








网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
如果是5点定位,那么就需要定位左眼、右眼、鼻子。0、1、2、3、4分别表示对应的5个点。
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args[“shape_predictor”])
加载人脸检测与关键点定位。加载出来。其中`detector`默认的人脸检测器。然后通过传入参数返回人脸检测矩形框4点坐标。其中`predictor`以图像的某块区域为输入,输出一系列的点(point location)以表示此图像region里object的姿势pose。返回训练好的人脸68特征点检测器。
image = cv2.imread(args[“image”])
(h, w) = image.shape[:2]
width=500
r = width / float(w)
dim = (width, int(h * r))
image = cv2.resize(image, dim, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
这里我们把数据读了进来,然后进行需处理,提取h和w,其中我们自己设定图像的w为500,然后按照比例同比例设置h。然后进行了resize操作,最后转化为灰度图。
rects = detector(gray, 1)
这里调用了`detector`的人脸框检测器,要使用灰度图进行检测,这个1是重采样个数。这里面返回的是人脸检测矩形框4点坐标。然后对检测框进行遍历
for (i, rect) in enumerate(rects):
# 对人脸框进行关键点定位
# 转换成ndarray
shape = predictor(gray, rect)
shape = shape_to_np(shape)
这里面返回68个关键点定位。`shape_to_np`这个函数如下。
def shape_to_np(shape, dtype=“int”):
# 创建68*2
coords = np.zeros((shape.num_parts, 2), dtype=dtype)
# 遍历每一个关键点
# 得到坐标
for i in range(0, shape.num_parts):
coords[i] = (shape.part(i).x, shape.part(i).y)
return coords
这里`shape_to_np`函数的作用就是得到关键点定位的坐标。
for (name, (i, j)) in FACIAL_LANDMARKS_68_IDXS.items():
clone = image.copy()
cv2.putText(clone, name, (10, 30), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 0, 255), 2)
# 根据位置画点
for (x, y) in shape[i:j]:
cv2.circle(clone, (x, y), 3, (0, 0, 255), -1)
# 提取ROI区域
(x, y, w, h) = cv2.boundingRect(np.array([shape[i:j]]))
roi = image[y:y + h, x:x + w]
(h, w) = roi.shape[:2]
width=250
r = width / float(w)
dim = (width, int(h \* r))
roi = cv2.resize(roi, dim, interpolation=cv2.INTER_AREA)
# 显示每一部分
cv2.imshow("ROI", roi)
cv2.imshow("Image", clone)
cv2.waitKey(0)
这里字典`FACIAL_LANDMARKS_68_IDXS.items()`是同时提取字典中的key和value数值。然后遍历出来这几个区域,并且进行显示具体是那个区域,并且将这个区域画圆。随后提取roi区域并且进行显示。后面部分就是同比例显示w和h。然后展示出来。
output = visualize_facial_landmarks(image, shape)
cv2.imshow("Image", output)
cv2.waitKey(0)
最后展示所有区域。
其中`visualize_facial_landmarks`函数就是:
def visualize_facial_landmarks(image, shape, colors=None, alpha=0.75):
# 创建两个copy
# overlay and one for the final output image
overlay = image.copy()
output = image.copy()
# 设置一些颜色区域
if colors is None:
colors = [(19, 199, 109), (79, 76, 240), (230, 159, 23),
(168, 100, 168), (158, 163, 32),
(163, 38, 32), (180, 42, 220)]
# 遍历每一个区域
for (i, name) in enumerate(FACIAL_LANDMARKS_68_IDXS.keys()):
# 得到每一个点的坐标
(j, k) = FACIAL_LANDMARKS_68_IDXS[name]
pts = shape[j:k]
# 检查位置
if name == “jaw”:
# 用线条连起来
for l in range(1, len(pts)):
ptA = tuple(pts[l - 1])
ptB = tuple(pts[l])
cv2.line(overlay, ptA, ptB, colors[i], 2)
# 计算凸包
else:
hull = cv2.convexHull(pts)
cv2.drawContours(overlay, [hull], -1, colors[i], -1)
# 叠加在原图上,可以指定比例
cv2.addWeighted(overlay, alpha, output, 1 - alpha, 0, output)
return output
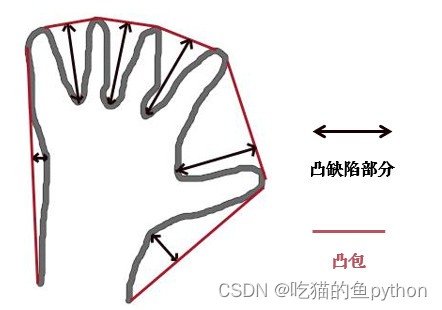
这个函数是计算`cv2.convexHull`凸包的,也就是下图这个意思。
这个函数`cv2.addWeighted`是做图像叠加的。
>
> src1, src2:需要融合叠加的两副图像,要求大小和通道数相等
> alpha:src1 的权重
> beta:src2 的权重
> gamma:gamma 修正系数,不需要修正设置为 0
> dst:可选参数,输出结果保存的变量,默认值为 None
> dtype:可选参数,输出图像数组的深度,即图像单个像素值的位数(如 RGB 用三个字节表示,则为 24 位),选默认值 None 表示与源图像保持一致。
>
>
>
dst = src1 × alpha + src2 × beta + gamma;上面的式子理解为,结果图像 = 图像 1× 系数 1+图像 2× 系数 2+亮度调节量。
### 🌟完整代码及效果展示
from collections import OrderedDict
import numpy as np
import argparse
import dlib
import cv2
ap = argparse.ArgumentParser()
ap.add_argument(“-p”, “–shape-predictor”, required=True,
help=“path to facial landmark predictor”)
ap.add_argument(“-i”, “–image”, required=True,
help=“path to input image”)
args = vars(ap.parse_args())
FACIAL_LANDMARKS_68_IDXS = OrderedDict([
(“mouth”, (48, 68)),
(“right_eyebrow”, (17, 22)),
(“left_eyebrow”, (22, 27)),
(“right_eye”, (36, 42)),
(“left_eye”, (42, 48)),
(“nose”, (27, 36)),
(“jaw”, (0, 17))
])
FACIAL_LANDMARKS_5_IDXS = OrderedDict([
(“right_eye”, (2, 3)),
(“left_eye”, (0, 1)),
(“nose”, (4))
])
def shape_to_np(shape, dtype=“int”):
# 创建68*2
coords = np.zeros((shape.num_parts, 2), dtype=dtype)
# 遍历每一个关键点
# 得到坐标
for i in range(0, shape.num_parts):
coords[i] = (shape.part(i).x, shape.part(i).y)
return coords
def visualize_facial_landmarks(image, shape, colors=None, alpha=0.75):
# 创建两个copy
# overlay and one for the final output image
overlay = image.copy()
output = image.copy()
# 设置一些颜色区域
if colors is None:
colors = [(19, 199, 109), (79, 76, 240), (230, 159, 23),
(168, 100, 168), (158, 163, 32),
(163, 38, 32), (180, 42, 220)]
# 遍历每一个区域
for (i, name) in enumerate(FACIAL_LANDMARKS_68_IDXS.keys()):
# 得到每一个点的坐标
(j, k) = FACIAL_LANDMARKS_68_IDXS[name]
pts = shape[j:k]
# 检查位置
if name == “jaw”:
# 用线条连起来
for l in range(1, len(pts)):
ptA = tuple(pts[l - 1])
ptB = tuple(pts[l])
cv2.line(overlay, ptA, ptB, colors[i], 2)
# 计算凸包
else:
hull = cv2.convexHull(pts)
cv2.drawContours(overlay, [hull], -1, colors[i], -1)
# 叠加在原图上,可以指定比例
cv2.addWeighted(overlay, alpha, output, 1 - alpha, 0, output)
return output
加载人脸检测与关键点定位
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args[“shape_predictor”])
读取输入数据,预处理
image = cv2.imread(args[“image”])
(h, w) = image.shape[:2]
width=500
r = width / float(w)
dim = (width, int(h * r))
image = cv2.resize(image, dim, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
人脸检测
rects = detector(gray, 1)
遍历检测到的框
for (i, rect) in enumerate(rects):
# 对人脸框进行关键点定位
# 转换成ndarray
shape = predictor(gray, rect)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
glPP-1715272192010)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 828
828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









