








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
过了一段时间后由于上游的发送速率要大于下游的接受速率,下游的 TaskManager 的 Buffer 已经到达了申请上限,这时候下游就会向上游返回 Credit = 0,ResultSubPartition 接收到之后就不会向 Netty 去传输数据,上游 TaskManager 的 Buffer 也很快耗尽,达到反压的效果,这样在 ResultSubPartition 层就能感知到反压,不用通过 Socket 和 Netty 一层层地向上反馈,降低了反压生效的延迟。同时也不会将 Socket 去阻塞,解决了由于一个 Task 反压导致 TaskManager 和 TaskManager 之间的 Socket 阻塞的问题。
总结:
- 网络流控是为了在上下游速度不匹配的情况下,防止下游出现过载。
2. 网络流控有静态限速和动态反压两种手段
3. Flink 1.5 之前是基于 TCP 流控 + bounded buffer 实现反压
4. Flink 1.5 之后实现了自己托管的 credit – based 流控机制,在应用层模拟 TCP 的流控机制
是否有了动态反压,静态限速就没用了?不是的。实际上动态反压不是万能的,我们流计算的结果最终是要输出到一个外部的存储(Storage),外部数据存储到 Sink 端的反压是不一定会触发的,这要取决于外部存储的实现,像 Kafka 这样是实现了限流限速的消息中间件可以通过协议将反压反馈给 Sink 端,但是像 ES 无法将反压进行传播反馈给 Sink 端,这种情况下为了防止外部存储在大的数据量下被打爆,我们就可以通过静态限速的方式在 Source 端去做限流。所以说动态反压并不能完全替代静态限速的,需要根据合适的场景去选择处理方案。
反压影响
反压并不会直接影响作业的可用性,它表明作业处于亚健康的状态,有潜在的性能瓶颈并可能导致更大的数据处理延迟。通常来说,对于一些对延迟要求不高或者数据量较少的应用,反压的影响可能并不明显。然而对于规模比较大的 Flink 作业,反压可能会导致严重的问题。
反压会影响checkpoint
(1)checkpoint时长:checkpoint barrier跟随普通数据流动,如果数据处理被阻塞,使得checkpoint barrier流经整个数据管道的时长变长,导致checkpoint 总体时间变长。
(2)state大小:为保证Exactly-Once准确一次,对于有两个以上输入管道的 Operator,checkpoint barrier需要对齐,即接受到较快的输入管道的barrier后,它后面数据会被缓存起来但不处理,直到较慢的输入管道的barrier也到达。这些被缓存的数据会被放到state 里面,导致checkpoint变大。
checkpoint是保证准确一次的关键,checkpoint时间变长有可能导致checkpoint超时失败,而state大小可能拖慢checkpoint甚至导致OOM。
反压监控
- flink web ui自带反压监控
该页面提供了 SubTask 级别的反压监控,1.13 版本以前是通过周期性对 Task 线程的栈信息采样,得到线程被阻塞在请求 Buffer(意味着被下游队列阻塞)的频率来判断该节点是否处于反压状态。Flink 1.13 优化了反压检测的逻辑(使用基于任务 Mailbox 计时,而不在再于堆栈采 样),并且重新实现了作业图的 UI 展示:Flink 现在在 UI 上通过颜色和数值来展示繁忙和反压的程度。黑色表示反压严重,红色表示非常繁忙,蓝色表示比较空闲。Backpressure Status值有OK/LOW/HIGH。
OK: 0% <= back pressured <= 10%
LOW: 10% < back pressured <= 50%
HIGH: 50% < back pressured <= 100%
假如通过web ui 查看到某个算子处于反压状态,可以分析该算子瓶颈:
如果处于反压状态,那么有两种可能性:
(1)该节点的发送速率跟不上它的产生数据速率。这一般会发生在一条输入多条输出的 Operator(比如 flatmap)。这种情况,该节点是反压的根源节点,它是从 Source Task 到 Sink Task 的第一个出现反压的节点。
(2)下游的节点接受速率较慢,通过反压机制限制了该节点的发送速率。这种情况, 需要继续排查下游节点,一直找到第一个为 OK 的一般就是根源节点。 总体来看,如果我们找到第一个出现反压的节点,反压根源要么是就这个节点,要么是 它紧接着的下游节点。 通常来讲,第二种情况更常见。如果无法确定,还需要结合 Metrics 进一步判断。
2. 利用 Metrics 定位
监控反压时会用到的 Metrics 主要和 Channel 接受端的 Buffer 使用率有关,最为有用的是以下几个 Metrics:
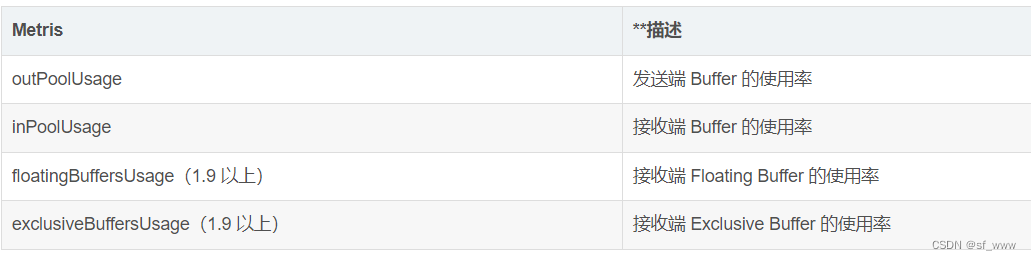
inPoolUsage = floatingBuffersUsage + exclusiveBuffersUsage。
(1)采用 Metrics 分析反压的思路
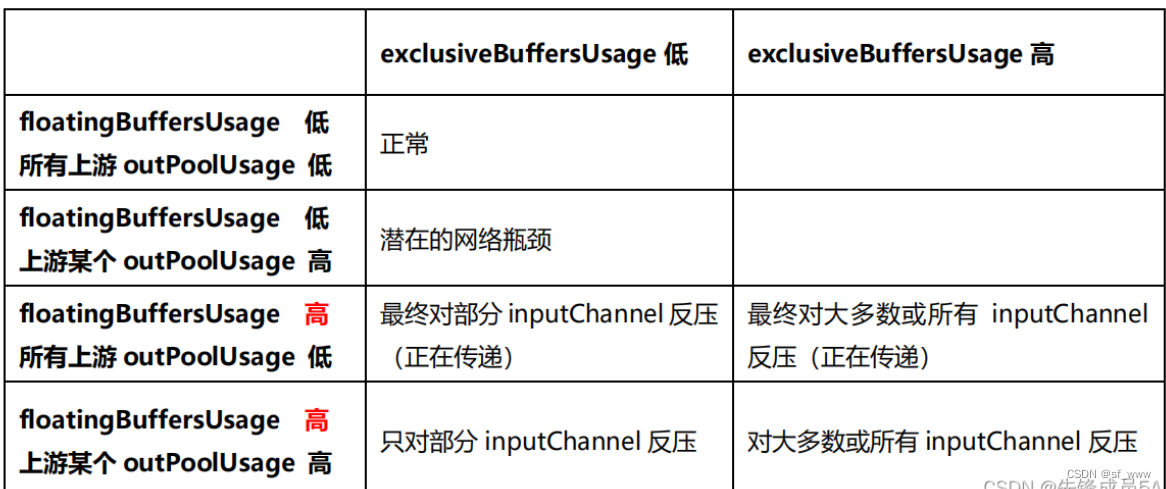
如果一个 Subtask 的发送端 Buffer 占用率很高,则表明它 被下游反压限速了;如果一个 Subtask 的接受端 Buffer 占用很高,则表明它将反压传导至上游。

(2)将inPoolUsage分为floatingBuffersUsage + exclusiveBuffersUsage进一步分析
Flink 1.9及以上版本,还可以根据 floatingBuffersUsage/exclusiveBuffersUsage 以 及其上游 Task 的 outPoolUsage 来进行进一步的分析一个 Subtask 和其上游 Subtask 的数据传输。
在流量较大时,Channel 的 Exclusive Buffer 可能会被写满,此时 Flink 会向 Buffer Pool 申请剩余的 Floating Buffer。这些 Floating Buffer 属于备用 Buffer。
解析:
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**















 3181
3181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









