4.2 ES基本概念名词
**Cluster**
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
**Shards**
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改
**replicas**
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
**Recovery**
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
### 4.3 ES为什么要实现集群
ES集群中索引可能由多个分片构成,并且每个分片可以拥有多个副本。通过将一个单独的索引分为多个分片,我们可以处理不能在一个单一的服务器上面运行的大型索引,简单的说就是索引的大小过大,导致效率问题。不能运行的原因可能是内存也可能是存储。由于每个分片可以有多个副本,通过将副本分配到多个服务器,可以提高查询的负载能力。
**ES集群核心原理分析:**
1. 每个索引会被分成多个分片shards进行存储,默认创建索引是分配5个分片进行存储。
每个分片都会分布式部署在多个不同的节点上进行部署,该分片成为primary shards。
注意:索引的主分片primary shards定义好后,后面不能做修改。
2. 为了实现高可用数据的高可用,主分片可以有对应的备分片replics shards,replic shards分片承载了负责容错、以及请求的负载均衡。
**注意: 每一个主分片为了实现高可用,都会有自己对应的备分片,主分片对应的备分片不能存放同一台服务器上(单台ES没有备用分片的)。主分片primary shards可以和其他replics shards存放在同一个node节点上。
在往主分片服务器存放数据时候,会对应实时同步到备用分片服务器:**
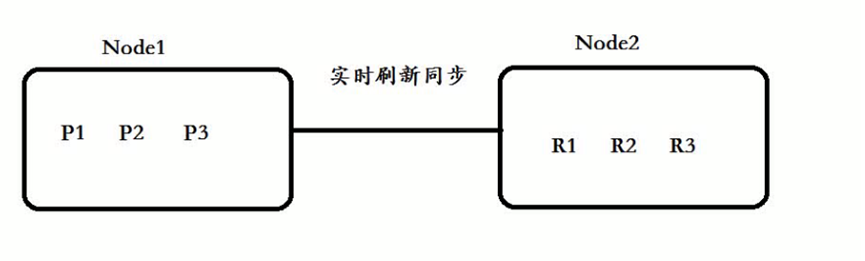
但是查询时候,所有(主、备)都进行查询。
主的可以存放副的:
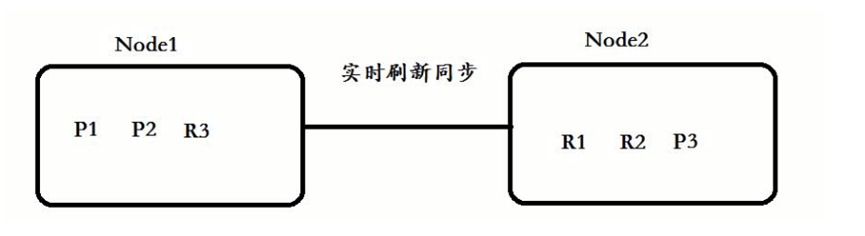
Node1 :P1+P2+R3组成了完整 的数据! 分布式存储
**ES核心存放的核心数据是索引!
如果ES实现了集群的话,会将单台服务器节点的索引文件使用分片技术,分布式存放在多个不同的物理机器上。
分片就是将数据拆分成多台节点进行存放
在ES分片技术中,分为主(primary)分片、副(replicas)分片。这样做是为了容错性**
## 5. 高可用ES集群部署
### 5.1 环境说明
系统环境:
[es@localhost root]$ cat /etc/redhat-release
CentOS Linux release 7.8.2003 (Core)
主机:
| IP地址 | 节点 | 数据库版本 | 可视化工具 |
| --- | --- | --- | --- |
| 192.168.5.55 | node1(主) | elasticsearch-6.8.20 | kibana-6.8.20 |
| 192.168.5.56 | node2 | elasticsearch-6.8.20 | |
| 192.168.5.100 | node3 | elasticsearch-6.8.20 | |
### 5.2 安装过程
需要准备好三台主机已经安装好ES数据库,安装的过程请查看目录第二节
注:关闭防火墙
### 5.3 修改配置文件
修改192.168.5.55配置文件
[root@localhost config]# pwd
/usr/local/es/elasticsearch-6.8.20/config
[root@localhost config]# vim elasticsearch.yml
注:前面的序号为行号,标记多少行
前面省略……
17 cluster.name: myes //集群名称,保证三台集群名字相同
23 node.name: node-1 //当前节点名称,集群内节点名字不能相同
33 path.data: /var/es/data //数据存放目录
37 path.logs: /var/es/log //日志存放目录
55 network.host: 0.0.0.0 //主机
59 http.port: 9200 //端口号
68 discovery.zen.ping.unicast.hosts: [“192.168.5.55”, “192.168.5.56”,“192.168.5.100”] //多个服务集群ip
72 discovery.zen.minimum_master_nodes: 1 //最少主节点数量
89 bootstrap.memory_lock: false //添加以下两行,开放网络权限
90 bootstrap.system_call_filter: false
剩下的两台利用scp命令远程覆盖配置文件
注意:记得修改节点名称,集群内节点名字不能相同
[root@localhost ~]# cd /usr/local/es/elasticsearch-6.8.20/config/
[root@localhostconfig]# scp elasticsearch.yml root@192.168.5.56:/usr/local/es/
elasticsearch-6.8.20/config/
### 5.4 启动es数据库
三台依次启动
[root@localhost config]# su es
[es@localhost config]$ /usr/local/es/elasticsearch-6.8.20/bin/elasticsearch &
### 5.5 集群测试
通过浏览器访问如下地址查看集群启动状态
192.168.5.55:9200/\_cat/health?v

//查看集群信息
[root@localhost config]# curl 192.168.5.55:9200/_cat/nodes
192.168.5.56 14 96 1 0.05 0.15 0.13 mdi - node-2
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
8.5.55:9200/_cat/nodes
192.168.5.56 14 96 1 0.05 0.15 0.13 mdi - node-2
[外链图片转存中…(img-CvubKpse-1714640540207)]
[外链图片转存中…(img-sNJRVVRG-1714640540207)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1486
1486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









