










既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
===================================================================
-
基于内存进行计算(即计算过程中没有中间数据落盘),能够对 PB 级数据进行交互式实时查询、分析
-
无需转换为 MR,直接读取 HDFS 及 Kudu 数据 ,从而大大降低了延迟。
-
Impala 没有 MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由 Query Planner、Query Coordinator 和Query Exec Engine 三部分组成)
-
前端 java、后端 C++ 编写,使用 LLVM 框架统一编译运行(区别于 GCC)
-
兼容 HiveSQL
-
支持 Hive 基本的一些查询等,Hive 中的一些复杂结构是不支持的
-
具有数据仓库的特性,可对 Hive 数据直接做数据分析
===================================================================
-
Impala支持内存中数据处理,它访问/分析存储在Hadoop数据节点上的数据,而无需数据移动。
-
使用类SQL查询访问数据。
-
Impala为HDFS中的数据提供了更快的访问。
-
可以将数据存储在Impala存储系统中,如Apache HBase和Amazon s3。
-
Impala支持各种文件格式,如LZO,序列文件,Avro,RCFile和Parquet。
==========================================================================
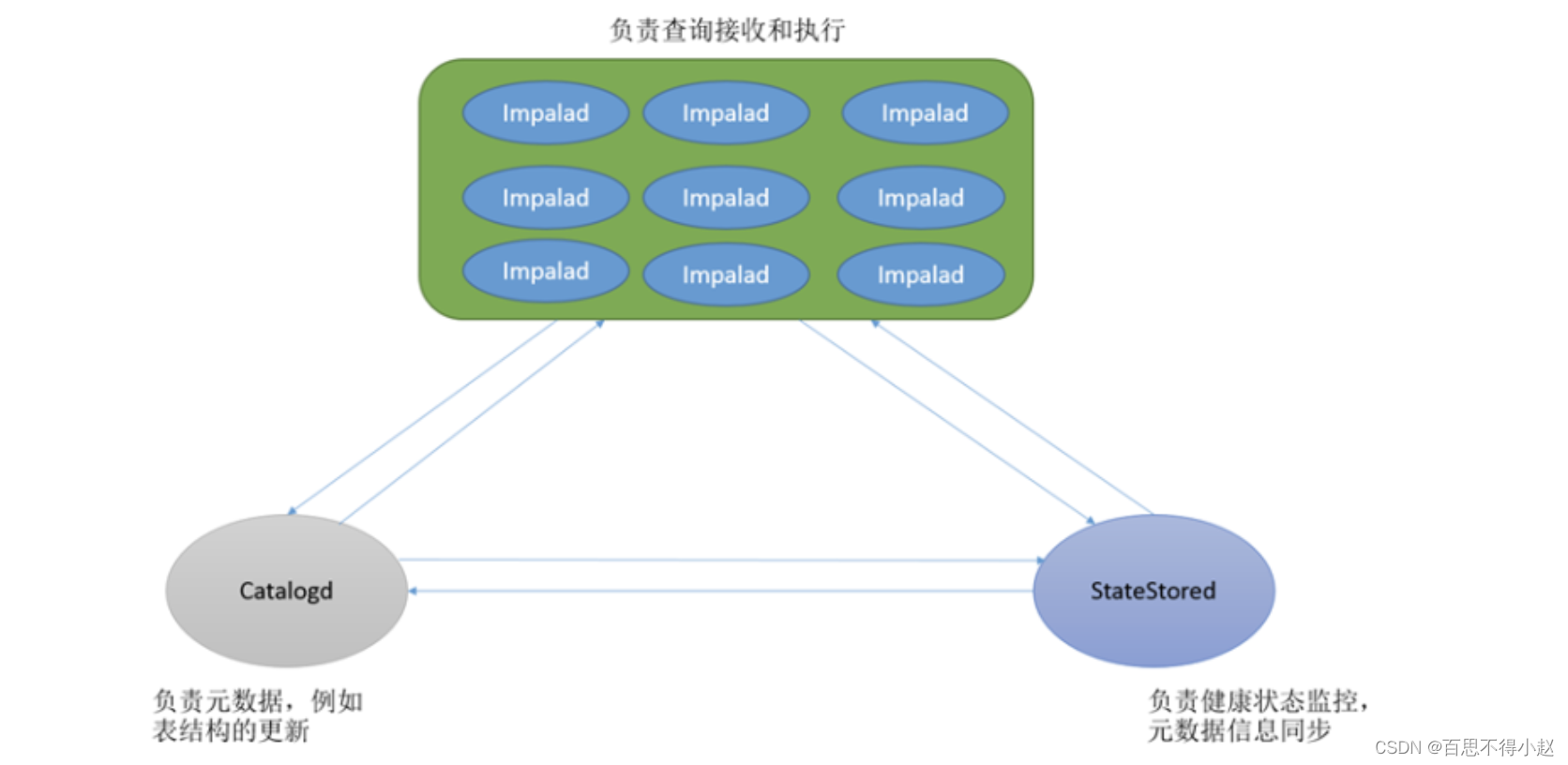
Impalad:
Impala 核心组件,运行在各个数据节点上面, 守护进程 Impala daemon,它负责接收从 impala-shell、Hue、JDBC、ODBC 等接口发送的查询语句,解析 SQL 语句并执行查询任务,任务完成返回结果给到客户端。Impalad 内部是由 Query Planner、Query Coordinator 和 Query Executor 三部分组成:。
State Store:
负责检查集群各个节点上 Impala daemon 的健康状态,同时不间断地将结果反馈给各个 Impala daemon。守护进程 :statestored,整个集群只运行一个进程。
Catalogd:
负责元数据管理,可以从 Hive 元数据库中提取更新元数据给其他组件,也能将元数据变化通知给集群的各个节点,
=====================================================================
连接 Impala
impala-shell -i data -s xxx -d rawdata -k
-d:指定数据库登录
-i:指定 impalad 登录,这个一般在 元数据节点连接 impala 的时候,要指定
-k:如果启用 kerberos,则需要指定
-s:指定 kerberos 登录的账号,如果不指定,默认账号是 “impala” ,如果混部 kerberos 场景下,客户给我们的 principal 是 sa_cluster,那就要指定 -s 为 sa_cluster
-q:直接执行 sql 语句,不用进入 impala-shell 环境
-o:查询结果输出到指定文件




既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**















 792
792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









