







今天这篇文章主要是记录下自己在学习逻辑回归算法过程中自己的一些体会,这里我主要从公式推导和代码实现来展开。
前面我们学习过最简单的线性回归,它针对的是标签值为连续的机器学习任务,不懂的可以 参考这篇文章:Python实现简单的线性回归
而逻辑回归针对的是标签为0 / 1 的二分类问题,根据现有数据对分类边界线建立回归公式,然后将标签为1和标签为0的划分开来。
简单的来理解的话可以看下面这句话:
为了实现Logistic回归分类器,我们可以在每个特征上都乘以一个回归系数,然后把所有的结果值相加,将这个总和带入Sigmoid函数中,进而得到一个范围在0~1之间的数值。任何大于
0.5的数据被分入1类,小于0.5即归为0类。所以Logistic回归也可以被看成是一种概率估计。
那么问题来了,我们该如何寻找这个最佳回归系数呢,这也是我们接下来要讲的,这里我们先通过公式推导下来一步步理解如何寻求最佳回归系数。
我们知道,概率是属于[0,1]区间。但是线性模型 ![]() 值域是
值域是![]() 。
。
为了将线性模型的值域限制在[0,1]我们需要找到一个模型的值域刚好在[0,1]区间,同时要足够好用。于是,选择了我们的sigmoid函数。
它的表达式为:

图像如下所示:
现在我们需要将线性模型与sigmoid结合起来,于是就变成了我们的逻辑回归模型:
假设我们已经训练好了一组权值![]() 。只要把我们需要预测的
。只要把我们需要预测的 ![]() 代入到上面的方程,输出的y值就是这个标签为A的概率,我们就能够判断输入数据是属于哪个类别。
代入到上面的方程,输出的y值就是这个标签为A的概率,我们就能够判断输入数据是属于哪个类别。
但是上面我们讲了一大堆也就是找到了逻辑回归模型,我们之前不是说的要找一个最佳回归系数?不要急,我们接下来就来找
举个例子:假设只有两个标签1和0,![]() 。我们把采集到的任何一组样本看做一个事件的话,那么这个事件发生的概率假设为p。
。我们把采集到的任何一组样本看做一个事件的话,那么这个事件发生的概率假设为p。
我们的模型y的值等于标签为1的概率也就是p,
因为标签不是1就是0,因此标签为0的概率就是:![]()
我们把单个样本看做一个事件,那么这个事件发生的概率就是:
这个函数不方便计算,它等价于:![]()
上面这个式子你一下子可能还理解不过来,这里我们来解释下:我们采集了一个样本![]() ,这个样本的标签为
,这个样本的标签为![]() 的概率为
的概率为![]()
比如我们取y = 0 ,概率为(1 - p) ,取y = 1,概率为p
但是,如果我们采集到了一组数据一共N个,![]()
这个组合在一起的合事件发生的总概率怎么求呢?其实就是将每一个样本发生的概率相乘就可以了,即采集到这组样本的概率:
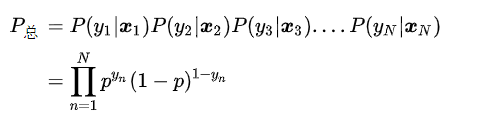
注意![]() 是一个函数,并且未知的量只有
是一个函数,并且未知的量只有 ![]() (在p里面),可以看下这个
(在p里面),可以看下这个
对于这种连乘看起来不是很直观我们对两边直接取对数:

为了使某个样本最大概率的被正确分配到标签中,所以我们要最大化![]() ,那我们该如何最大化呢,这里我们需要引入最大似然估计(MLE)
,那我们该如何最大化呢,这里我们需要引入最大似然估计(MLE)
什么是最大似然估计,这里我借用网上总结的一句话:利用已知的样本信息,反推最大概率导致这些样本结果出现的模型参数值
具体的可以参考这篇文章:一文搞懂极大似然估计
所以,我们此时就问题就转化成了需要对![]() 求极大值了,接下来我们就需要求导了。
求极大值了,接下来我们就需要求导了。
已知 ,那么
,那么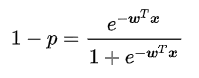
p是一个关于变量 ![]() 的函数,我们对p求导,通过链式求导法则,慢慢展开可以得:
的函数,我们对p求导,通过链式求导法则,慢慢展开可以得:
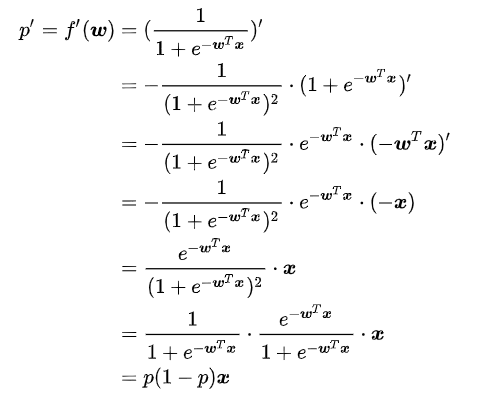
同理我们也可以相应的求出:![]()
到了这一步我们可以对![]() 开始求偏导了
开始求偏导了

整理下公式:
这样我们通过求偏导找到了dw(dw等价于上面的![]() ),然后通过梯度上升的方法就可以找到最佳回归系数:w = w + lr * dw
),然后通过梯度上升的方法就可以找到最佳回归系数:w = w + lr * dw
好了,完成上面的一系列公式推导,接下来我们开始编码实现一个简单的逻辑回归。
准备数据集:data.txt
数据集的个数如下所示(这里只展示一部分):

接下来我们将这些数据图形化看看他们在坐标轴上的分布:

显示数据集的分布代码如下所示:
import numpy as np
import matplotlib.pyplot as plt
# 读取数据
fr = open('data.txt')
# 原始数据集
dataMat = []
# readlines() 方法用于读取所有行(直到结束符 EOF)并返回列表
for line in fr.readlines():
# strip()表示删除掉数据中的换行符,split()则是数据中遇到空格就隔开。
lineArr = line.strip().split() # 读取每一行数据
# dataMat.append(lineArr) # 将每一行数据添加到dataMat中
# 为了方便计算,我们将 X0 的值设为 1.0 ,也就是在每一行的开头添加一个 1.0 作为 X0
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
data = np.array(dataMat)
x = data[:,1]
print(x)
y = data[:,2]
color = ['r','y']
plt.scatter(x, y,color=color)
plt.show()这里有个小问题就是在显示数据的时候如果将上面代码替换如下所示的
dataMat.append(lineArr) # 将每一行数据添加到dataMat中
# 为了方便计算,我们将 X0 的值设为 1.0 ,也就是在每一行的开头添加一个 1.0 作为 X0
#dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])运行结果如下所示:

显示数据分布的样子就成了这样,我猜应该可能是我们的数据集的第0列因为数据存在正负数导致的,具体为什么我也不清楚,然后网上提供一种方法就是下面这样的:
# 为了方便计算,我们将 X0 的值设为 1.0 ,也就是在每一行的开头添加一个 1.0 作为 X0
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])恩恩,鄙人太菜了,暂时无法解释,如果有小伙伴知道的话麻烦解释下。
言归正传,接下来就是我们编写代码,如何将上面的数据集正确分类了。代码如下所示:
import numpy as np
import matplotlib.pyplot as plt
# 加载数据
def loadData(filename):
"""
:param filename: 文件路径名
:return:
"""
# 读取数据
fr = open(filename)
# 原始数据集
dataMat = []
# 标签数据集
lableMat = []
# readlines() 方法用于读取所有行(直到结束符 EOF)并返回列表
for line in fr.readlines():
# strip()表示删除掉数据中的换行符,split()则是数据中遇到空格就隔开。
lineArr = line.strip().split() # 读取每一行数据
# dataMat.append(lineArr) # 将每一行数据添加到dataMat中
# 为了方便计算,我们将 X0 的值设为 1.0 ,也就是在每一行的开头添加一个 1.0 作为 X0
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
lableMat.append(int(lineArr[2])) # 将每一行的标签添加到lableMat中
return dataMat,lableMat
# 定义sigmoid函数(相当于一个分类函数)
def sigmoid(x):
"""
:param x: 函数变量
:return: 返回函数值z
"""
z = 1 / (1 + np.exp(-x))
return z
# 梯度上升
def gradAscent(dataMat,classLables):
"""
:param dataMat: 数据集
:param classLables: 标签集
"""
# 将数组转化为矩阵
dataMarix = np.mat(dataMat) # (100,3)
# 将行向量转为列向量
lableMat = np.mat(classLables).transpose()
# m = 100 , n = 3
m,n = np.shape(dataMarix)
# 设置目标移动的步长(换个角度理解也就是设置学习率)
lr = 0.001
# 设置迭代次数
epoch = 500
# 设置初始的参数,并都赋默认值为1(生成一个长度和特征数相同的矩阵,此处n为3 -> [[1],[1],[1]])
w = np.ones((n,1))
for k in range(epoch):
h = sigmoid(dataMarix * w) # dataMarix * w : (100,3) * (3,1) = (100,1)
# 真实值与预测值之间的差值
loss = lableMat - h
# 迭代更新回归系数w
w += lr * dataMarix.transpose() * loss # w : (3,1)
return w
# 展示结果
def show(data,lable,w):
"""
:param data: 数据集
:param lable: 标签集
:param w: 回归系数
"""
# 获取样本总数
n = len(data)
# 定义列表用来存储每个点的横纵坐标
x1 = []
y1 = []
x2 = []
y2 = []
# 迭代将同一类别的标签归为一类(0和1)
for i in range(n):
if lable[i] == 1 :
x1.append(data[i,1])
y1.append(data[i,2])
else:
x2.append(data[i,1])
y2.append(data[i,2])
# 绘图
plt.scatter(x1, y1, s=30, c='blue', marker='s')
plt.scatter(x2, y2, s=30, c='green')
# 画拟合曲线
x = np.arange(-3,3,0.1) # 这里主要是根据我们的数据集来自定义横轴刻度
y = -(w[0] + w[1] * x) / w[2] # y变量主要根据 z = w0x0 + w1x1 + w2x2 推导出来的
plt.plot(x,y)
plt.show()
if __name__ == '__main__':
data,lable = loadData('data.txt')
w = gradAscent(data,lable)
show(np.mat(data),lable,w)运行结果如下:

这里我们可以清晰的看到通过上面的代码我们将数据分为两类了,但是这里有个问题就是我们绘制图形的时候图中那条蓝色的直线是怎么来的,当时我也有这个疑问,通过网上的一些资料我大概的回答下。
首先我们要知道我们的线性模型![]() ,通过sigmoid函数结合
,通过sigmoid函数结合
生成的是一个预测标签的概率,通过这个概率我们可以将其判定为是否为标签1或者标签0,但是对于sigmoid函数来说,x = 0 ,y = 0.5

这里我们假设概率大于等于0.5归为标签1 小于0.5归为标签0,所以我们这里就是以 sigmoid函数中z = 0为·分界线进行分类的,而这个z恰好就是我们
z = sum(各回归系数*各特征) 进而问题就转化为 W0X0+W1X1+W2X2 = 0
其中X0表示的是我们自己设置的第0列特征值:1
X1表示的是第一列特征值:x
X2表示的是第二列特征值:y
综上,我们的要求的y继而可以推导出来:y = (-W[0] - W[1] * x) / W[2]
而W就是我们要求的最佳回归系数,在代码中我们通过梯度上升法已经求得。
如果大家还是不太理解可以参考这篇文章:数据挖掘经典算法:Logistic(逻辑回归) python和sklearn实现
【问题二】

对于这段代码的理解,其实就相当于我们公式推导的结果
我们通过迭代不断去更新w,然后求得一个最佳的回归系数。
以上就是我个人对逻辑回归的一个简单理解,至于后续深入学习有什么好想法会在后面更新出来。


















 1320
1320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









