










既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
写入数据时,会先通过hashcode算法算出要写入的segment(桶的位置),然后锁定当前segment,而不是锁定整个数组,所以读写效率比hashTable要高很多。
3.3.1分段数组
分段数组是一种数据结构,用于解决动态区间查询的问题。它将一个大的数组划分为若干个较小的块,每个块包含一定数量的元素。每个块都保存了该块内元素的一些预处理信息,例如最大值、最小值、和等。这样,在查询时,可以通过对块进行预处理和对块内元素进行操作,来快速得到查询结果。
分段数组的主要优势在于它能够在保持较小的块大小的同时,提供较快的查询操作。当需要对整个数组进行查询时,可以通过对每个块进行操作,然后将结果合并得到最终结果。这样可以减少查询的时间复杂度。
分段数组的实现方式有多种,常见的有块状链表和树状数组。块状链表将数组划分为若干个块,并使用链表将这些块连接起来。树状数组则使用二进制索引树的结构来实现。
总结来说,分段数组是一种用于解决动态区间查询问题的数据结构,通过将大数组划分为小块,并对每个块进行预处理和操作,可以提高查询效率。
4.SpringAop
1.常见的使用场景
- 日志记录
- 异常处理
- 权限验证
- 缓存处理
- 效率检查
2.springAop用的动态代理还是反射
答:动态代理
2.1动态代理有两种能讲讲吗?
JDK动态代理只提供接口代理,不支持类代理
核心:InvocationHandler接口和Proxy类
InvocationHandler通过invok()方法反射来调用目标类中的代码,动态的将横切逻辑和业务编织在一起,Proxy类利用InvocationHandler动态创建一个符合某一接口的实例,生成目标类的代理对象。
CGLIB通过继承方式做的动态代理
如果代理类没有实现InvocationHandler接口,那么SpringAop会使用CGLIB来动态代理目标类。
CGLIB是一个代码生成的类库,在运行时动态的生成指定类的一个子类对象,覆盖其中特定的方法并添加增强代码,实现AOP。
通过继承的方式做的动态代理,如果某个类被标记为final,那么它是无法使用CGLIB的,
5. sleep和wait的区别
sleep不会释放当前占有的锁,需要捕获异常
wait 只有等待另外的线程通知或被中断才会返回,会释放对象的锁,一般用在同步方法或者同步代码块中,不需要捕获异常
6.notify和notifyall的区别
notify会随机从等待池中选择一个线程进行唤醒
notifyall会唤醒所有线程进行竞争锁的机会
7.传输协议
TCP传输控制协议,是一种面向连接的,可靠的,基于IP的传输层协议。
UDP无连接的传输层协议,提供面向事务的简单不可靠的传送服务。
7.1 TCP和UDP的区别
- 基于连接 无连接
- 数据正确性 可能丢包
- 保证数据顺序 不保证
8.JVM的内存模型
Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域,这些数据区域都有各自的用途,以及创建和销毁的时间,并且它们可以分为两种类型:线程共享的方法区和堆,线程私有的虚拟机栈、本地方法栈和程序计数器。在此基础上,我们探讨了在虚拟机中对象的创建和对象的访问定位等问题,并分析了Java虚拟机规范中异常产生的情况。
1)、程序计数器
为了线程切换后能够恢复到正确的执行位置,每条线程都需要一个独立的程序计数器去记录其正在执行的字节码指令地址。
2)、虚拟机栈
**虚拟机栈描述的是Java方法执行的内存模型,是线程私有的。**每个方法在执行的时候都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接、方法出口等信息,而且 每个方法从调用直至完成的过程,对应一个栈帧在虚拟机栈中入栈到出栈的过程。
3)、本地方法栈
本地方法栈与Java虚拟机栈非常相似,也是线程私有的,区别是虚拟机栈为虚拟机执行 Java 方法服务,而本地方法栈为虚拟机执行 Native 方法(非Java语言)服务
2、线程共享的数据区
线程共享的数据区 具体包括 Java堆 和 方法区 两个区域,它们的内涵分别如下:
1)、Java 堆
Java 堆的唯一目的就是存放对象实例,几乎所有的对象实例(和数组)都在这里分配内存。
2)、方法区
*方法区与Java堆一样,也是线程共享的并且不需要连续的内存,其用于存储已被虚拟机加载的 *类信息*、*常量*、*静态变量*、*即时编译器编译后的代码等数据。
9.元空间
- JDK7以前
在7以及之前堆和方法区连在了一起,但这并不能说堆和方法区是一起的,它们在逻辑上依旧是分开的。但在物理上来说,它们又是连续的一块内存
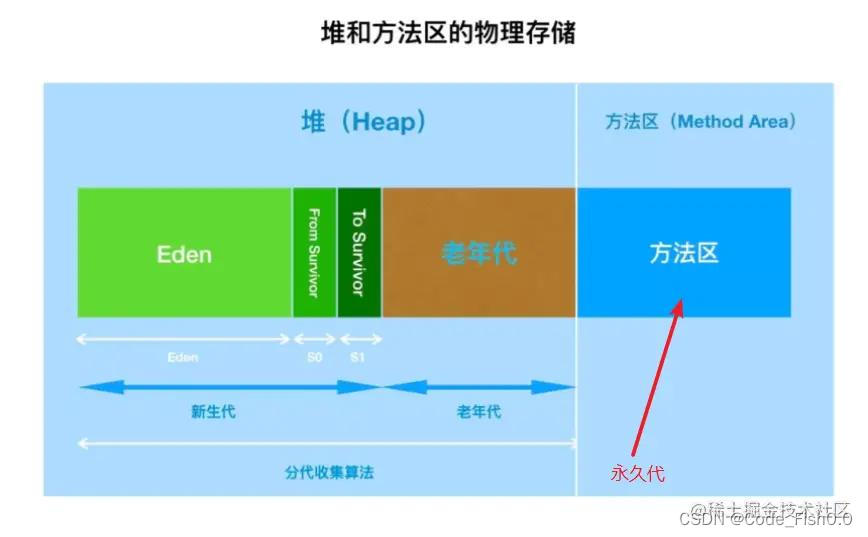
“永久代(Permanet Generation,也称PermGen)”。对于习惯了在HotSpot虚拟机上开发、部署的程序员来说,很多人都愿意将方法区称作永久代。
HotSpot虚拟机:
Java是一种解释类型的语言,但并不意味着它一定被解释执行。早期的虚拟机确实是通过解释器( Interpreter )一条一条指令依次解释执行的,但人们发现这样效率太低, 难以满足各种要求,因此出现了许多其它虚拟机,例如 JIT 虚拟机。当虚拟机发现某个方法或代码块的运行特别频繁的时候,就会把这些代码认定为“热点代码”。为了提高热点代码的执行效率,在运行时,即时编译器(Just In Time Compiler ) 会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化。
而HotSpot也是类似一种虚拟机,自从SUN买下后,已经把它放入 JRE 1.3以及后续版本中,它顶替了JIT虚拟机,也是目前使用范围最广的Java虚拟机。
采用HotSpot的Java虚拟机,已经很难说Java是被虚拟机解释执行了,因为原来的Java是将源代码编译为字节码后运行在虚拟机上,而HotSpot实际上是把Java的部分常用bytecode编译成本地代码Native code,然后运行,大大提高了Java的运行性能。
总结:由于编译器一条一条的指令依次解释执行效率低,所以当如果模块代码运行频发的时候(热点代码),编译器会把热点代码编译成与本地平台相关的机器码HotSpot应运而生
- JDK8以后
Hotspot取消了永久代,改为了元空间
方法区存在于元空间(Metaspace),同时元空间不再与堆连续,而且是存在于本地内存(Native memory)。
元空间存在于本地内存,意味着只要本地内存足够,它不会出现像永久代中的
默认情况下元空间是可以无限使用本地内存的,但为了不让它如此膨胀,JVM同样提供了参数来限制它使用的使用。
- -XX:MetaspaceSize,class metadata的初始空间配额,以bytes为单位,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当的降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize(如果设置了的话),适当的提高该值。
- -XX:MaxMetaspaceSize,可以为class metadata分配的最大空间。默认是没有限制的。
- -XX:MinMetaspaceFreeRatio,在GC之后,最小的Metaspace剩余空间容量的百分比,减少为class metadata分配空间导致的垃圾收集。
- -XX:MaxMetaspaceFreeRatio,在GC之后,最大的Metaspace剩余空间容量的百分比,减少为class metadata释放空间导致的垃圾收集。
9.1 为什么永久代消失了
表面上看是为了避免OOM异常。因为通常使用PermSize和MaxPermSize设置永久代的大小就决定了永久代的上限,但是不是总能知道应该设置为多大合适, 如果使用默认值很容易遇到OOM错误(内存溢出)。
当使用元空间时,可以加载多少类的元数据就不再由MaxPermSize控制, 而由系统的实际可用空间来控制。
更深层的原因还是要合并HotSpot和JRockit的代码,使用了元空间取代永久代,不用担心运行性能问题了,在覆盖到的测试中, 取代后程序启动和运行速度降低不超过1%,但是这点性能损失换来了更大的安全保障。
10.数据库执行效率
10.1 定位执行 效率慢的sql
mysql内置的explain + sql语句
10.2索引优化
- 最左前缀法则
如果建立的复合索引,执行顺序要按照建立时的顺序执行
- 不能使用null判断 != > < 不做列运算
- 尽量避免在where子句中使用or来连接条件,一个字段有索引,一个没索引,会失效
- 左%的匹配查询不写
10.3 创建索引的语句
- 主键索引:创建表时自动创建 { 聚集索引:一个表中只有一个聚集索引 }
- 唯一索引:CREATE UNIQUE INDEX unique_index_warn[索引名称] ON cas_alarm[表名] (warn_id[列名])
- 普通索引:CREATE INDEX index_saas_report_service_status[索引名称] ON saas_report_service_status[表名] (service_status[列名]);
- 组合索引:CREATE INDEX index_saas_report_service_type[索引名称] ON saas_report_service_status[表名] (service_type[列名],service_status[列名],sort_value[列名]);
10.4数据库引擎
- mysql5.5版本之前用的MyISAM 存储引擎
不支持事务
- 之后用的 InnoDB存储引擎
支持事务,支持行级锁
11. mybatis的缓存机制
- 一级缓存
sqlSession级别的,默认开启无法关闭。
- 二级缓存
默认没有开启,需要手动开启
作用域Mapper
需要实现Serializable序列化接口
11.1如何开启二级缓存
在Setting全局参数中配置开启二级缓存,conf.xml配置:
<setting>
<setting name="cacheEnable" value="true"></setting> 默认是false,关闭二级缓存
</setting>
12.MongoDb数据模型
数据库database
集合collection(表)
文档document(行)
字段field(列)
13.ElasticSearch如何使用的
通过@configuration注解创建使用Es的对象RestHighLevelClient交给容器管理
调用RestHighLevelClient对象进行操作
14.Linux的常见常用命令
查看当前系统发行版本详细信息
LSB是Linux Standard Base的缩写,lsb_release命令用来显示LSB和特定版本的相关信息
lsb_release -a
被问到:查看当前系统内核信息
uname -a
查看当前系统版本信息
cat /proc/version
查看CPU相关信息
cat /proc/cpuinfo
查看系统位数
getconf LONG_BIT
查看本机ip地址
ip addr
路径跳转
cd 所要跳转的路径
创建目录
mkdir 目录名称
创建多层目录
mkdir -p(小写的)
显示当前工作目录
pwd -P(大写的)
显示当前目录下隐藏文件
ls -a
删除空文件夹
rmdir 想要删除的空目录路径
创建文件
touch 文件名.文件类型
显示指定文件或文件夹的详细信息
stat 文件路径
获取指定文件的类型
file 文件路径
查看当前账户/其他账户 uid/gid
id
id 账户名
查看当前文件夹下文件及文件夹所属账户
ll
查看进程列表
ps aux|less
创建用户
useradd 用户名 //会默认创建一个和用户名一样的组
useradd 用户名 -G 组名 //前提是已经创建分组了 //往主组之后添加新组
useradd 用户名 -d 文件夹路径 //给新创建的用户指定操作目录
默认生成的uid是在现有最大id的基础上+1
useradd 用户名 -u 指定用户编号(编号只能为数字且不可重复)
useradd 用户名 -g 指定用户主组编号/名称 //直接替换主组,只保留一个组
创建组
groupadd 组名
groupadd 组名 -g 编号(gid)//创建指定编号的组
组的作用:
可以更方便的对部分用户做权限操作
例如
ss01用户 刚开始只是普通权限,由于工作需要,需要对权限进行调整
那么可以直接把ss01加入该权限的组中即可,不用再单独设置权限。
给账户添加组
gpasswd -a yangyang01 dcc01
//yangyang01是要修改的账户名
//dcc01是要添加进的组名(只能是组名不能是gid)
查看组的信息
tail /etc/group
//新创建的组会在文件的最下面显示
删除用户
userdel 用户名
userdel -r 用户名 //删的更彻底
修改用户密码
passwd 用户名
普通用户获取管理员权限
sudo su
修改某一个文件或文件夹的属主/属组
chown 所要修改的账户名 修改的文件/文件夹路径
//如果要同时修改属主和属组则
chown 所要修改的账户名.所修改的组名 修改的文件/文件夹路径
修改文件属组
chgrp 所修改的组名 修改的文件/文件夹路径
//若要修改该文件夹下所有文件的属组则
chgrp -R 所修改的组名 修改的文件/文件夹路径
//-R为递归参数
修改文件权限
chmod 对象+权限 文件/文件夹路径
//删除所有对象的权限
chmod a=- 文件/文件夹路径
//同时给不同身份修改权限 不同身份操作之间用,隔开
chmod u=r,g=rx,o+w 文件/文件夹路径
15.docker的常用命令
1、Docker创建并启动容器
docker run [OPTIONS] IMAGE [COMMAND] [ARG…]
--name="容器新名字":为容器指定一个名称;
-i:以交互模式运行容器,通常与-t或者-d同时使用;
-t:为容器重新分配一个伪输入终端,通常与-i同时使用;
-d: 后台运行容器,并返回容器ID;
-P: 随机端口映射,容器内部端口随机映射到主机的端口
-p: 指定端口映射,格式为:主机(宿主)端口:容器端口
启动普通容器: docker run --name 别名 镜像ID (不常用)
启动交互式容器: docker run -it --name 别名 镜像ID 来运行一个容器,取别名,交互模式运行,以及分配一个伪终端,并且进入伪终端;
实例:
docker run -it --name mycentos03 67fa590cfc1c
注意:
1、启动普通容器的方式基本不用,没有伪终端,没有太大价值;
2、启动交互式容器的方式,容器一创建完毕,立即进入伪终端
守护式方式创建并启动容器
docker run -di --name 别名 镜像ID
实例:
docker run -di --name mycentos02 67fa590cfc1c
2、Docker列出容器
OPTIONS说明:
-a :显示所有的容器,包括未运行的。
-f :根据条件过滤显示的内容。
--format :指定返回值的模板文件。
-l :显示最近创建的容器。
-n :列出最近创建的n个容器。
--no-trunc :不截断输出。
-q :静默模式,只显示容器编号。
-s :显示总的文件大小。
3、Docker退出容器
exit 容器停止退出
ctrl+P+Q 容器不停止退出
4、Docker进入容器
a、docker attach 容器ID or 容器名
实例:
docker attach ce6343ee288f
不能进入停止的状态的容器
You cannot attach to a stopped container, start it first
b、Docker进入容器执行命令
docker exec -it 容器名称 或者 容器ID 执行命令
实例:
docker exec -it tomcat02 ls -l /root/webapp02
直接操作容器,执行完 回到 宿主主机终端;
我们一般用于 启动容器里的应用 比如 tomcat nginx redis elasticsearch等等
5、Docker启动容器
docker start 容器ID or 容器名
实例:
docker start mycentos00
6、Docker重启容器
docker restart 容器ID or 容器名
实例:
docker restart f9cadea1a5e7
7、Docker停止容器
docker stop 容器ID or 容器名
实例:
docker stop 865b755cd0b2
暴力删除,直接杀掉进程 (不推荐)
docker kill 容器ID or 容器名
8、Docker删除容器
docker rm 容器ID
如果删除正在运行的容器,会报错,我们假如需要删除的话,需要强制删除;
强制删除docker rm -f 容器ID
删除多个容器
docker rm -f 容器ID1 容器ID2 中间空格隔开
实例:
docker rm 865b755cd0b2 ce6343ee288f
删除所有容器
docker rm -f $(docker ps -qa)
9、Docker容器日志
$ docker logs [OPTIONS] CONTAINER
Options:
--details 显示更多的信息
-f, --follow 跟踪实时日志
--since string 显示自某个timestamp之后的日志,或相对时间,如42m(即42分钟)
--tail string 从日志末尾显示多少行日志, 默认是all
-t, --timestamps 显示时间戳
--until string 显示自某个timestamp之前的日志,或相对时间,如42m(即42分钟)
16.redis
问:如果做秒杀功能需要使用什么数据类型
list可用于秒杀抢购场景
在商品秒杀场景最怕的就是商品超卖,为了解决超卖问题,我们经常会将库存商品缓存到类似MQ的队列中,多线程的购买请求都是从队列中取,取完了就卖完了,但是用MQ处理的化有点重,这里就可以使用redis的list数据类型来实现,在秒杀前将本场秒杀的商品放到list中,因为list的pop操作是原子性的,所以即使有多个用户同时请求,也是依次pop,list空了pop抛出异常就代表商品卖完了。
问:如果做排行榜功能需要使用什么数据类型
用Zset数据类型
一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重。
17.redis AOF,RDB 等持久化方式
RDB在不同的时间点,将redis存储的数据生成快照并存储到磁盘等介质上。(默认的持久化方式)
AOF,将redis执行的所有指令记录下来,下次重新启动redis时,只要把这些写指令从前到后重新执行一遍,就可以实现数据恢复了。
两种方式可以同时使用,如果redis重启的话,则会优先采用AOF方式来进行数据恢复,这是因为AOF方式的数据恢复完整度更高。
18.kafka为什么吞吐量高
1.顺序读写
Kafka是将消息记录持久化到本地磁盘中的,一般人会认为磁盘读写性能差,可能会对Kafka性能如何保证提出质疑。实际上不管是内存还是磁盘,快或慢关键在于寻址的方式,磁盘分为顺序读写与随机读写,内存也一样分为顺序读写与随机读写。基于磁盘的随机读写确实很慢,但磁盘的顺序读写性能却很高,一般而言要高出磁盘随机读写三个数量级,一些情况下磁盘顺序读写性能甚至要高于内存随机读写。
磁盘的顺序读写是磁盘使用模式中最有规律的,并且操作系统也对这种模式做了大量优化,Kafka就是使用了磁盘顺序读写来提升的性能。Kafka的message是不断追加到本地磁盘文件末尾的,而不是随机的写入,这使得Kafka写入吞吐量得到了显著提升 。
2.Page Cache
为了优化读写性能,Kafka利用了操作系统本身的Page Cache,就是利用操作系统自身的内存而不是JVM空间内存。这样做的好处有:
1避免Object消耗:如果是使用 Java 堆,Java对象的内存消耗比较大,通常是所存储数据的两倍甚至更多。
2避免GC问题:随着JVM中数据不断增多,垃圾回收将会变得复杂与缓慢,使用系统缓存就不会存在GC问题
相比于使用JVM或in-memory cache等数据结构,利用操作系统的Page Cache更加简单可靠。首先,操作系统层面的缓存利用率会更高,因为存储的都是紧凑的字节结构而不是独立的对象。其次,操作系统本身也对于Page Cache做了大量优化,提供了 write-behind、read-ahead以及flush等多种机制。再者,即使服务进程重启,系统缓存依然不会消失,避免了in-process cache重建缓存的过程。
通过操作系统的Page Cache,Kafka的读写操作基本上是基于内存的,读写速度得到了极大的提升。
3.零拷贝
通过这种 “零拷贝” 的机制,Page Cache 结合 sendfile 方法,Kafka消费端的性能也大幅提升。这也是为什么有时候消费端在不断消费数据时,我们并没有看到磁盘io比较高,此刻正是操作系统缓存在提供数据。
4.分区分段+索引
Kafka的message是按topic分类存储的,topic中的数据又是按照一个一个的partition即分区存储到不同broker节点。每个partition对应了操作系统上的一个文件夹,partition实际上又是按照segment分段存储的。这也非常符合分布式系统分区分桶的设计思想。
通过这种分区分段的设计,Kafka的message消息实际上是分布式存储在一个一个小的segment中的,每次文件操作也是直接操作的segment。为了进一步的查询优化,Kafka又默认为分段后的数据文件建立了索引文件,就是文件系统上的.index文件。这种分区分段+索引的设计,不仅提升了数据读取的效率,同时也提高了数据操作的并行度。
5.批量读写
Kafka数据读写也是批量的而不是单条的。
除了利用底层的技术外,Kafka还在应用程序层面提供了一些手段来提升性能。最明显的就是使用批次。在向Kafka写入数据时,可以启用批次写入,这样可以避免在网络上频繁传输单个消息带来的延迟和带宽开销。假设网络带宽为10MB/S,一次性传输10MB的消息比传输1KB的消息10000万次显然要快得多。
6.批量压缩
在很多情况下,系统的瓶颈不是CPU或磁盘,而是网络IO,对于需要在广域网上的数据中心之间发送消息的数据流水线尤其如此。进行数据压缩会消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑。
- 如果每个消息都压缩,但是压缩率相对很低,所以Kafka使用了批量压缩,即将多个消息一起压缩而不是单个消息压缩
- Kafka允许使用递归的消息集合,批量的消息可以通过压缩的形式传输并且在日志中也可以保持压缩格式,直到被消费者解压缩
- Kafka支持多种压缩协议,包括Gzip和Snappy压缩协议
Kafka速度的秘诀在于,它把所有的消息都变成一个批量的文件,并且进行合理的批量压缩,减少网络IO损耗,通过mmap提高I/O速度,写入数据的时候由于单个Partion是末尾添加所以速度最优;读取数据的时候配合sendfile直接暴力输出。
19.kafka如何保证消息的有序性
1. 消息有序性
我们需要从2个方面看待消息有序性
- 第一,发送端能否保证发送到服务器的消息是有序的
- 第二,接收端能否有序的消费服务器中的数据
发送端一般通过同步发送实现,即一次仅发送一条,等返回成功后,再发送下一条,接收端一般仅通过一个消费者参与消费实现
2. 发送端消息有序性
2.1 Kafka如何保证单partition有序?
**Kafka分布式的单位是partition,同一个partition用一个write ahead log组织,所以可以保证FIFO的顺序。不同partition之间不能保证顺序。**但是绝大多数用户都可以通过message key来定义,因为同一个key的message可以保证只发送到同一个partition,比如说key是user id,table row id等等,所以同一个user或者同一个record的消息永远只会发送到同一个partition上,保证了同一个user或record的顺序。
也就说通过队列,保证partition上的数据元素是有序的。通过设置相同的路由,让多个数据被路由到同一个partition即可。
2.2 client消息发送原理
下面,我们要如何保证数据从client发送到服务器上的partition是有序的?
先阅读 深入图解Kafka producer 发送过程
消息发送对于用户线程有同步和异步之分
同步能保证逐条发送消息,并保证是有序的
异步通常也是有序的,因为tcp长连接方式 按序读取InFlightRequests队列并发送至服务器上,tcp保证是有序的。但是如果开启了重试机制,可能会导致乱序。
后台的发送线程只有异步方式
异步场景下开启重试策略时:
max.in.flight.requests.per.connection=5 默认值,控制发送窗口的大小,即连续发送次数
如果把 retries 设为非零整数,同时把 max.in.flight.requests.per.connection 设为比 1 大的数,那么,如果第一个批次消息写入失败,而第二个批次写入成功,broker 会重试写入第一个批次。如果此时第一个批次也写入成功,那么两个批次的顺序就反过来了。
如果发送端配置了重试机制,kafka不会等之前那条消息完全发送成功才去发送下一条消息,这样可能会出现,发送了1,2,3条消息,第一条超时了,后面两条发送成功,再重试发送第1条消息,这时消息在broker端的顺序就是2,3,1了
一般来说,如果某些场景要求消息是有序的,那么消息是否写入成功也是很关键的,所以不建议把retries设为 0。可以把 max.in.flight.requests.per.connection 设为 1,这样在生产者尝试发送第一批消息时,就不会有其他的消息发送给broker。不过这样会严重影响生产者的吞吐量,所以只有在对消息的顺序有严格要求的情况下才能这么做。
3. 接收端消息有序性
kafka保证全链路消息顺序消费,需要从发送端开始,将所有有序消息发送到同一个分区,然后用一个消费者去消费,但是这种性能比较低,可以在消费者端接收到消息后将需要保证顺序消费的几条消费发到内存队列(可以搞多个) ,一个内存队列开启一个线程顺序处理消息。
仅有一个消费者访问一个分区,可以保证有序,但是效率低。当有多个消费者时,通过新增业务队列,让所有数据都发到业务队列中,排序后再进行业务处理.
20.kafka幂等和 什么时候提交
21. BIO,NIO,AIO 有什么区别?
BIO同步阻塞,传统并发处理能力低
NIO 同步非阻塞,客户端和服务器通过Channel通讯实现了多路复用
AIO Asynchronized 实现了异步非堵塞IO,基于事件和回调机制
22.类的加载过程
当Java程序需要使用某个类时,如果该类还未被加载到内存中,JVM会通过加载、连接(验证、准备和解析)、初始化三个步骤来对该类进行初始化。
类的加载是指把类的.class文件中的数据读入到内存中,通常是创建一个字节数组读入.class文件,然后产生与所加载类对应的Class对象。加载完成后,Class对象还不完整,所以此时的类还不可用。当类被加载后就进入连接阶段,这一阶段包括验证、准备(为静态变量分配内存并设置默认的初始值)和解析(将符号引用替换为直接引用)三个步骤。最后JVM对类进行初始化,包括:
1)如果类存在直接的父类并且这个类还没有被初始化,那么就先初始化父类;
2)如果类中存在初始化语句,就依次执行这些初始化语句。
23.静态代码和构造方法的执行顺序
静态代码先执行,随着类的加载进行执行
构造方法在对象创建的时候执行
24.双亲委派机制的作用
24.1、什么是双亲委派机制
当某个类加载器需要加载某个.class文件时,它首先把这个请求任务委托给它的上级类加载器,递归这个操作,如果上级类加载器都没有加载,自己才会去加载这个类。
24.2、作用:
1、防止重复加载同一个.class文件。通过委托去向上面问一问,加载过了,就不用再加载一遍了,保证数据安全。
2、保证核心 .class文件 不被篡改。通过向上委托的方式,不会去篡改核心 .class 文件,即使篡改也不会去加载,即使加载也不会是同一个 .class对象 。不同的类加载器加载同一个.class也不是同一个Class对象。这样保证了Class执行安全。
自己写个String类不会被加载,因为被篡改了
25.springCloud的五大组件都有什么
注册中心,网关,熔断器,配置中心,负载均衡,远程调用
25.1gateway网关都用来做什么
过滤器,对请求或者响应进行拦截,完成一些通用操作
- 请求接入
作为所有API接口服务请求的接入点
- 业务聚合
作为所有后端业务服务的聚合点
- 中介策略
实现安全,验证,路由,过滤,流控等策略
- 统一管理
对所有API服务和策略进行统一管理
25.2Hystrix哪个注解进行熔断或者降级的
//@HystrixCommand默认开启线程池隔离方式(不同线程池),服务降级(默认开启服务降级执行方法)、服务熔断;
//fallbackMethod:服务降级执行
@HystrixCommand(fallbackMethod = "getOrderHystrixFallBack")


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
类加载器都没有加载,自己才会去加载这个类。
### 24.2、作用:
1、防止重复加载同一个.class文件。通过委托去向上面问一问,加载过了,就不用再加载一遍了,保证数据安全。
2、保证核心 .class文件 不被篡改。通过向上委托的方式,不会去篡改核心 .class 文件,即使篡改也不会去加载,即使加载也不会是同一个 .class对象 。不同的类加载器加载同一个.class也不是同一个Class对象。这样保证了Class执行安全。
自己写个String类不会被加载,因为被篡改了
## 25.springCloud的五大组件都有什么
注册中心,网关,熔断器,配置中心,负载均衡,远程调用
### 25.1gateway网关都用来做什么
过滤器,对请求或者响应进行拦截,完成一些通用操作
* 请求接入
作为所有API接口服务请求的接入点
* 业务聚合
作为所有后端业务服务的聚合点
* 中介策略
实现安全,验证,路由,过滤,流控等策略
* 统一管理
对所有API服务和策略进行统一管理
### 25.2Hystrix哪个注解进行熔断或者降级的
//@HystrixCommand默认开启线程池隔离方式(不同线程池),服务降级(默认开启服务降级执行方法)、服务熔断;
//fallbackMethod:服务降级执行
@HystrixCommand(fallbackMethod = “getOrderHystrixFallBack”)
[外链图片转存中…(img-jZLH6Duo-1715103667169)]
[外链图片转存中…(img-Nppxyag4-1715103667169)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2354
2354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









