







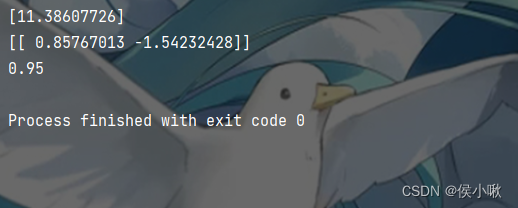
第三步,训练模型
logistic = LogisticRegression()
logistic.fit(x_data, y_data)
# 截距
print(logistic.intercept_)
# 系数:theta1 theta2
print(logistic.coef_)
# 预测
pred = logistic.predict(x_data)
# 输出评分
score = logistic.score(x_data, y_data)
print(score)
输出结果如下图所示:
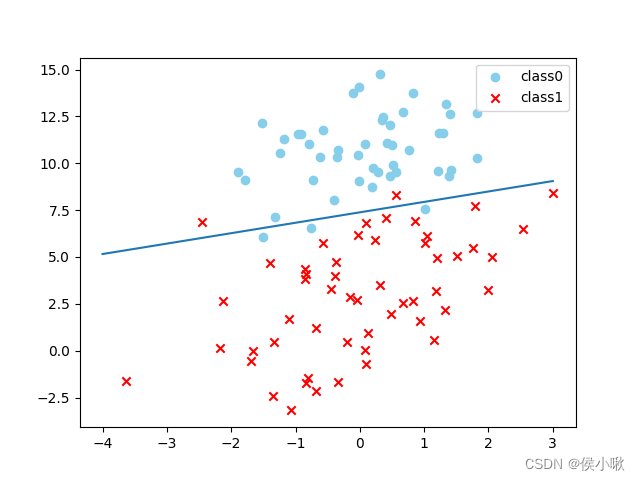
绘制出带有决策边界的散点图:
# 绘制散点
plot_logi()
# 绘制决策边界
x_test = np.array([[-4], [3]])
y_test = -(x_test\*logistic.coef_[0, 0]+logistic.intercept_)/logistic.coef_[0, 1]
plt.plot(x_test, y_test)
plt.show()
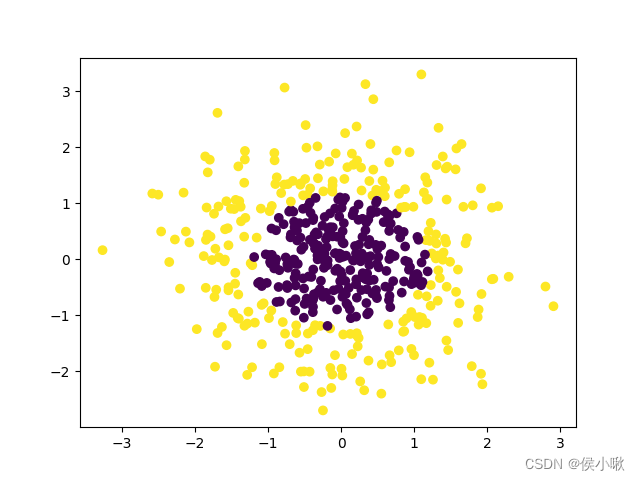
2.非线性逻辑回归
python实现非线性逻辑回归,首先使用make_gaussian_quantiles获取一组高斯分布的数据集,代码及数据分布如下:
import matplotlib.pyplot as plt
from sklearn import linear_model
from sklearn.preprocessing import PolynomialFeatures
from sklearn.datasets import make_gaussian_quantiles
# 获取高斯分布的数据集,500个样本,2个特征,2分类
x_data, y_data = make_gaussian_quantiles(n_samples=500, n_features=2, n_classes=2)
# 绘制散点图
plt.scatter(x_data[:, 0], x_data[:, 1],c=y_data)
plt.show()
描述数据分布的散点图如图所示:
然后转换数据并训练模型以实现非线性逻辑回归:
# 数据转换,最高次项为五次项
poly_reg = PolynomialFeatures(degree=5)
x_poly = poly_reg.fit_transform(x_data)
# 定义逻辑回归模型
logistic = linear_model.LogisticRegression()
logistic.fit(x_poly, y_data)
score = logistic.score(x_poly, y_data)
print(score)
评分结果如图所示,达0.996:

3.乳腺癌数据集案例
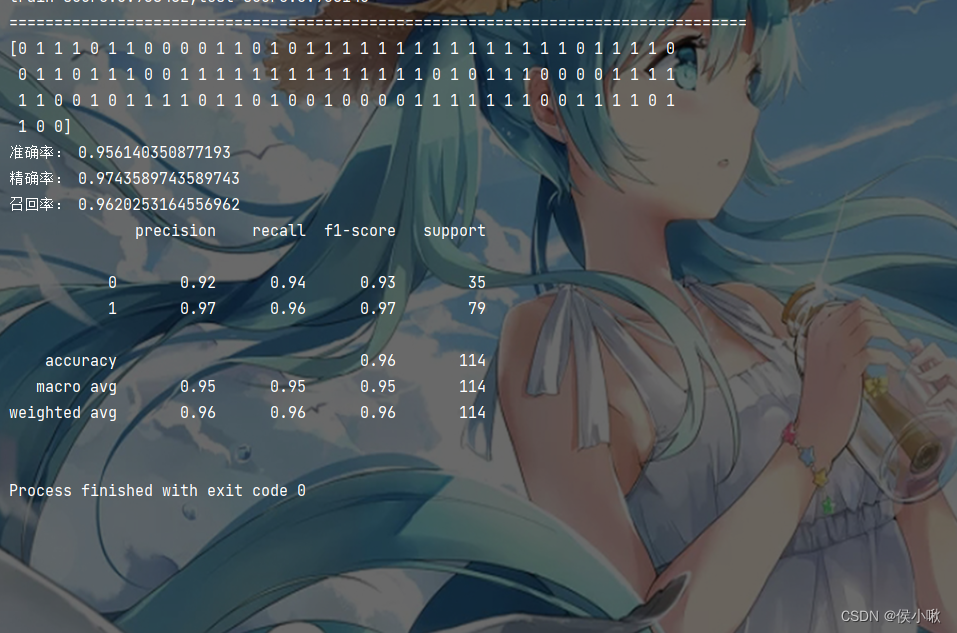
以乳腺癌数据集为例,建立线性逻辑回归模型,并输出准确率,精确率,召回率三大指标,代码如下所示:
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings("ignore")
# 获取数据
cancer = load_breast_cancer()
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2)
# 创建估计器
model = LogisticRegression()
# 训练
model.fit(X_train, y_train)
# 训练集准确率
train_score = model.score(X_train, y_train)
# 测试集准确率
test_score = model.score(X_test, y_test)
print('train score:{train\_score:.6f};test score:{test\_score:.6f}'.format(train_score=train_score, test_score=test_score))
print("==================================================================================")
# 再对X\_test进行预测
y_pred = model.predict(X_test)
print(y_pred)
# 准确率 所有的判断中有多少判断正确的
accuracy_score_value = accuracy_score(y_test, y_pred)
# 精确率 预测为正的样本中有多少是对的
precision_score_value = precision_score(y_test, y_pred)
# 召回率 样本中有多少正样本被预测正确了
recall_score_value = recall_score(y_test, y_pred)
print("准确率:", accuracy_score_value)
print("精确率:", precision_score_value)
print("召回率:", recall_score_value)
# 输出报告模型评估报告
classification_report_value = classification_report(y_test, y_pred)
print(classification_report_value)
程序输出结果如下图所示:
本次分享就到这里,小啾感谢您的关注与支持!
🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ
本专栏更多好文欢迎点击下方连接:
1.初识机器学习前导内容_你需要知道的基本概念罗列_以PY为工具 【Python机器学习系列(一)】
2.sklearn库数据标准预处理合集_【Python机器学习系列(二)】
3.K_近邻算法_分类Ionosphere电离层数据【python机器学习系列(三)】
4.python机器学习 一元线性回归 梯度下降法的实现 【Python机器学习系列(四)】

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 4794
4794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









