






文章目录
一、矩阵向量计算
Spark MLlib底层的向量、矩阵运算使用了Breeze库,Breeze库提供了Vector/Matrix的实现以及相应计算的接口(Linalg)。但是在MLlib里面同事也提供了Vector和Linalg等的实现。
1、Breeze创建函数

2、Breeze元素访问

3、Breeze元素操作

4、Breeze数值计算函数

5、Breeze求和函数

6、Breeze布尔函数

7、Breeze线性代数函数

8、Breeze取整函数
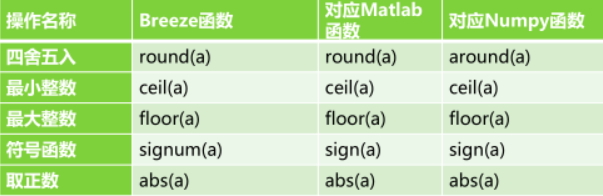
9、Breeze其他函数
Breeze三角函数:
sin、sinh、asin、asinh、cos、cosh、acos、acosh、tan、tanh、atan、atanh、atan2、sinc(x),即sin(x)/x、sincpi(x),即sinc(x\*pi)
Breeze对数和指数函数:
log、exp、log10、log1p、expm1、sqrt、sbrt、pow
二、分类效果评估指标



//正确率
val evaluator1 = new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator1.evaluate(predictions)
println(accuracy)
//f1
val evaluator2 = new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel")
.setPredictionCol("prediction")
.setMetricName("f1")
val f1 = evaluator2.evaluate(predictions)
println(f1)
//Precision
val evaluator3 = new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel")
.setPredictionCol("prediction")
.setMetricName("weightedPrecision")
val Precision = evaluator3.evaluate(predictions)
println(Precision)
//Recall
val evaluator4 = new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel")
.setPredictionCol("prediction")
.setMetricName("weightedRecall")
val Recall = evaluator4.evaluate(predictions)
println(Recall)
//AUC
val evaluator5 = new BinaryClassificationEvaluator()
.setLabelCol("indexedLabel")
.setRawPredictionCol("prediction")
.setMetricName("areaUnderROC")
val auc = evaluator5.evaluate(predictions)
println(auc)
//aupr
val evaluator6 = new BinaryClassificationEvaluator()
.setLabelCol("indexedLabel")
.setRawPredictionCol("prediction")
.setMetricName("areaUnderPR")
val aupr = evaluator6.evaluate(predictions)
println(aupr)
三、交叉-验证方法
交叉验证法先将数据集D划分为k个大小相似的互斥子集,即D=D1并D2并…并Dk,每个子集之间没有交集。然后每次用k-1个子集的并集作为训练集,余下的那个作为测试集,这样得到k组训练/测试集。可以进行k次训练和测试,最终返回的是这个k个结果的均值。可以随机使用不同的划分多次,例如:10次10折交叉验证通常把交叉验证法称为“k折交叉验证”(k-fold cross validation),k最常用的取值时10,为10折交叉验证。
示例:交叉验证
package sparkml
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator
import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
import org.apache.spark.ml.tuning.{CrossValidator, ParamGridBuilder}



**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**















 6831
6831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









